 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems
Paper and Code



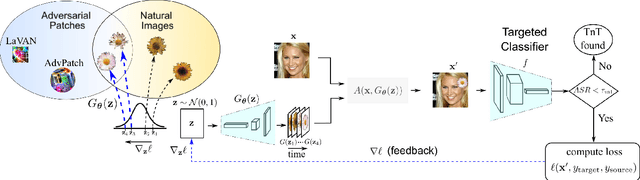
Deep neural networks are vulnerable to attacks from adversarial inputs and, more recently, Trojans to misguide or hijack the decision of the model. We expose the existence of an intriguing class of bounded adversarial examples -- Universal NaTuralistic adversarial paTches -- we call TnTs, by exploring the superset of the bounded adversarial example space and the natural input space within generative adversarial networks. Now, an adversary can arm themselves with a patch that is naturalistic, less malicious-looking, physically realizable, highly effective -- achieving high attack success rates, and universal. A TnT is universal because any input image captured with a TnT in the scene will: i) misguide a network (untargeted attack); or ii) force the network to make a malicious decision (targeted attack). Interestingly, now, an adversarial patch attacker has the potential to exert a greater level of control -- the ability to choose a location independent, natural-looking patch as a trigger in contrast to being constrained to noisy perturbations -- an ability is thus far shown to be only possible with Trojan attack methods needing to interfere with the model building processes to embed a backdoor at the risk discovery; but, still realize a patch deployable in the physical world. Through extensive experiments on the large-scale visual classification task, ImageNet with evaluations across its entire validation set of 50,000 images, we demonstrate the realistic threat from TnTs and the robustness of the attack. We show a generalization of the attack to create patches achieving higher attack success rates than existing state-of-the-art methods. Our results show the generalizability of the attack to different visual classification tasks (CIFAR-10, GTSRB, PubFig) and multiple state-of-the-art deep neural networks such as WideResnet50, Inception-V3 and VGG-16.