 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Lunch for Pass@$k$? Low Cost Diverse Sampling for Diffusion Language Models
Mar 05, 2026Diverse outputs in text generation are necessary for effective exploration in complex reasoning tasks, such as code generation and mathematical problem solving. Such Pass@$k$ problems benefit from distinct candidates covering the solution space. However, traditional sampling approaches often waste computational resources on repetitive failure modes. While Diffusion Language Models have emerged as a competitive alternative to the prevailing Autoregressive paradigm, they remain susceptible to this redundancy, with independent samples frequently collapsing into similar modes. To address this, we propose a training free, low cost intervention to enhance generative diversity in Diffusion Language Models. Our approach modifies intermediate samples in a batch sequentially, where each sample is repelled from the feature space of previous samples, actively penalising redundancy. Unlike prior methods that require retraining or beam search, our strategy incurs negligible computational overhead, while ensuring that each sample contributes a unique perspective to the batch. We evaluate our method on the HumanEval and GSM8K benchmarks using the LLaDA-8B-Instruct model. Our results demonstrate significantly improved diversity and Pass@$k$ performance across various temperature settings. As a simple modification to the sampling process, our method offers an immediate, low-cost improvement for current and future Diffusion Language Models in tasks that benefit from diverse solution search. We make our code available at https://github.com/sean-lamont/odd.
3D-Prover: Diversity Driven Theorem Proving With Determinantal Point Processes
Oct 14, 2024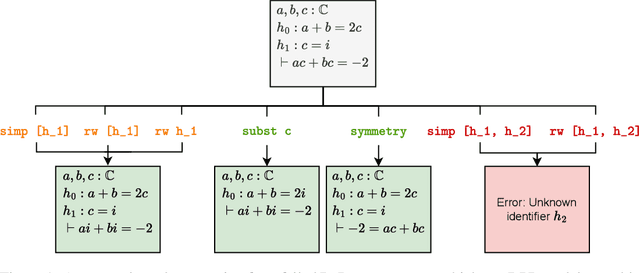

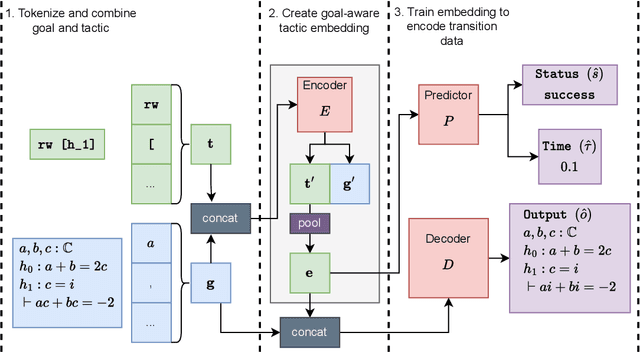

A key challenge in automated formal reasoning is the intractable search space, which grows exponentially with the depth of the proof. This branching is caused by the large number of candidate proof tactics which can be applied to a given goal. Nonetheless, many of these tactics are semantically similar or lead to an execution error, wasting valuable resources in both cases. We address the problem of effectively pruning this search, using only synthetic data generated from previous proof attempts. We first demonstrate that it is possible to generate semantically aware tactic representations which capture the effect on the proving environment, likelihood of success and execution time. We then propose a novel filtering mechanism which leverages these representations to select semantically diverse and high quality tactics, using Determinantal Point Processes. Our approach, 3D-Prover, is designed to be general, and to augment any underlying tactic generator. We demonstrate the effectiveness of 3D-Prover on the miniF2F-valid and miniF2F-test benchmarks by augmenting the ReProver LLM. We show that our approach leads to an increase in the overall proof rate, as well as a significant improvement in the tactic success rate, execution time and diversity.
BAIT: Benchmarking (Embedding) Architectures for Interactive Theorem-Proving
Mar 06, 2024Artificial Intelligence for Theorem Proving has given rise to a plethora of benchmarks and methodologies, particularly in Interactive Theorem Proving (ITP). Research in the area is fragmented, with a diverse set of approaches being spread across several ITP systems. This presents a significant challenge to the comparison of methods, which are often complex and difficult to replicate. Addressing this, we present BAIT, a framework for fair and streamlined comparison of learning approaches in ITP. We demonstrate BAIT's capabilities with an in-depth comparison, across several ITP benchmarks, of state-of-the-art architectures applied to the problem of formula embedding. We find that Structure Aware Transformers perform particularly well, improving on techniques associated with the original problem sets. BAIT also allows us to assess the end-to-end proving performance of systems built on interactive environments. This unified perspective reveals a novel end-to-end system that improves on prior work. We also provide a qualitative analysis, illustrating that improved performance is associated with more semantically-aware embeddings. By streamlining the implementation and comparison of Machine Learning algorithms in the ITP context, we anticipate BAIT will be a springboard for future research.
TacticZero: Learning to Prove Theorems from Scratch with Deep Reinforcement Learning
Feb 19, 2021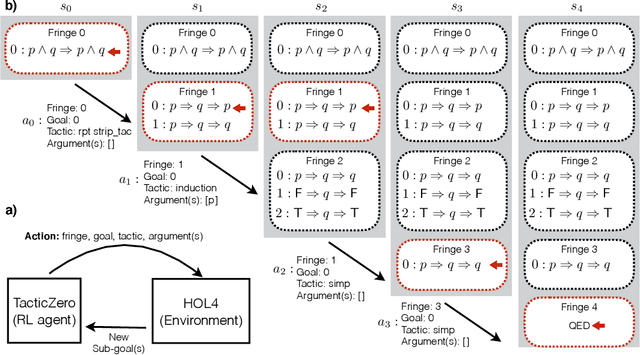
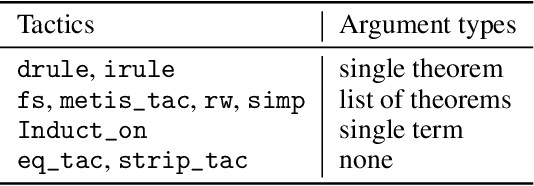
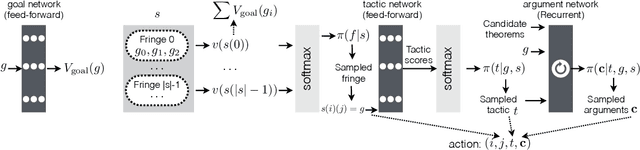
We propose a novel approach to interactive theorem-proving (ITP) using deep reinforcement learning. Unlike previous work, our framework is able to prove theorems both end-to-end and from scratch (i.e., without relying on example proofs from human experts). We formulate the process of ITP as a Markov decision process (MDP) in which each state represents a set of potential derivation paths. The agent learns to select promising derivations as well as appropriate tactics within each derivation using deep policy gradients. This structure allows us to introduce a novel backtracking mechanism which enables the agent to efficiently discard (predicted) dead-end derivations and restart the derivation from promising alternatives. Experimental results show that the framework provides comparable performance to that of the approaches that use human experts, and that it is also capable of proving theorems that it has never seen during training. We further elaborate the role of each component of the framework using ablation studies.
Learning to Prove with Tactics
Apr 02, 2018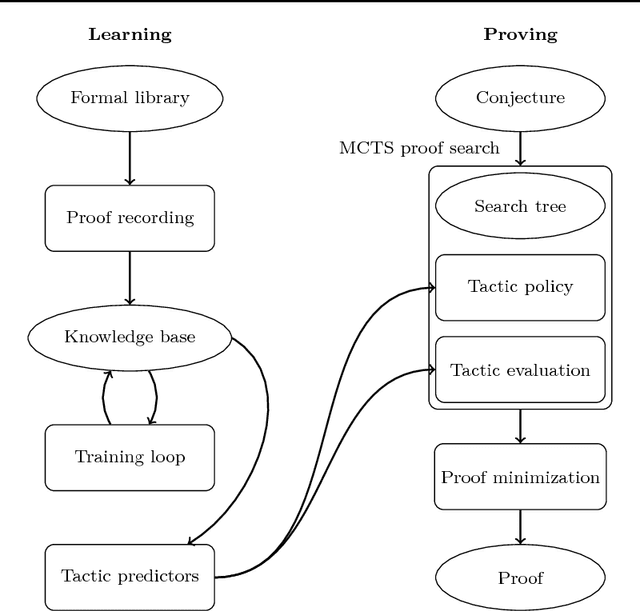
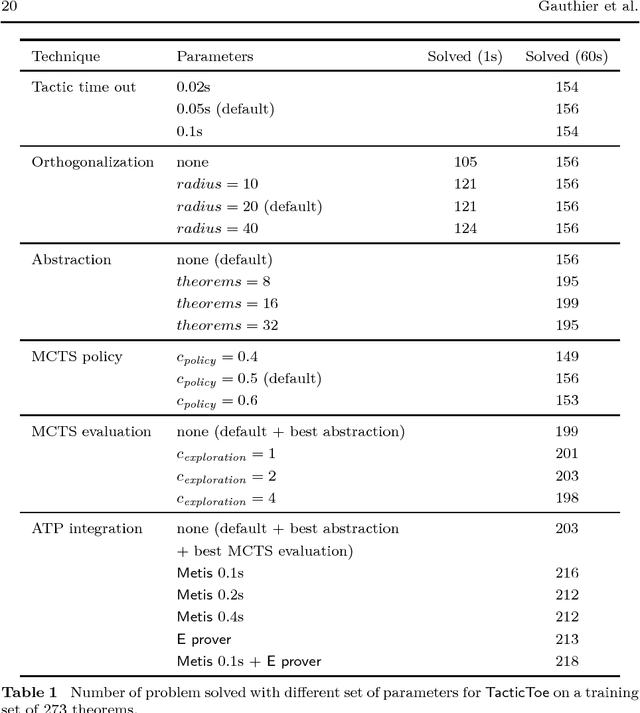
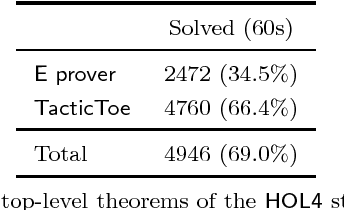
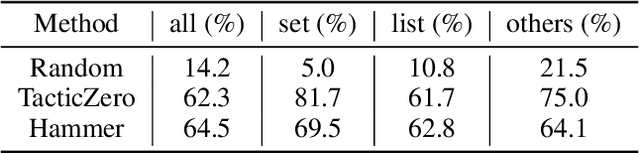
We implement a automated tactical prover TacticToe on top of the HOL4 interactive theorem prover. TacticToe learns from human proofs which mathematical technique is suitable in each proof situation. This knowledge is then used in a Monte Carlo tree search algorithm to explore promising tactic-level proof paths. On a single CPU, with a time limit of 60 seconds, TacticToe proves 66.4 percent of the 7164 theorems in HOL4's standard library, whereas E prover with auto-schedule solves 34.5 percent. The success rate rises to 69.0 percent by combining the results of TacticToe and E prover.