 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIstGPT: LLM-based Anomaly Detection for Spatial-Temporal Graph in Industrial Systems
Jun 01, 2026Industrial Internet systems face increasing threats from sophisticated industrial control system (ICS) attacks, resulting in critical safety incidents. However, existing tools exhibit limited effectiveness in real-time anomaly detection due to the complex dependencies among sensors and actuators. To tackle this, we present IstGPT, the first industrial anomaly detection tool based on LLMs and graph learning to provide real-time protection against a wide range of ICS attacks. IstGPT achieves fine-grained and precise modeling on spatial-temporal dependencies in industrial cyber-physical systems. It first leverages industrial multi-modal knowledge, including operational data, technical documents, and system diagrams, to extract sensor-actuator dependency graphs via multi-stage prompt engineering. Then, LLM-Optimation iteratively refines the graph based on node accuracy, edge consistency, and logical coherence. Finally, IstGPT integrated improved graph neural networks with an encoder-decoder architecture to detect anomalies via reconstruction errors. We evaluate IstGPT against 12 state-of-the-art baselines on 9 datasets, including 2 public, 6 simulated, and a real-world robotic arm dataset. IstGPT achieves the best F1-scores and eTaF1 (a newer time-aware metric) across nine datasets. We further discuss the feasibility of deploying IstGPT in real-world industrial scenarios.
ThreatModeling-LLM: Automating Threat Modeling using Large Language Models for Banking System
Nov 26, 2024



Threat modeling is a crucial component of cybersecurity, particularly for industries such as banking, where the security of financial data is paramount. Traditional threat modeling approaches require expert intervention and manual effort, often leading to inefficiencies and human error. The advent of Large Language Models (LLMs) offers a promising avenue for automating these processes, enhancing both efficiency and efficacy. However, this transition is not straightforward due to three main challenges: (1) the lack of publicly available, domain-specific datasets, (2) the need for tailored models to handle complex banking system architectures, and (3) the requirement for real-time, adaptive mitigation strategies that align with compliance standards like NIST 800-53. In this paper, we introduce ThreatModeling-LLM, a novel and adaptable framework that automates threat modeling for banking systems using LLMs. ThreatModeling-LLM operates in three stages: 1) dataset creation, 2) prompt engineering and 3) model fine-tuning. We first generate a benchmark dataset using Microsoft Threat Modeling Tool (TMT). Then, we apply Chain of Thought (CoT) and Optimization by PROmpting (OPRO) on the pre-trained LLMs to optimize the initial prompt. Lastly, we fine-tune the LLM using Low-Rank Adaptation (LoRA) based on the benchmark dataset and the optimized prompt to improve the threat identification and mitigation generation capabilities of pre-trained LLMs.
EaTVul: ChatGPT-based Evasion Attack Against Software Vulnerability Detection
Jul 27, 2024



Recently, deep learning has demonstrated promising results in enhancing the accuracy of vulnerability detection and identifying vulnerabilities in software. However, these techniques are still vulnerable to attacks. Adversarial examples can exploit vulnerabilities within deep neural networks, posing a significant threat to system security. This study showcases the susceptibility of deep learning models to adversarial attacks, which can achieve 100% attack success rate (refer to Table 5). The proposed method, EaTVul, encompasses six stages: identification of important samples using support vector machines, identification of important features using the attention mechanism, generation of adversarial data based on these features using ChatGPT, preparation of an adversarial attack pool, selection of seed data using a fuzzy genetic algorithm, and the execution of an evasion attack. Extensive experiments demonstrate the effectiveness of EaTVul, achieving an attack success rate of more than 83% when the snippet size is greater than 2. Furthermore, in most cases with a snippet size of 4, EaTVul achieves a 100% attack success rate. The findings of this research emphasize the necessity of robust defenses against adversarial attacks in software vulnerability detection.
Progressive Training of Multi-level Wavelet Residual Networks for Image Denoising
Oct 23, 2020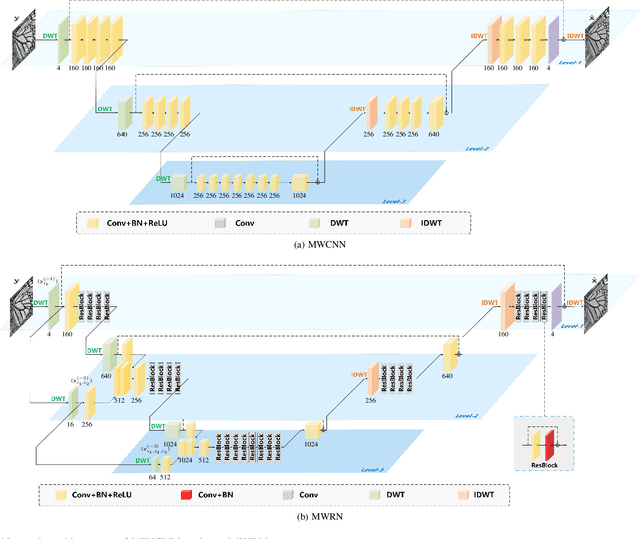
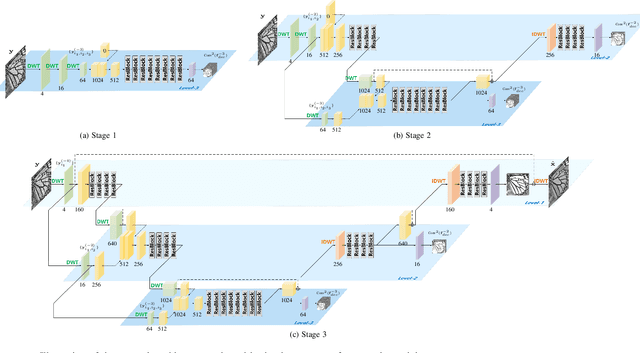


Recent years have witnessed the great success of deep convolutional neural networks (CNNs) in image denoising. Albeit deeper network and larger model capacity generally benefit performance, it remains a challenging practical issue to train a very deep image denoising network. Using multilevel wavelet-CNN (MWCNN) as an example, we empirically find that the denoising performance cannot be significantly improved by either increasing wavelet decomposition levels or increasing convolution layers within each level. To cope with this issue, this paper presents a multi-level wavelet residual network (MWRN) architecture as well as a progressive training (PTMWRN) scheme to improve image denoising performance. In contrast to MWCNN, our MWRN introduces several residual blocks after each level of discrete wavelet transform (DWT) and before inverse discrete wavelet transform (IDWT). For easing the training difficulty, scale-specific loss is applied to each level of MWRN by requiring the intermediate output to approximate the corresponding wavelet subbands of ground-truth clean image. To ensure the effectiveness of scale-specific loss, we also take the wavelet subbands of noisy image as the input to each scale of the encoder. Furthermore, progressive training scheme is adopted for better learning of MWRN by beigining with training the lowest level of MWRN and progressively training the upper levels to bring more fine details to denoising results. Experiments on both synthetic and real-world noisy images show that our PT-MWRN performs favorably against the state-of-the-art denoising methods in terms both quantitative metrics and visual quality.
DeFuzz: Deep Learning Guided Directed Fuzzing
Oct 23, 2020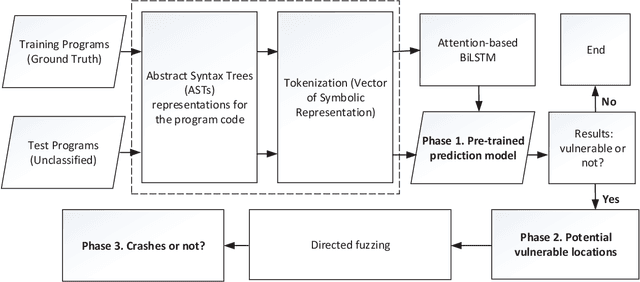

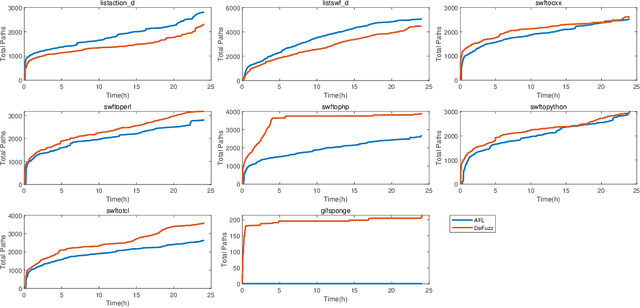
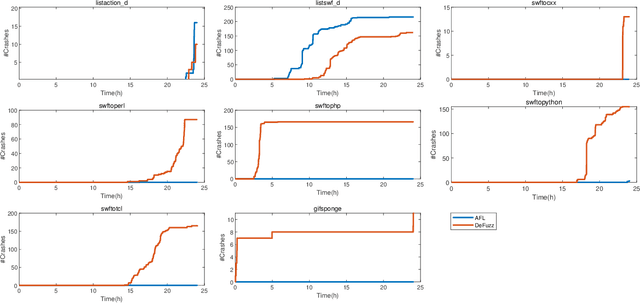
Fuzzing is one of the most effective technique to identify potential software vulnerabilities. Most of the fuzzers aim to improve the code coverage, and there is lack of directedness (e.g., fuzz the specified path in a software). In this paper, we proposed a deep learning (DL) guided directed fuzzing for software vulnerability detection, named DeFuzz. DeFuzz includes two main schemes: (1) we employ a pre-trained DL prediction model to identify the potentially vulnerable functions and the locations (i.e., vulnerable addresses). Precisely, we employ Bidirectional-LSTM (BiLSTM) to identify attention words, and the vulnerabilities are associated with these attention words in functions. (2) then we employ directly fuzzing to fuzz the potential vulnerabilities by generating inputs that tend to arrive the predicted locations. To evaluate the effectiveness and practical of the proposed DeFuzz technique, we have conducted experiments on real-world data sets. Experimental results show that our DeFuzz can discover coverage more and faster than AFL. Moreover, DeFuzz exposes 43 more bugs than AFL on real-world applications.
A Study of Data Pre-processing Techniques for Imbalanced Biomedical Data Classification
Nov 04, 2019
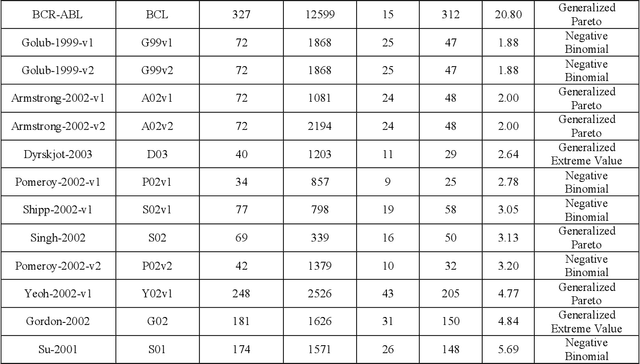

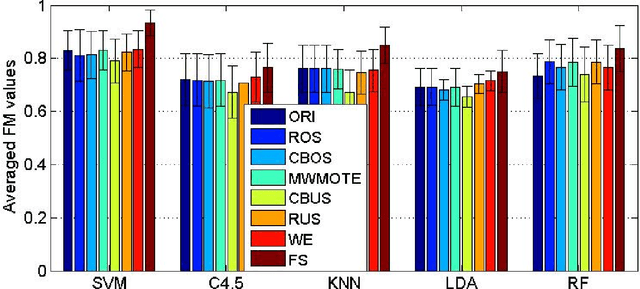
Biomedical data are widely accepted in developing prediction models for identifying a specific tumor, drug discovery and classification of human cancers. However, previous studies usually focused on different classifiers, and overlook the class imbalance problem in real-world biomedical datasets. There are a lack of studies on evaluation of data pre-processing techniques, such as resampling and feature selection, on imbalanced biomedical data learning. The relationship between data pre-processing techniques and the data distributions has never been analysed in previous studies. This article mainly focuses on reviewing and evaluating some popular and recently developed resampling and feature selection methods for class imbalance learning. We analyse the effectiveness of each technique from data distribution perspective. Extensive experiments have been done based on five classifiers, four performance measures, eight learning techniques across twenty real-world datasets. Experimental results show that: (1) resampling and feature selection techniques exhibit better performance using support vector machine (SVM) classifier. However, resampling and Feature Selection techniques perform poorly when using C4.5 decision tree and Linear discriminant analysis classifiers; (2) for datasets with different distributions, techniques such as Random undersampling and Feature Selection perform better than other data pre-processing methods with T Location-Scale distribution when using SVM and KNN (K-nearest neighbours) classifiers. Random oversampling outperforms other methods on Negative Binomial distribution using Random Forest classifier with lower level of imbalance ratio; (3) Feature Selection outperforms other data pre-processing methods in most cases, thus, Feature Selection with SVM classifier is the best choice for imbalanced biomedical data learning.
* This paper is scheduled for inclusion in V16 N3 2020, International Journal of Bioinformatics Research and Applications (IJBRA)
Adaptive Morphological Reconstruction for Seeded Image Segmentation
Apr 08, 2019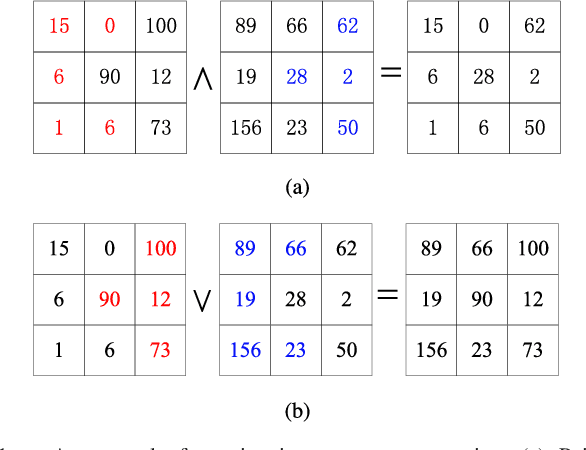
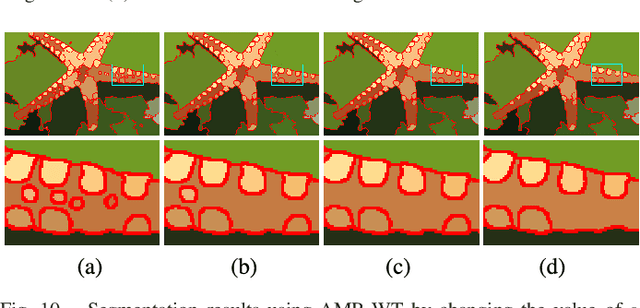
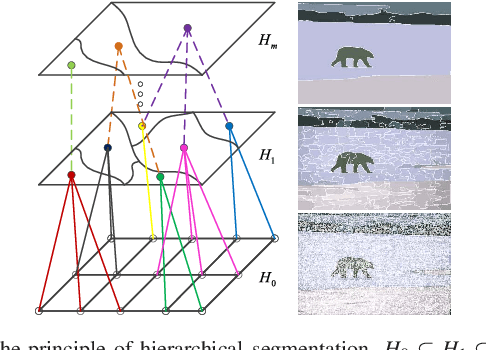

Morphological reconstruction (MR) is often employed by seeded image segmentation algorithms such as watershed transform and power watershed as it is able to filter seeds (regional minima) to reduce over-segmentation. However, MR might mistakenly filter meaningful seeds that are required for generating accurate segmentation and it is also sensitive to the scale because a single-scale structuring element is employed. In this paper, a novel adaptive morphological reconstruction (AMR) operation is proposed that has three advantages. Firstly, AMR can adaptively filter useless seeds while preserving meaningful ones. Secondly, AMR is insensitive to the scale of structuring elements because multiscale structuring elements are employed. Finally, AMR has two attractive properties: monotonic increasingness and convergence that help seeded segmentation algorithms to achieve a hierarchical segmentation. Experiments clearly demonstrate that AMR is useful for improving algorithms of seeded image segmentation and seed-based spectral segmentation. Compared to several state-of-the-art algorithms, the proposed algorithms provide better segmentation results requiring less computing time. Source code is available at https://github.com/SUST-reynole/AMR.