 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Robustness Certification for Vision-Language Models
Jun 17, 2026Vision-language models (VLMs) are now widely used in downstream tasks. However, real-world applications often expose VLMs to distribution shifts induced by semantic variation (e.g., shape, size, and style). Robustness certification determines if a model's prediction changes when transformations are applied to its input. While most certification frameworks study geometric or pixel-level transformations over inputs, this work proposes a novel framework that enables certifying VLM robustness under semantic-level transformations. Leveraging the open-vocabulary capability of VLMs, we use text prompts as semantic proxies to construct transformations parameterized by an extent that controls the degree of semantic variation. By characterizing the VLM decision boundary in closed form, our framework quantitatively certifies extent intervals for which the predicted class remains unchanged under the semantic transformation. Our framework is the first to certify VLM robustness under semantic-level variations without requiring additional data for each variation, making it practical to apply. Experiments on both synthetic and real-world data show that our framework enables certifying robustness under diverse semantic variations across scenarios.
Hearing the Unspoken: Language Model Priors for Acoustic Adversarial Attacks
Jun 05, 2026Automatic Speech Recognition (ASR) systems operating in real-time settings must process acoustic input under strict temporal constraints, where transcription decisions are inherently made on incomplete information. This causal constraint serves as an information bottleneck on attackers, significantly limiting attack performance. Our new Semantic Gambit attack breaks this causal limitation by augmenting the adversary with predictive context derived from a Large Language Model in real-time. Our experiments show that this form of augmentation can elevate the corpus-level Word Error Rate to 35.6% -- a three-fold increase over the current state-of-the-art. Ultimately, this work reveals how common, low-latency LLM tooling can be exploited to systematically subvert real-time ASR pipelines.
Free Lunch for Pass@$k$? Low Cost Diverse Sampling for Diffusion Language Models
Mar 05, 2026Diverse outputs in text generation are necessary for effective exploration in complex reasoning tasks, such as code generation and mathematical problem solving. Such Pass@$k$ problems benefit from distinct candidates covering the solution space. However, traditional sampling approaches often waste computational resources on repetitive failure modes. While Diffusion Language Models have emerged as a competitive alternative to the prevailing Autoregressive paradigm, they remain susceptible to this redundancy, with independent samples frequently collapsing into similar modes. To address this, we propose a training free, low cost intervention to enhance generative diversity in Diffusion Language Models. Our approach modifies intermediate samples in a batch sequentially, where each sample is repelled from the feature space of previous samples, actively penalising redundancy. Unlike prior methods that require retraining or beam search, our strategy incurs negligible computational overhead, while ensuring that each sample contributes a unique perspective to the batch. We evaluate our method on the HumanEval and GSM8K benchmarks using the LLaDA-8B-Instruct model. Our results demonstrate significantly improved diversity and Pass@$k$ performance across various temperature settings. As a simple modification to the sampling process, our method offers an immediate, low-cost improvement for current and future Diffusion Language Models in tasks that benefit from diverse solution search. We make our code available at https://github.com/sean-lamont/odd.
Certified but Fooled! Breaking Certified Defences with Ghost Certificates
Nov 18, 2025Certified defenses promise provable robustness guarantees. We study the malicious exploitation of probabilistic certification frameworks to better understand the limits of guarantee provisions. Now, the objective is to not only mislead a classifier, but also manipulate the certification process to generate a robustness guarantee for an adversarial input certificate spoofing. A recent study in ICLR demonstrated that crafting large perturbations can shift inputs far into regions capable of generating a certificate for an incorrect class. Our study investigates if perturbations needed to cause a misclassification and yet coax a certified model into issuing a deceptive, large robustness radius for a target class can still be made small and imperceptible. We explore the idea of region-focused adversarial examples to craft imperceptible perturbations, spoof certificates and achieve certification radii larger than the source class ghost certificates. Extensive evaluations with the ImageNet demonstrate the ability to effectively bypass state-of-the-art certified defenses such as Densepure. Our work underscores the need to better understand the limits of robustness certification methods.
Position: Certified Robustness Does Not (Yet) Imply Model Security
Jun 16, 2025While certified robustness is widely promoted as a solution to adversarial examples in Artificial Intelligence systems, significant challenges remain before these techniques can be meaningfully deployed in real-world applications. We identify critical gaps in current research, including the paradox of detection without distinction, the lack of clear criteria for practitioners to evaluate certification schemes, and the potential security risks arising from users' expectations surrounding ``guaranteed" robustness claims. This position paper is a call to arms for the certification research community, proposing concrete steps to address these fundamental challenges and advance the field toward practical applicability.
Multi-level Certified Defense Against Poisoning Attacks in Offline Reinforcement Learning
May 27, 2025Similar to other machine learning frameworks, Offline Reinforcement Learning (RL) is shown to be vulnerable to poisoning attacks, due to its reliance on externally sourced datasets, a vulnerability that is exacerbated by its sequential nature. To mitigate the risks posed by RL poisoning, we extend certified defenses to provide larger guarantees against adversarial manipulation, ensuring robustness for both per-state actions, and the overall expected cumulative reward. Our approach leverages properties of Differential Privacy, in a manner that allows this work to span both continuous and discrete spaces, as well as stochastic and deterministic environments -- significantly expanding the scope and applicability of achievable guarantees. Empirical evaluations demonstrate that our approach ensures the performance drops to no more than $50\%$ with up to $7\%$ of the training data poisoned, significantly improving over the $0.008\%$ in prior work~\citep{wu_copa_2022}, while producing certified radii that is $5$ times larger as well. This highlights the potential of our framework to enhance safety and reliability in offline RL.
Fox in the Henhouse: Supply-Chain Backdoor Attacks Against Reinforcement Learning
May 26, 2025The current state-of-the-art backdoor attacks against Reinforcement Learning (RL) rely upon unrealistically permissive access models, that assume the attacker can read (or even write) the victim's policy parameters, observations, or rewards. In this work, we question whether such a strong assumption is required to launch backdoor attacks against RL. To answer this question, we propose the \underline{S}upply-\underline{C}h\underline{a}in \underline{B}ackdoor (SCAB) attack, which targets a common RL workflow: training agents using external agents that are provided separately or embedded within the environment. In contrast to prior works, our attack only relies on legitimate interactions of the RL agent with the supplied agents. Despite this limited access model, by poisoning a mere $3\%$ of training experiences, our attack can successfully activate over $90\%$ of triggered actions, reducing the average episodic return by $80\%$ for the victim. Our novel attack demonstrates that RL attacks are likely to become a reality under untrusted RL training supply-chains.
Fantastic Targets for Concept Erasure in Diffusion Models and Where To Find Them
Jan 31, 2025Concept erasure has emerged as a promising technique for mitigating the risk of harmful content generation in diffusion models by selectively unlearning undesirable concepts. The common principle of previous works to remove a specific concept is to map it to a fixed generic concept, such as a neutral concept or just an empty text prompt. In this paper, we demonstrate that this fixed-target strategy is suboptimal, as it fails to account for the impact of erasing one concept on the others. To address this limitation, we model the concept space as a graph and empirically analyze the effects of erasing one concept on the remaining concepts. Our analysis uncovers intriguing geometric properties of the concept space, where the influence of erasing a concept is confined to a local region. Building on this insight, we propose the Adaptive Guided Erasure (AGE) method, which \emph{dynamically} selects optimal target concepts tailored to each undesirable concept, minimizing unintended side effects. Experimental results show that AGE significantly outperforms state-of-the-art erasure methods on preserving unrelated concepts while maintaining effective erasure performance. Our code is published at {https://github.com/tuananhbui89/Adaptive-Guided-Erasure}.
Erasing Undesirable Concepts in Diffusion Models with Adversarial Preservation
Oct 21, 2024



Diffusion models excel at generating visually striking content from text but can inadvertently produce undesirable or harmful content when trained on unfiltered internet data. A practical solution is to selectively removing target concepts from the model, but this may impact the remaining concepts. Prior approaches have tried to balance this by introducing a loss term to preserve neutral content or a regularization term to minimize changes in the model parameters, yet resolving this trade-off remains challenging. In this work, we propose to identify and preserving concepts most affected by parameter changes, termed as \textit{adversarial concepts}. This approach ensures stable erasure with minimal impact on the other concepts. We demonstrate the effectiveness of our method using the Stable Diffusion model, showing that it outperforms state-of-the-art erasure methods in eliminating unwanted content while maintaining the integrity of other unrelated elements. Our code is available at \url{https://github.com/tuananhbui89/Erasing-Adversarial-Preservation}.
3D-Prover: Diversity Driven Theorem Proving With Determinantal Point Processes
Oct 14, 2024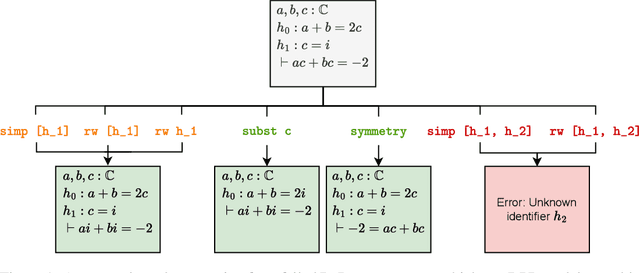

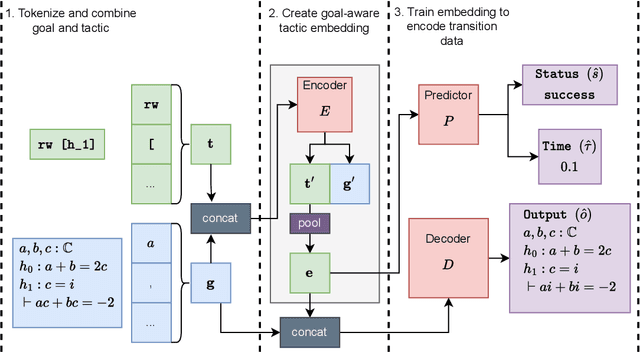

A key challenge in automated formal reasoning is the intractable search space, which grows exponentially with the depth of the proof. This branching is caused by the large number of candidate proof tactics which can be applied to a given goal. Nonetheless, many of these tactics are semantically similar or lead to an execution error, wasting valuable resources in both cases. We address the problem of effectively pruning this search, using only synthetic data generated from previous proof attempts. We first demonstrate that it is possible to generate semantically aware tactic representations which capture the effect on the proving environment, likelihood of success and execution time. We then propose a novel filtering mechanism which leverages these representations to select semantically diverse and high quality tactics, using Determinantal Point Processes. Our approach, 3D-Prover, is designed to be general, and to augment any underlying tactic generator. We demonstrate the effectiveness of 3D-Prover on the miniF2F-valid and miniF2F-test benchmarks by augmenting the ReProver LLM. We show that our approach leads to an increase in the overall proof rate, as well as a significant improvement in the tactic success rate, execution time and diversity.