 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Graph Backdoor Attack
Jul 05, 2022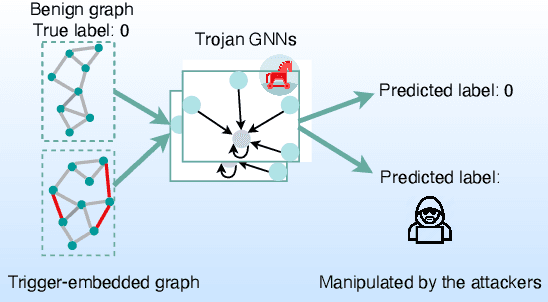

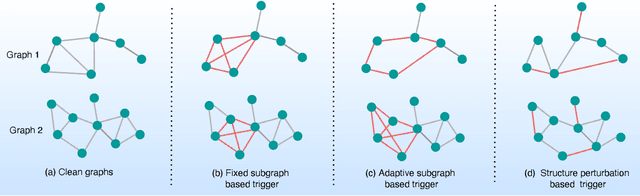
Graph Neural Networks (GNNs) have achieved tremendous success in many graph mining tasks benefitting from the message passing strategy that fuses the local structure and node features for better graph representation learning. Despite the success of GNNs, and similar to other types of deep neural networks, GNNs are found to be vulnerable to unnoticeable perturbations on both graph structure and node features. Many adversarial attacks have been proposed to disclose the fragility of GNNs under different perturbation strategies to create adversarial examples. However, vulnerability of GNNs to successful backdoor attacks was only shown recently. In this paper, we disclose the TRAP attack, a Transferable GRAPh backdoor attack. The core attack principle is to poison the training dataset with perturbation-based triggers that can lead to an effective and transferable backdoor attack. The perturbation trigger for a graph is generated by performing the perturbation actions on the graph structure via a gradient based score matrix from a surrogate model. Compared with prior works, TRAP attack is different in several ways: i) it exploits a surrogate Graph Convolutional Network (GCN) model to generate perturbation triggers for a blackbox based backdoor attack; ii) it generates sample-specific perturbation triggers which do not have a fixed pattern; and iii) the attack transfers, for the first time in the context of GNNs, to different GNN models when trained with the forged poisoned training dataset. Through extensive evaluations on four real-world datasets, we demonstrate the effectiveness of the TRAP attack to build transferable backdoors in four different popular GNNs using four real-world datasets.
Towards Understanding Pixel Vulnerability under Adversarial Attacks for Images
Oct 13, 2020

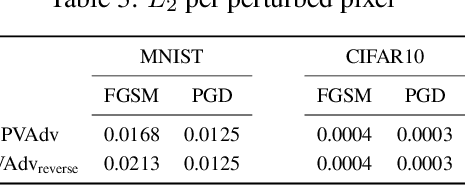
Deep neural network image classifiers are reported to be susceptible to adversarial evasion attacks, which use carefully crafted images created to mislead a classifier. Recently, various kinds of adversarial attack methods have been proposed, most of which focus on adding small perturbations to all of the pixels of a real image. We find that a considerable amount of the perturbations on an image generated by some widely-used attacks may contribute little in attacking a classifier. However, they usually result in a more easily detectable adversarial image by both humans and adversarial attack detection algorithms. Therefore, it is important to impose the perturbations on the most vulnerable pixels of an image that can change the predictions of classifiers more readily. With the pixel vulnerability, given an existing attack, we can make its adversarial images more realistic and less detectable with fewer perturbations but keep its attack performance the same. Moreover, the discovered vulnerability assists to get a better understanding of the weakness of deep classifiers. Derived from the information-theoretic perspective, we propose a probabilistic approach for automatically finding the pixel vulnerability of an image, which is compatible with and improves over many existing adversarial attacks.
Perturbations are not Enough: Generating Adversarial Examples with Spatial Distortions
Oct 03, 2019
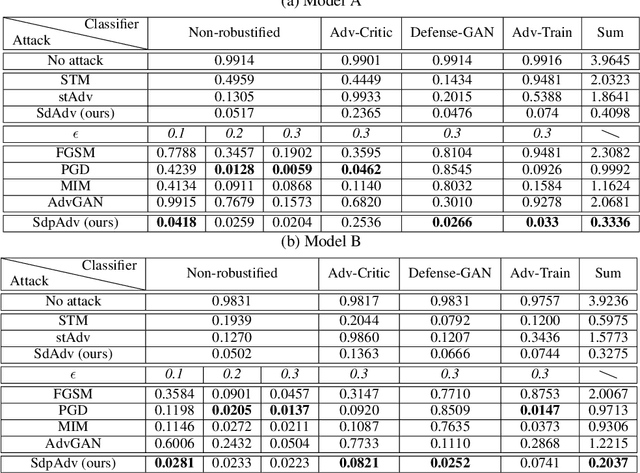
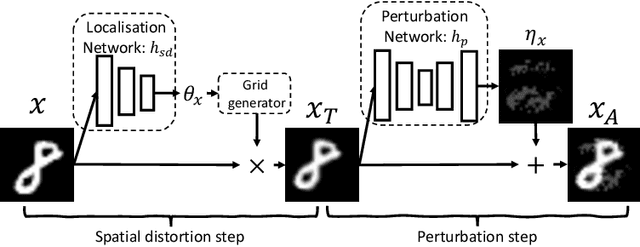
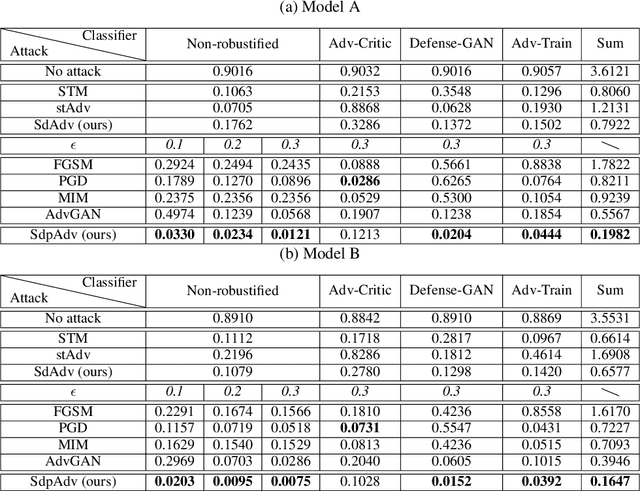
Deep neural network image classifiers are reported to be susceptible to adversarial evasion attacks, which use carefully crafted images created to mislead a classifier. Recently, various kinds of adversarial attack methods have been proposed, most of which focus on adding small perturbations to input images. Despite the success of existing approaches, the way to generate realistic adversarial images with small perturbations remains a challenging problem. In this paper, we aim to address this problem by proposing a novel adversarial method, which generates adversarial examples by imposing not only perturbations but also spatial distortions on input images, including scaling, rotation, shear, and translation. As humans are less susceptible to small spatial distortions, the proposed approach can produce visually more realistic attacks with smaller perturbations, able to deceive classifiers without affecting human predictions. We learn our method by amortized techniques with neural networks and generate adversarial examples efficiently by a forward pass of the networks. Extensive experiments on attacking different types of non-robustified classifiers and robust classifiers with defence show that our method has state-of-the-art performance in comparison with advanced attack parallels.
Adversarial Reinforcement Learning under Partial Observability in Software-Defined Networking
Feb 25, 2019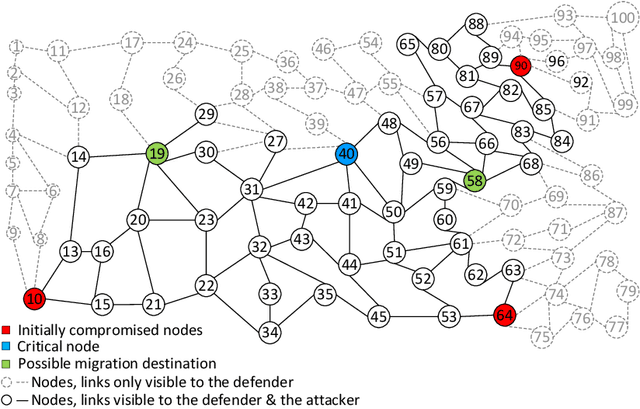

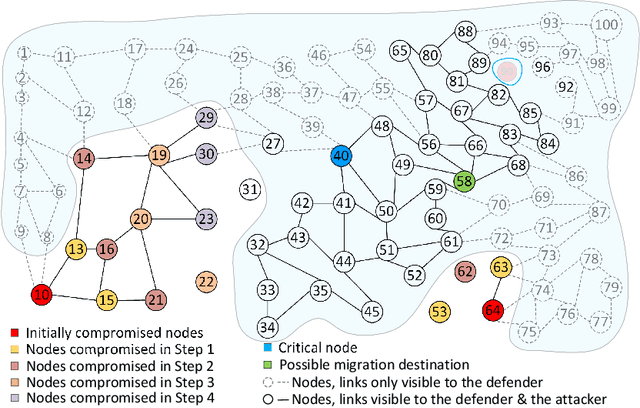
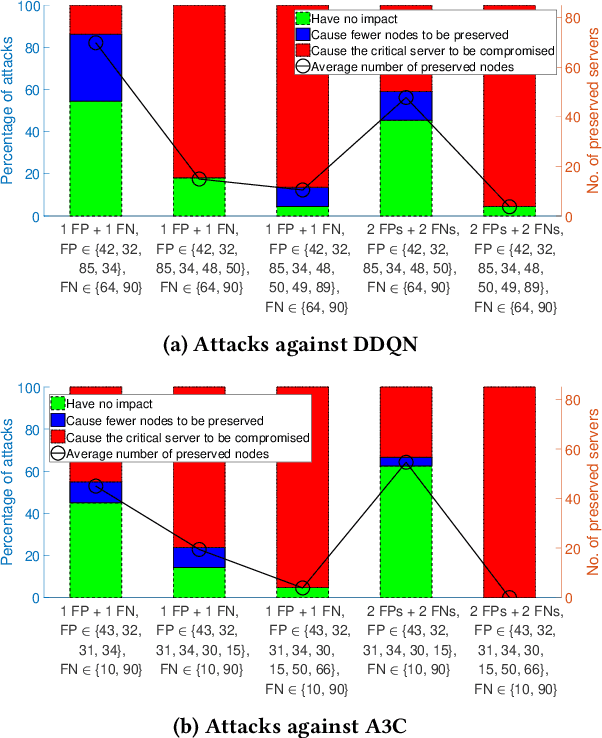
Recent studies have demonstrated that reinforcement learning (RL) agents are susceptible to adversarial manipulation, similar to vulnerabilities previously demonstrated in the supervised setting. Accordingly focus has remained with computer vision, and full observability. This paper focuses on reinforcement learning in the context of autonomous defence in Software-Defined Networking (SDN). We demonstrate that causative attacks---attacks that target the training process---can poison RL agents even if the attacker only has partial observability of the environment. In addition, we propose an inversion defence method that aims to apply the opposite perturbation to that which an attacker might use to generate their adversarial samples. Our experimental results illustrate that the countermeasure can effectively reduce the impact of the causative attack, while not significantly affecting the training process in non-attack scenarios.
Reinforcement Learning for Autonomous Defence in Software-Defined Networking
Aug 17, 2018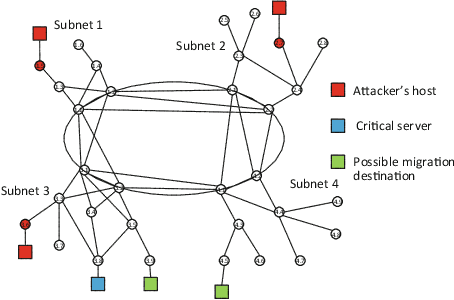

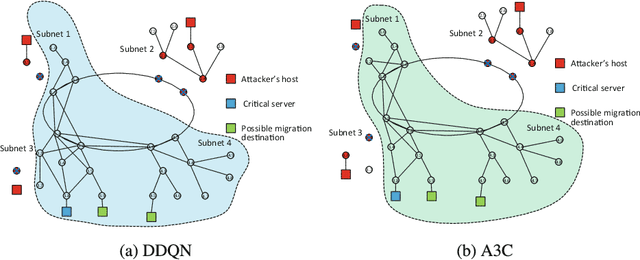
Despite the successful application of machine learning (ML) in a wide range of domains, adaptability---the very property that makes machine learning desirable---can be exploited by adversaries to contaminate training and evade classification. In this paper, we investigate the feasibility of applying a specific class of machine learning algorithms, namely, reinforcement learning (RL) algorithms, for autonomous cyber defence in software-defined networking (SDN). In particular, we focus on how an RL agent reacts towards different forms of causative attacks that poison its training process, including indiscriminate and targeted, white-box and black-box attacks. In addition, we also study the impact of the attack timing, and explore potential countermeasures such as adversarial training.