 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarq Compute Engine: Design, Benchmark, and Deploy State-of-the-Art Binarized Neural Networks
Paper and Code
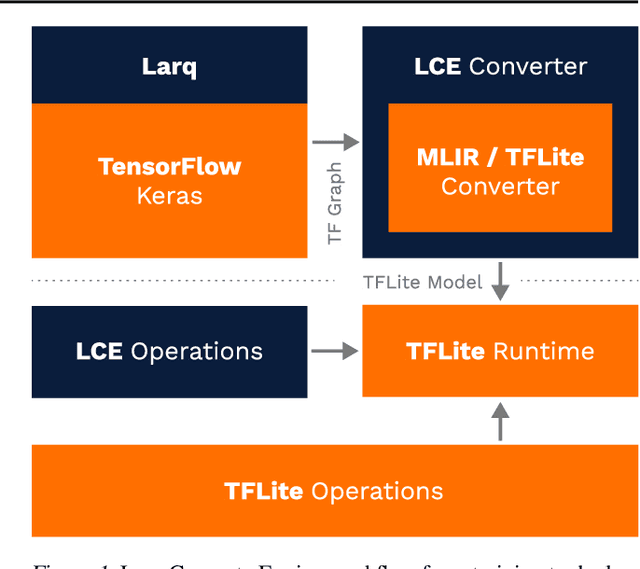
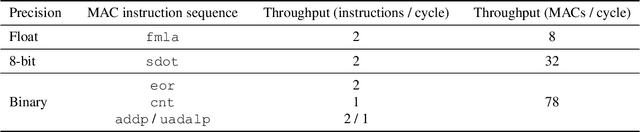
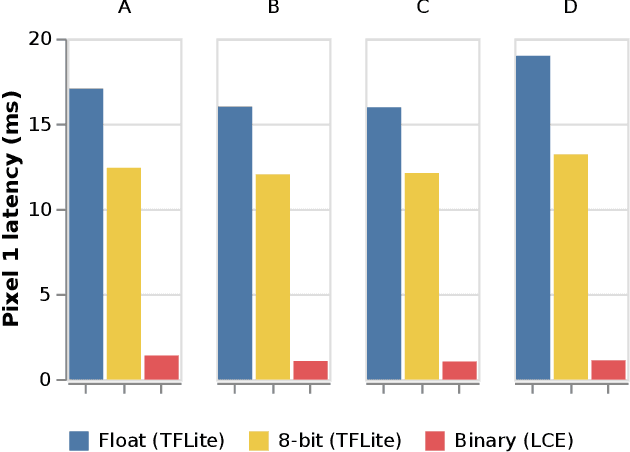

We introduce Larq Compute Engine, the world's fastest Binarized Neural Network (BNN) inference engine, and use this framework to investigate several important questions about the efficiency of BNNs and to design a new state-of-the-art BNN architecture. LCE provides highly optimized implementations of binary operations and accelerates binary convolutions by 8.5 - 18.5x compared to their full-precision counterparts on Pixel 1 phones. LCE's integration with Larq and a sophisticated MLIR-based converter allow users to move smoothly from training to deployment. By extending TensorFlow and TensorFlow Lite, LCE supports models which combine binary and full-precision layers, and can be easily integrated into existing applications. Using LCE, we analyze the performance of existing BNN computer vision architectures and develop QuickNet, a simple, easy-to-reproduce BNN that outperforms existing binary networks in terms of latency and accuracy on ImageNet. Furthermore, we investigate the impact of full-precision shortcuts and the relationship between number of MACs and model latency. We are convinced that empirical performance should drive BNN architecture design and hope this work will facilitate others to design, benchmark and deploy binary models.