 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Adam and Training Strategies Help BNNs Optimization?
Paper and Code
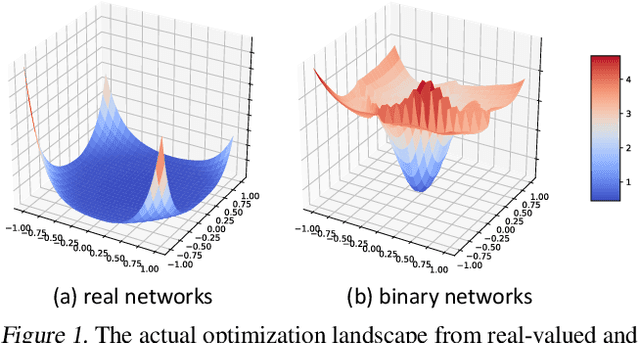


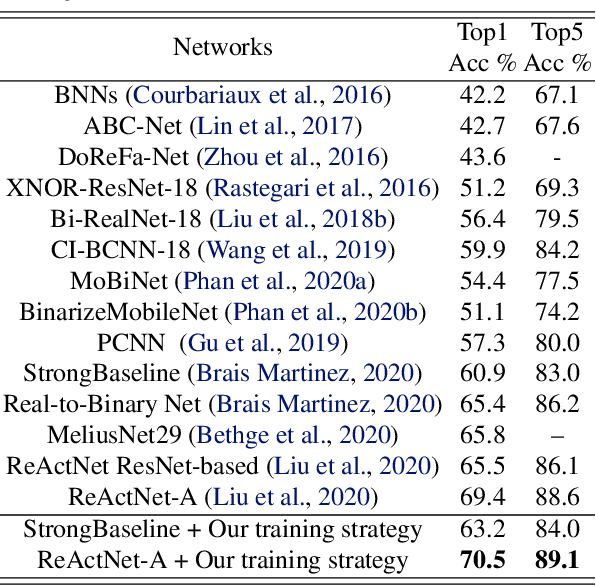
The best performing Binary Neural Networks (BNNs) are usually attained using Adam optimization and its multi-step training variants. However, to the best of our knowledge, few studies explore the fundamental reasons why Adam is superior to other optimizers like SGD for BNN optimization or provide analytical explanations that support specific training strategies. To address this, in this paper we first investigate the trajectories of gradients and weights in BNNs during the training process. We show the regularization effect of second-order momentum in Adam is crucial to revitalize the weights that are dead due to the activation saturation in BNNs. We find that Adam, through its adaptive learning rate strategy, is better equipped to handle the rugged loss surface of BNNs and reaches a better optimum with higher generalization ability. Furthermore, we inspect the intriguing role of the real-valued weights in binary networks, and reveal the effect of weight decay on the stability and sluggishness of BNN optimization. Through extensive experiments and analysis, we derive a simple training scheme, building on existing Adam-based optimization, which achieves 70.5% top-1 accuracy on the ImageNet dataset using the same architecture as the state-of-the-art ReActNet while achieving 1.1% higher accuracy. Code and models are available at https://github.com/liuzechun/AdamBNN.