 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Data Pre-processing Techniques for Imbalanced Biomedical Data Classification
Nov 04, 2019
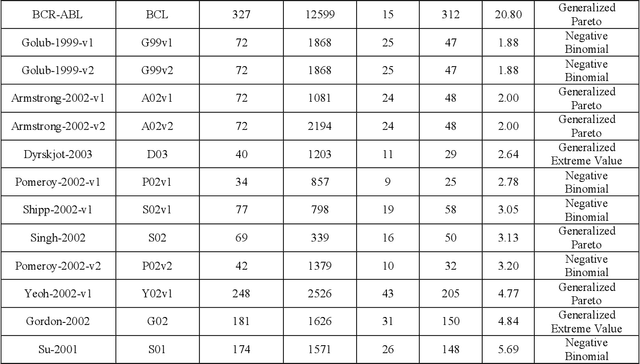

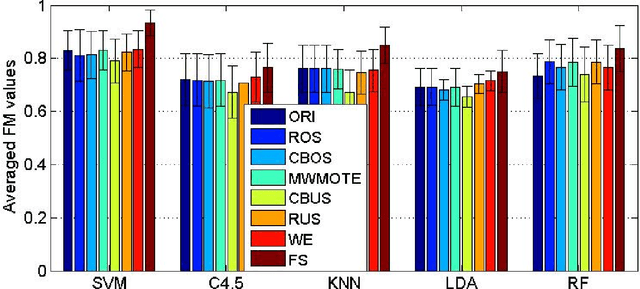
Biomedical data are widely accepted in developing prediction models for identifying a specific tumor, drug discovery and classification of human cancers. However, previous studies usually focused on different classifiers, and overlook the class imbalance problem in real-world biomedical datasets. There are a lack of studies on evaluation of data pre-processing techniques, such as resampling and feature selection, on imbalanced biomedical data learning. The relationship between data pre-processing techniques and the data distributions has never been analysed in previous studies. This article mainly focuses on reviewing and evaluating some popular and recently developed resampling and feature selection methods for class imbalance learning. We analyse the effectiveness of each technique from data distribution perspective. Extensive experiments have been done based on five classifiers, four performance measures, eight learning techniques across twenty real-world datasets. Experimental results show that: (1) resampling and feature selection techniques exhibit better performance using support vector machine (SVM) classifier. However, resampling and Feature Selection techniques perform poorly when using C4.5 decision tree and Linear discriminant analysis classifiers; (2) for datasets with different distributions, techniques such as Random undersampling and Feature Selection perform better than other data pre-processing methods with T Location-Scale distribution when using SVM and KNN (K-nearest neighbours) classifiers. Random oversampling outperforms other methods on Negative Binomial distribution using Random Forest classifier with lower level of imbalance ratio; (3) Feature Selection outperforms other data pre-processing methods in most cases, thus, Feature Selection with SVM classifier is the best choice for imbalanced biomedical data learning.
* This paper is scheduled for inclusion in V16 N3 2020, International Journal of Bioinformatics Research and Applications (IJBRA)