 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Adam and Training Strategies Help BNNs Optimization?
Jun 21, 2021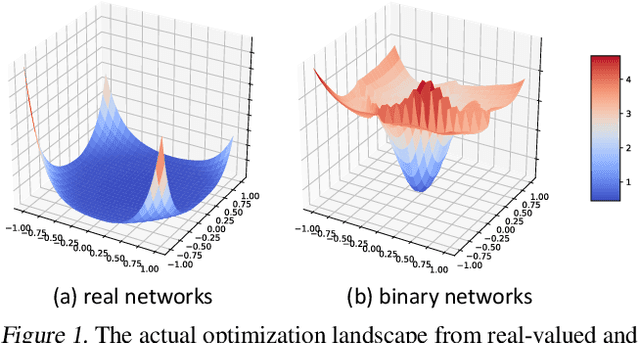


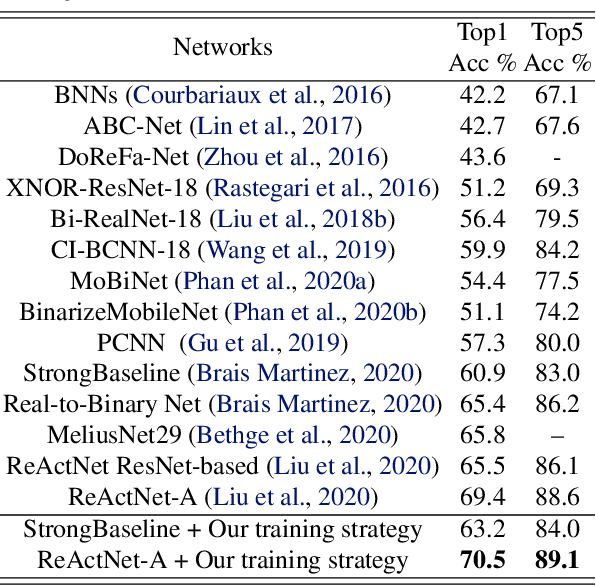
The best performing Binary Neural Networks (BNNs) are usually attained using Adam optimization and its multi-step training variants. However, to the best of our knowledge, few studies explore the fundamental reasons why Adam is superior to other optimizers like SGD for BNN optimization or provide analytical explanations that support specific training strategies. To address this, in this paper we first investigate the trajectories of gradients and weights in BNNs during the training process. We show the regularization effect of second-order momentum in Adam is crucial to revitalize the weights that are dead due to the activation saturation in BNNs. We find that Adam, through its adaptive learning rate strategy, is better equipped to handle the rugged loss surface of BNNs and reaches a better optimum with higher generalization ability. Furthermore, we inspect the intriguing role of the real-valued weights in binary networks, and reveal the effect of weight decay on the stability and sluggishness of BNN optimization. Through extensive experiments and analysis, we derive a simple training scheme, building on existing Adam-based optimization, which achieves 70.5% top-1 accuracy on the ImageNet dataset using the same architecture as the state-of-the-art ReActNet while achieving 1.1% higher accuracy. Code and models are available at https://github.com/liuzechun/AdamBNN.
Larq Compute Engine: Design, Benchmark, and Deploy State-of-the-Art Binarized Neural Networks
Nov 18, 2020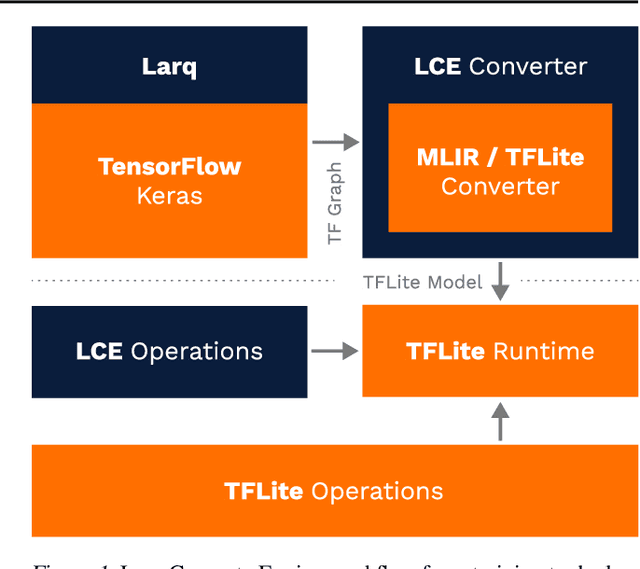
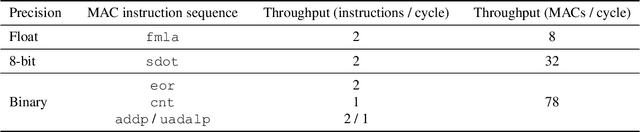
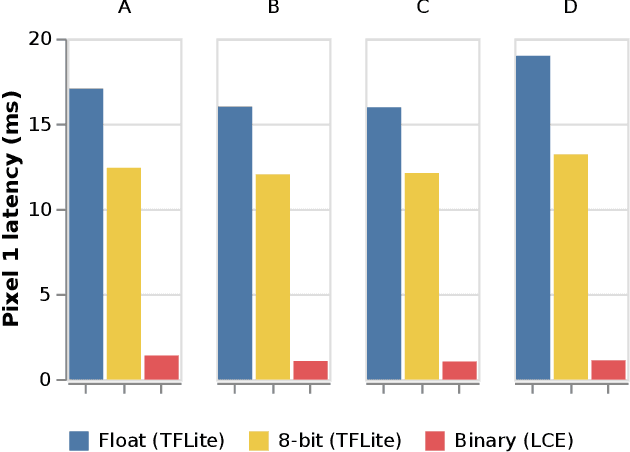

We introduce Larq Compute Engine, the world's fastest Binarized Neural Network (BNN) inference engine, and use this framework to investigate several important questions about the efficiency of BNNs and to design a new state-of-the-art BNN architecture. LCE provides highly optimized implementations of binary operations and accelerates binary convolutions by 8.5 - 18.5x compared to their full-precision counterparts on Pixel 1 phones. LCE's integration with Larq and a sophisticated MLIR-based converter allow users to move smoothly from training to deployment. By extending TensorFlow and TensorFlow Lite, LCE supports models which combine binary and full-precision layers, and can be easily integrated into existing applications. Using LCE, we analyze the performance of existing BNN computer vision architectures and develop QuickNet, a simple, easy-to-reproduce BNN that outperforms existing binary networks in terms of latency and accuracy on ImageNet. Furthermore, we investigate the impact of full-precision shortcuts and the relationship between number of MACs and model latency. We are convinced that empirical performance should drive BNN architecture design and hope this work will facilitate others to design, benchmark and deploy binary models.
Latent Weights Do Not Exist: Rethinking Binarized Neural Network Optimization
Jun 05, 2019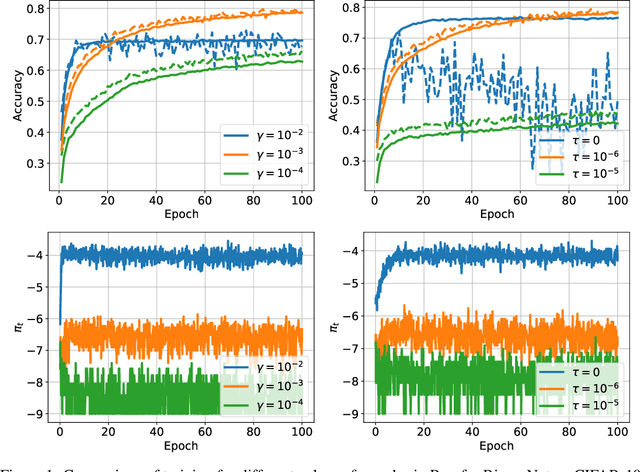
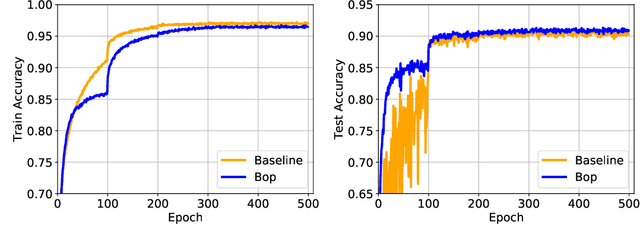
Optimization of Binarized Neural Networks (BNNs) currently relies on real-valued latent weights to accumulate small update steps. In this paper, we argue that these latent weights cannot be treated analogously to weights in real-valued networks. Instead their main role is to provide inertia during training. We interpret current methods in terms of inertia and provide novel insights into the optimization of BNNs. We subsequently introduce the first optimizer specifically designed for BNNs, Binary Optimizer (Bop), and demonstrate its performance on CIFAR-10 and ImageNet. Together, the redefinition of latent weights as inertia and the introduction of Bop enable a better understanding of BNN optimization and open up the way for further improvements in training methodologies for BNNs. Code is available at: https://github.com/plumerai/rethinking-bnn-optimization