 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Low-Rank LeArning (Bella): A Practical Approach to Bayesian Neural Networks
Jul 30, 2024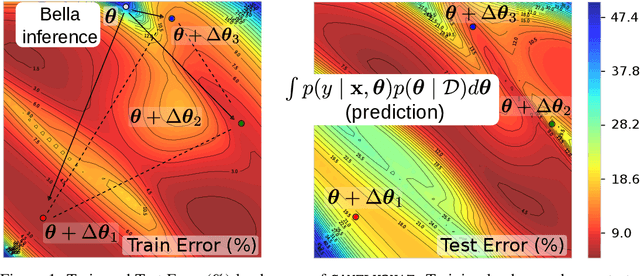

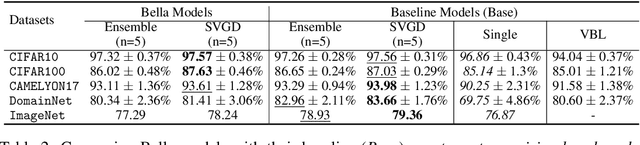

Computational complexity of Bayesian learning is impeding its adoption in practical, large-scale tasks. Despite demonstrations of significant merits such as improved robustness and resilience to unseen or out-of-distribution inputs over their non- Bayesian counterparts, their practical use has faded to near insignificance. In this study, we introduce an innovative framework to mitigate the computational burden of Bayesian neural networks (BNNs). Our approach follows the principle of Bayesian techniques based on deep ensembles, but significantly reduces their cost via multiple low-rank perturbations of parameters arising from a pre-trained neural network. Both vanilla version of ensembles as well as more sophisticated schemes such as Bayesian learning with Stein Variational Gradient Descent (SVGD), previously deemed impractical for large models, can be seamlessly implemented within the proposed framework, called Bayesian Low-Rank LeArning (Bella). In a nutshell, i) Bella achieves a dramatic reduction in the number of trainable parameters required to approximate a Bayesian posterior; and ii) it not only maintains, but in some instances, surpasses the performance of conventional Bayesian learning methods and non-Bayesian baselines. Our results with large-scale tasks such as ImageNet, CAMELYON17, DomainNet, VQA with CLIP, LLaVA demonstrate the effectiveness and versatility of Bella in building highly scalable and practical Bayesian deep models for real-world applications.
Bayesian Learning with Information Gain Provably Bounds Risk for a Robust Adversarial Defense
Dec 05, 2022We present a new algorithm to learn a deep neural network model robust against adversarial attacks. Previous algorithms demonstrate an adversarially trained Bayesian Neural Network (BNN) provides improved robustness. We recognize the adversarial learning approach for approximating the multi-modal posterior distribution of a Bayesian model can lead to mode collapse; consequently, the model's achievements in robustness and performance are sub-optimal. Instead, we first propose preventing mode collapse to better approximate the multi-modal posterior distribution. Second, based on the intuition that a robust model should ignore perturbations and only consider the informative content of the input, we conceptualize and formulate an information gain objective to measure and force the information learned from both benign and adversarial training instances to be similar. Importantly. we prove and demonstrate that minimizing the information gain objective allows the adversarial risk to approach the conventional empirical risk. We believe our efforts provide a step toward a basis for a principled method of adversarially training BNNs. Our model demonstrate significantly improved robustness--up to 20%--compared with adversarial training and Adv-BNN under PGD attacks with 0.035 distortion on both CIFAR-10 and STL-10 datasets.
* Published at ICML 2022
Transferable Graph Backdoor Attack
Jul 05, 2022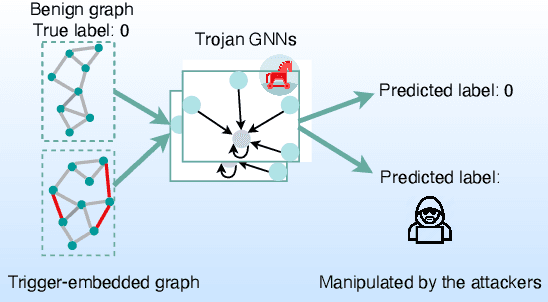

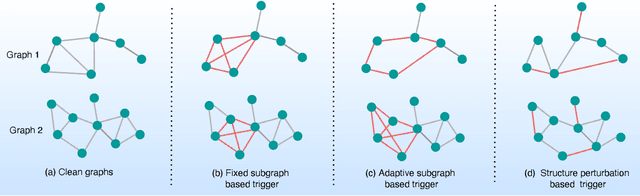
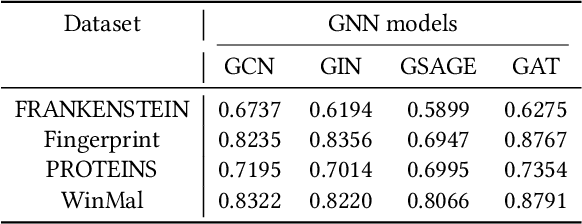
Graph Neural Networks (GNNs) have achieved tremendous success in many graph mining tasks benefitting from the message passing strategy that fuses the local structure and node features for better graph representation learning. Despite the success of GNNs, and similar to other types of deep neural networks, GNNs are found to be vulnerable to unnoticeable perturbations on both graph structure and node features. Many adversarial attacks have been proposed to disclose the fragility of GNNs under different perturbation strategies to create adversarial examples. However, vulnerability of GNNs to successful backdoor attacks was only shown recently. In this paper, we disclose the TRAP attack, a Transferable GRAPh backdoor attack. The core attack principle is to poison the training dataset with perturbation-based triggers that can lead to an effective and transferable backdoor attack. The perturbation trigger for a graph is generated by performing the perturbation actions on the graph structure via a gradient based score matrix from a surrogate model. Compared with prior works, TRAP attack is different in several ways: i) it exploits a surrogate Graph Convolutional Network (GCN) model to generate perturbation triggers for a blackbox based backdoor attack; ii) it generates sample-specific perturbation triggers which do not have a fixed pattern; and iii) the attack transfers, for the first time in the context of GNNs, to different GNN models when trained with the forged poisoned training dataset. Through extensive evaluations on four real-world datasets, we demonstrate the effectiveness of the TRAP attack to build transferable backdoors in four different popular GNNs using four real-world datasets.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems
Nov 19, 2021


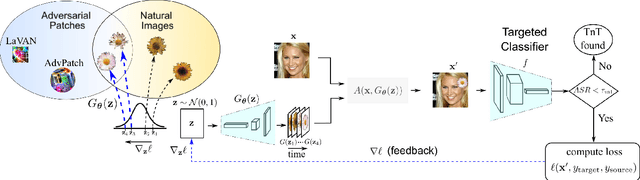
Deep neural networks are vulnerable to attacks from adversarial inputs and, more recently, Trojans to misguide or hijack the decision of the model. We expose the existence of an intriguing class of bounded adversarial examples -- Universal NaTuralistic adversarial paTches -- we call TnTs, by exploring the superset of the bounded adversarial example space and the natural input space within generative adversarial networks. Now, an adversary can arm themselves with a patch that is naturalistic, less malicious-looking, physically realizable, highly effective -- achieving high attack success rates, and universal. A TnT is universal because any input image captured with a TnT in the scene will: i) misguide a network (untargeted attack); or ii) force the network to make a malicious decision (targeted attack). Interestingly, now, an adversarial patch attacker has the potential to exert a greater level of control -- the ability to choose a location independent, natural-looking patch as a trigger in contrast to being constrained to noisy perturbations -- an ability is thus far shown to be only possible with Trojan attack methods needing to interfere with the model building processes to embed a backdoor at the risk discovery; but, still realize a patch deployable in the physical world. Through extensive experiments on the large-scale visual classification task, ImageNet with evaluations across its entire validation set of 50,000 images, we demonstrate the realistic threat from TnTs and the robustness of the attack. We show a generalization of the attack to create patches achieving higher attack success rates than existing state-of-the-art methods. Our results show the generalizability of the attack to different visual classification tasks (CIFAR-10, GTSRB, PubFig) and multiple state-of-the-art deep neural networks such as WideResnet50, Inception-V3 and VGG-16.
Backdoor Attacks and Countermeasures on Deep Learning: A Comprehensive Review
Aug 02, 2020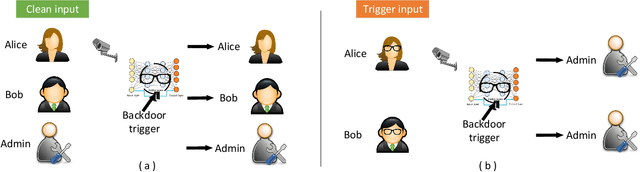
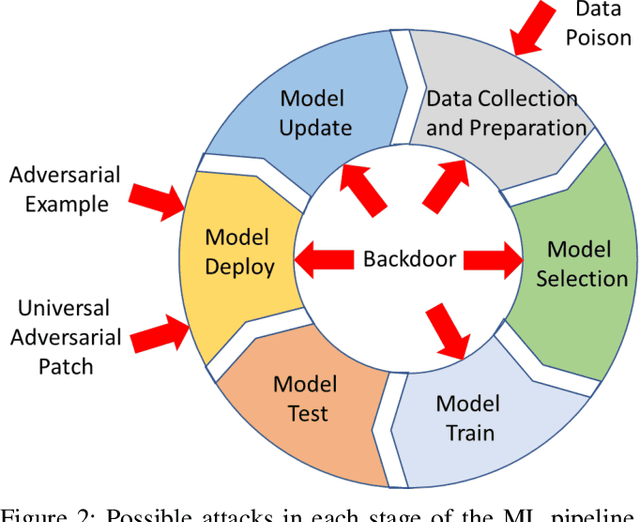
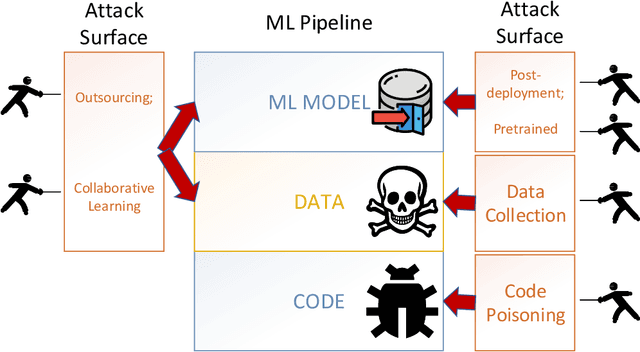

This work provides the community with a timely comprehensive review of backdoor attacks and countermeasures on deep learning. According to the attacker's capability and affected stage of the machine learning pipeline, the attack surfaces are recognized to be wide and then formalized into six categorizations: code poisoning, outsourcing, pretrained, data collection, collaborative learning and post-deployment. Accordingly, attacks under each categorization are combed. The countermeasures are categorized into four general classes: blind backdoor removal, offline backdoor inspection, online backdoor inspection, and post backdoor removal. Accordingly, we review countermeasures, and compare and analyze their advantages and disadvantages. We have also reviewed the flip side of backdoor attacks, which are explored for i) protecting intellectual property of deep learning models, ii) acting as a honeypot to catch adversarial example attacks, and iii) verifying data deletion requested by the data contributor.Overall, the research on defense is far behind the attack, and there is no single defense that can prevent all types of backdoor attacks. In some cases, an attacker can intelligently bypass existing defenses with an adaptive attack. Drawing the insights from the systematic review, we also present key areas for future research on the backdoor, such as empirical security evaluations from physical trigger attacks, and in particular, more efficient and practical countermeasures are solicited.