 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified but Fooled! Breaking Certified Defences with Ghost Certificates
Nov 18, 2025Certified defenses promise provable robustness guarantees. We study the malicious exploitation of probabilistic certification frameworks to better understand the limits of guarantee provisions. Now, the objective is to not only mislead a classifier, but also manipulate the certification process to generate a robustness guarantee for an adversarial input certificate spoofing. A recent study in ICLR demonstrated that crafting large perturbations can shift inputs far into regions capable of generating a certificate for an incorrect class. Our study investigates if perturbations needed to cause a misclassification and yet coax a certified model into issuing a deceptive, large robustness radius for a target class can still be made small and imperceptible. We explore the idea of region-focused adversarial examples to craft imperceptible perturbations, spoof certificates and achieve certification radii larger than the source class ghost certificates. Extensive evaluations with the ImageNet demonstrate the ability to effectively bypass state-of-the-art certified defenses such as Densepure. Our work underscores the need to better understand the limits of robustness certification methods.
Fantastic Targets for Concept Erasure in Diffusion Models and Where To Find Them
Jan 31, 2025Concept erasure has emerged as a promising technique for mitigating the risk of harmful content generation in diffusion models by selectively unlearning undesirable concepts. The common principle of previous works to remove a specific concept is to map it to a fixed generic concept, such as a neutral concept or just an empty text prompt. In this paper, we demonstrate that this fixed-target strategy is suboptimal, as it fails to account for the impact of erasing one concept on the others. To address this limitation, we model the concept space as a graph and empirically analyze the effects of erasing one concept on the remaining concepts. Our analysis uncovers intriguing geometric properties of the concept space, where the influence of erasing a concept is confined to a local region. Building on this insight, we propose the Adaptive Guided Erasure (AGE) method, which \emph{dynamically} selects optimal target concepts tailored to each undesirable concept, minimizing unintended side effects. Experimental results show that AGE significantly outperforms state-of-the-art erasure methods on preserving unrelated concepts while maintaining effective erasure performance. Our code is published at {https://github.com/tuananhbui89/Adaptive-Guided-Erasure}.
Erasing Undesirable Concepts in Diffusion Models with Adversarial Preservation
Oct 21, 2024



Diffusion models excel at generating visually striking content from text but can inadvertently produce undesirable or harmful content when trained on unfiltered internet data. A practical solution is to selectively removing target concepts from the model, but this may impact the remaining concepts. Prior approaches have tried to balance this by introducing a loss term to preserve neutral content or a regularization term to minimize changes in the model parameters, yet resolving this trade-off remains challenging. In this work, we propose to identify and preserving concepts most affected by parameter changes, termed as \textit{adversarial concepts}. This approach ensures stable erasure with minimal impact on the other concepts. We demonstrate the effectiveness of our method using the Stable Diffusion model, showing that it outperforms state-of-the-art erasure methods in eliminating unwanted content while maintaining the integrity of other unrelated elements. Our code is available at \url{https://github.com/tuananhbui89/Erasing-Adversarial-Preservation}.
EaTVul: ChatGPT-based Evasion Attack Against Software Vulnerability Detection
Jul 27, 2024



Recently, deep learning has demonstrated promising results in enhancing the accuracy of vulnerability detection and identifying vulnerabilities in software. However, these techniques are still vulnerable to attacks. Adversarial examples can exploit vulnerabilities within deep neural networks, posing a significant threat to system security. This study showcases the susceptibility of deep learning models to adversarial attacks, which can achieve 100% attack success rate (refer to Table 5). The proposed method, EaTVul, encompasses six stages: identification of important samples using support vector machines, identification of important features using the attention mechanism, generation of adversarial data based on these features using ChatGPT, preparation of an adversarial attack pool, selection of seed data using a fuzzy genetic algorithm, and the execution of an evasion attack. Extensive experiments demonstrate the effectiveness of EaTVul, achieving an attack success rate of more than 83% when the snippet size is greater than 2. Furthermore, in most cases with a snippet size of 4, EaTVul achieves a 100% attack success rate. The findings of this research emphasize the necessity of robust defenses against adversarial attacks in software vulnerability detection.
Removing Undesirable Concepts in Text-to-Image Generative Models with Learnable Prompts
Mar 18, 2024Generative models have demonstrated remarkable potential in generating visually impressive content from textual descriptions. However, training these models on unfiltered internet data poses the risk of learning and subsequently propagating undesirable concepts, such as copyrighted or unethical content. In this paper, we propose a novel method to remove undesirable concepts from text-to-image generative models by incorporating a learnable prompt into the cross-attention module. This learnable prompt acts as additional memory to transfer the knowledge of undesirable concepts into it and reduce the dependency of these concepts on the model parameters and corresponding textual inputs. Because of this knowledge transfer into the prompt, erasing these undesirable concepts is more stable and has minimal negative impact on other concepts. We demonstrate the effectiveness of our method on the Stable Diffusion model, showcasing its superiority over state-of-the-art erasure methods in terms of removing undesirable content while preserving other unrelated elements.
Transferable Graph Backdoor Attack
Jul 05, 2022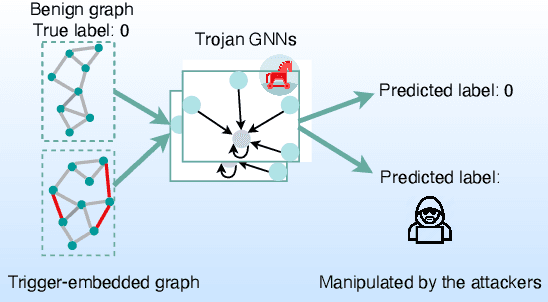

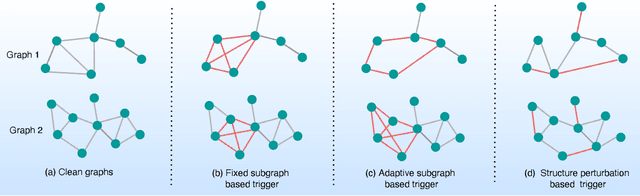
Graph Neural Networks (GNNs) have achieved tremendous success in many graph mining tasks benefitting from the message passing strategy that fuses the local structure and node features for better graph representation learning. Despite the success of GNNs, and similar to other types of deep neural networks, GNNs are found to be vulnerable to unnoticeable perturbations on both graph structure and node features. Many adversarial attacks have been proposed to disclose the fragility of GNNs under different perturbation strategies to create adversarial examples. However, vulnerability of GNNs to successful backdoor attacks was only shown recently. In this paper, we disclose the TRAP attack, a Transferable GRAPh backdoor attack. The core attack principle is to poison the training dataset with perturbation-based triggers that can lead to an effective and transferable backdoor attack. The perturbation trigger for a graph is generated by performing the perturbation actions on the graph structure via a gradient based score matrix from a surrogate model. Compared with prior works, TRAP attack is different in several ways: i) it exploits a surrogate Graph Convolutional Network (GCN) model to generate perturbation triggers for a blackbox based backdoor attack; ii) it generates sample-specific perturbation triggers which do not have a fixed pattern; and iii) the attack transfers, for the first time in the context of GNNs, to different GNN models when trained with the forged poisoned training dataset. Through extensive evaluations on four real-world datasets, we demonstrate the effectiveness of the TRAP attack to build transferable backdoors in four different popular GNNs using four real-world datasets.
Towards Understanding Pixel Vulnerability under Adversarial Attacks for Images
Oct 13, 2020

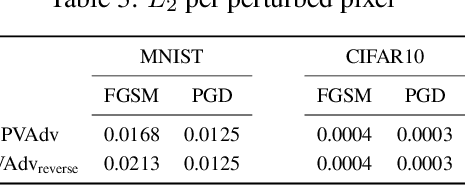
Deep neural network image classifiers are reported to be susceptible to adversarial evasion attacks, which use carefully crafted images created to mislead a classifier. Recently, various kinds of adversarial attack methods have been proposed, most of which focus on adding small perturbations to all of the pixels of a real image. We find that a considerable amount of the perturbations on an image generated by some widely-used attacks may contribute little in attacking a classifier. However, they usually result in a more easily detectable adversarial image by both humans and adversarial attack detection algorithms. Therefore, it is important to impose the perturbations on the most vulnerable pixels of an image that can change the predictions of classifiers more readily. With the pixel vulnerability, given an existing attack, we can make its adversarial images more realistic and less detectable with fewer perturbations but keep its attack performance the same. Moreover, the discovered vulnerability assists to get a better understanding of the weakness of deep classifiers. Derived from the information-theoretic perspective, we propose a probabilistic approach for automatically finding the pixel vulnerability of an image, which is compatible with and improves over many existing adversarial attacks.
Improving Ensemble Robustness by Collaboratively Promoting and Demoting Adversarial Robustness
Sep 21, 2020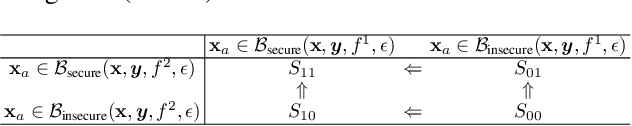
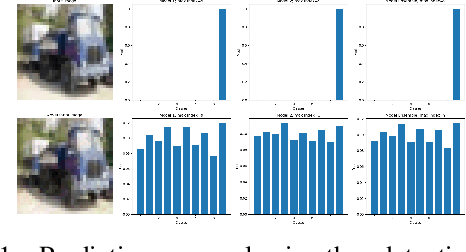
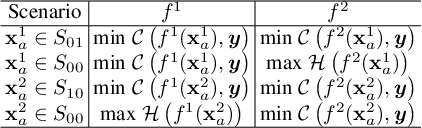
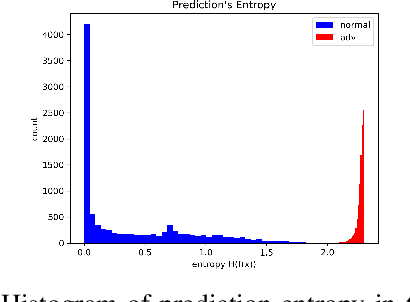
Ensemble-based adversarial training is a principled approach to achieve robustness against adversarial attacks. An important technique of this approach is to control the transferability of adversarial examples among ensemble members. We propose in this work a simple yet effective strategy to collaborate among committee models of an ensemble model. This is achieved via the secure and insecure sets defined for each model member on a given sample, hence help us to quantify and regularize the transferability. Consequently, our proposed framework provides the flexibility to reduce the adversarial transferability as well as to promote the diversity of ensemble members, which are two crucial factors for better robustness in our ensemble approach. We conduct extensive and comprehensive experiments to demonstrate that our proposed method outperforms the state-of-the-art ensemble baselines, at the same time can detect a wide range of adversarial examples with a nearly perfect accuracy.
Improving Adversarial Robustness by Enforcing Local and Global Compactness
Jul 10, 2020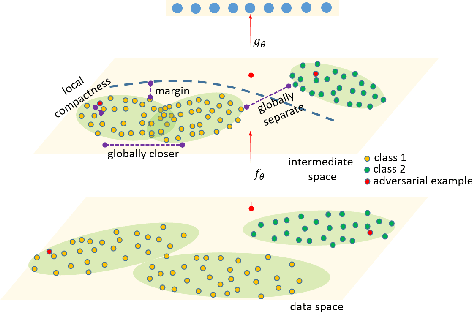
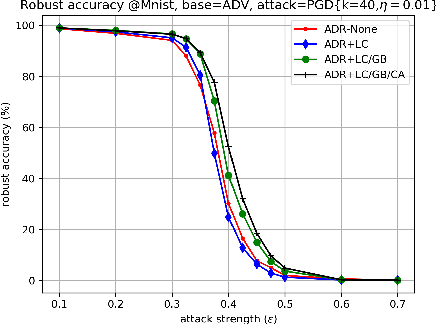
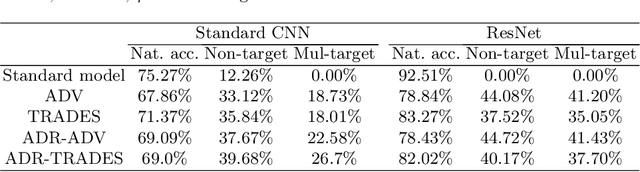
The fact that deep neural networks are susceptible to crafted perturbations severely impacts the use of deep learning in certain domains of application. Among many developed defense models against such attacks, adversarial training emerges as the most successful method that consistently resists a wide range of attacks. In this work, based on an observation from a previous study that the representations of a clean data example and its adversarial examples become more divergent in higher layers of a deep neural net, we propose the Adversary Divergence Reduction Network which enforces local/global compactness and the clustering assumption over an intermediate layer of a deep neural network. We conduct comprehensive experiments to understand the isolating behavior of each component (i.e., local/global compactness and the clustering assumption) and compare our proposed model with state-of-the-art adversarial training methods. The experimental results demonstrate that augmenting adversarial training with our proposed components can further improve the robustness of the network, leading to higher unperturbed and adversarial predictive performances.
Perturbations are not Enough: Generating Adversarial Examples with Spatial Distortions
Oct 03, 2019
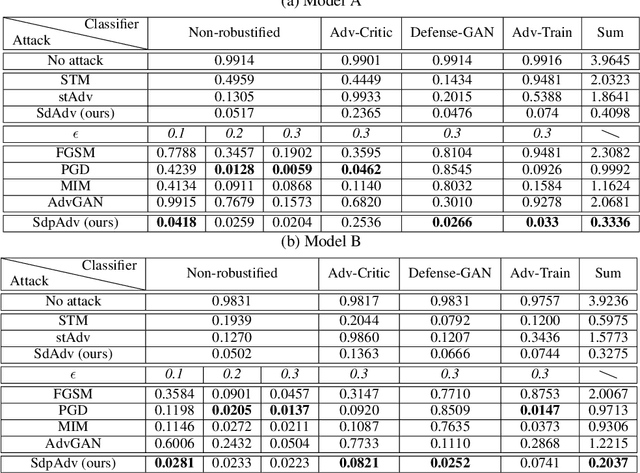
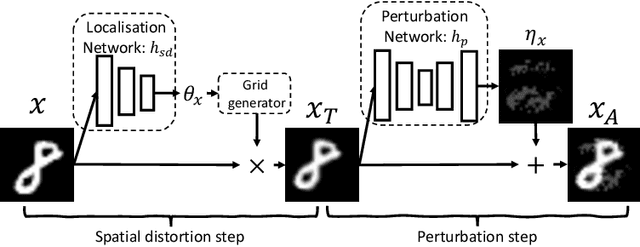
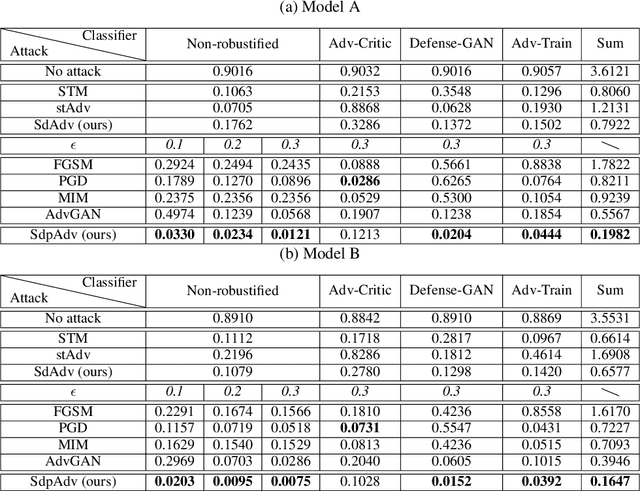
Deep neural network image classifiers are reported to be susceptible to adversarial evasion attacks, which use carefully crafted images created to mislead a classifier. Recently, various kinds of adversarial attack methods have been proposed, most of which focus on adding small perturbations to input images. Despite the success of existing approaches, the way to generate realistic adversarial images with small perturbations remains a challenging problem. In this paper, we aim to address this problem by proposing a novel adversarial method, which generates adversarial examples by imposing not only perturbations but also spatial distortions on input images, including scaling, rotation, shear, and translation. As humans are less susceptible to small spatial distortions, the proposed approach can produce visually more realistic attacks with smaller perturbations, able to deceive classifiers without affecting human predictions. We learn our method by amortized techniques with neural networks and generate adversarial examples efficiently by a forward pass of the networks. Extensive experiments on attacking different types of non-robustified classifiers and robust classifiers with defence show that our method has state-of-the-art performance in comparison with advanced attack parallels.