 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Universal and Transferable Jailbreak Attacks on Vision-Language Models
Feb 01, 2026Vision-language models (VLMs) extend large language models (LLMs) with vision encoders, enabling text generation conditioned on both images and text. However, this multimodal integration expands the attack surface by exposing the model to image-based jailbreaks crafted to induce harmful responses. Existing gradient-based jailbreak methods transfer poorly, as adversarial patterns overfit to a single white-box surrogate and fail to generalise to black-box models. In this work, we propose Universal and transferable jailbreak (UltraBreak), a framework that constrains adversarial patterns through transformations and regularisation in the vision space, while relaxing textual targets through semantic-based objectives. By defining its loss in the textual embedding space of the target LLM, UltraBreak discovers universal adversarial patterns that generalise across diverse jailbreak objectives. This combination of vision-level regularisation and semantically guided textual supervision mitigates surrogate overfitting and enables strong transferability across both models and attack targets. Extensive experiments show that UltraBreak consistently outperforms prior jailbreak methods. Further analysis reveals why earlier approaches fail to transfer, highlighting that smoothing the loss landscape via semantic objectives is crucial for enabling universal and transferable jailbreaks. The code is publicly available in our \href{https://github.com/kaiyuanCui/UltraBreak}{GitHub repository}.
AUDETER: A Large-scale Dataset for Deepfake Audio Detection in Open Worlds
Sep 04, 2025



Speech generation systems can produce remarkably realistic vocalisations that are often indistinguishable from human speech, posing significant authenticity challenges. Although numerous deepfake detection methods have been developed, their effectiveness in real-world environments remains unrealiable due to the domain shift between training and test samples arising from diverse human speech and fast evolving speech synthesis systems. This is not adequately addressed by current datasets, which lack real-world application challenges with diverse and up-to-date audios in both real and deep-fake categories. To fill this gap, we introduce AUDETER (AUdio DEepfake TEst Range), a large-scale, highly diverse deepfake audio dataset for comprehensive evaluation and robust development of generalised models for deepfake audio detection. It consists of over 4,500 hours of synthetic audio generated by 11 recent TTS models and 10 vocoders with a broad range of TTS/vocoder patterns, totalling 3 million audio clips, making it the largest deepfake audio dataset by scale. Through extensive experiments with AUDETER, we reveal that i) state-of-the-art (SOTA) methods trained on existing datasets struggle to generalise to novel deepfake audio samples and suffer from high false positive rates on unseen human voice, underscoring the need for a comprehensive dataset; and ii) these methods trained on AUDETER achieve highly generalised detection performance and significantly reduce detection error rate by 44.1% to 51.6%, achieving an error rate of only 4.17% on diverse cross-domain samples in the popular In-the-Wild dataset, paving the way for training generalist deepfake audio detectors. AUDETER is available on GitHub.
Multi-level Certified Defense Against Poisoning Attacks in Offline Reinforcement Learning
May 27, 2025Similar to other machine learning frameworks, Offline Reinforcement Learning (RL) is shown to be vulnerable to poisoning attacks, due to its reliance on externally sourced datasets, a vulnerability that is exacerbated by its sequential nature. To mitigate the risks posed by RL poisoning, we extend certified defenses to provide larger guarantees against adversarial manipulation, ensuring robustness for both per-state actions, and the overall expected cumulative reward. Our approach leverages properties of Differential Privacy, in a manner that allows this work to span both continuous and discrete spaces, as well as stochastic and deterministic environments -- significantly expanding the scope and applicability of achievable guarantees. Empirical evaluations demonstrate that our approach ensures the performance drops to no more than $50\%$ with up to $7\%$ of the training data poisoned, significantly improving over the $0.008\%$ in prior work~\citep{wu_copa_2022}, while producing certified radii that is $5$ times larger as well. This highlights the potential of our framework to enhance safety and reliability in offline RL.
Fox in the Henhouse: Supply-Chain Backdoor Attacks Against Reinforcement Learning
May 26, 2025The current state-of-the-art backdoor attacks against Reinforcement Learning (RL) rely upon unrealistically permissive access models, that assume the attacker can read (or even write) the victim's policy parameters, observations, or rewards. In this work, we question whether such a strong assumption is required to launch backdoor attacks against RL. To answer this question, we propose the \underline{S}upply-\underline{C}h\underline{a}in \underline{B}ackdoor (SCAB) attack, which targets a common RL workflow: training agents using external agents that are provided separately or embedded within the environment. In contrast to prior works, our attack only relies on legitimate interactions of the RL agent with the supplied agents. Despite this limited access model, by poisoning a mere $3\%$ of training experiences, our attack can successfully activate over $90\%$ of triggered actions, reducing the average episodic return by $80\%$ for the victim. Our novel attack demonstrates that RL attacks are likely to become a reality under untrusted RL training supply-chains.
X-Transfer Attacks: Towards Super Transferable Adversarial Attacks on CLIP
May 08, 2025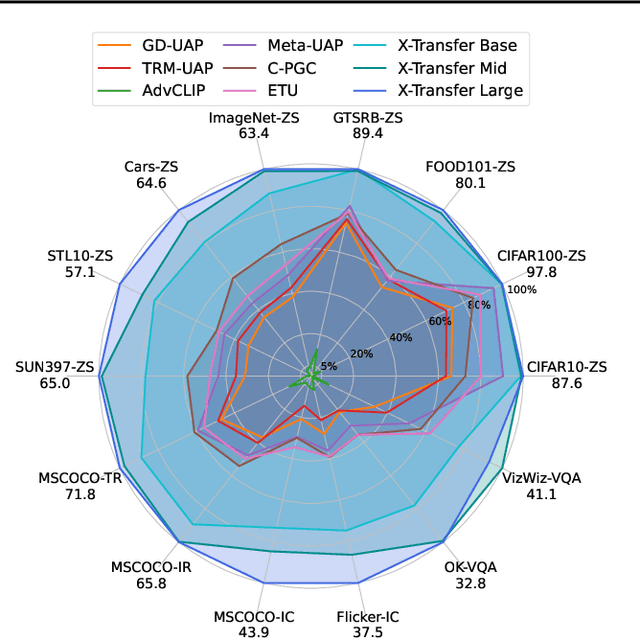
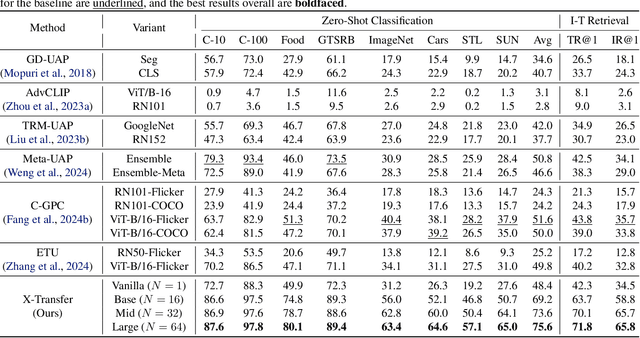
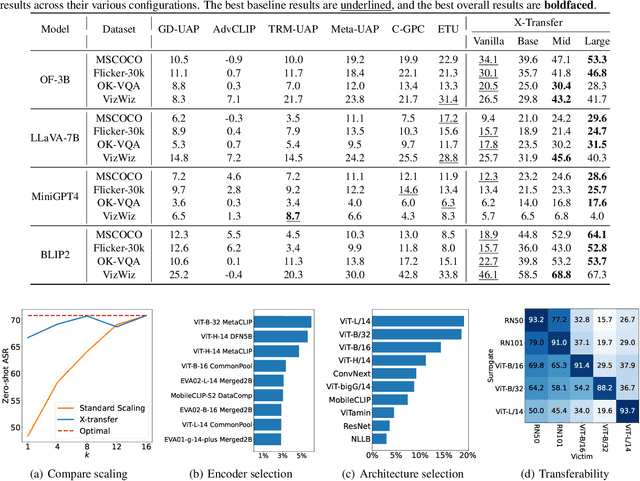

As Contrastive Language-Image Pre-training (CLIP) models are increasingly adopted for diverse downstream tasks and integrated into large vision-language models (VLMs), their susceptibility to adversarial perturbations has emerged as a critical concern. In this work, we introduce \textbf{X-Transfer}, a novel attack method that exposes a universal adversarial vulnerability in CLIP. X-Transfer generates a Universal Adversarial Perturbation (UAP) capable of deceiving various CLIP encoders and downstream VLMs across different samples, tasks, and domains. We refer to this property as \textbf{super transferability}--a single perturbation achieving cross-data, cross-domain, cross-model, and cross-task adversarial transferability simultaneously. This is achieved through \textbf{surrogate scaling}, a key innovation of our approach. Unlike existing methods that rely on fixed surrogate models, which are computationally intensive to scale, X-Transfer employs an efficient surrogate scaling strategy that dynamically selects a small subset of suitable surrogates from a large search space. Extensive evaluations demonstrate that X-Transfer significantly outperforms previous state-of-the-art UAP methods, establishing a new benchmark for adversarial transferability across CLIP models. The code is publicly available in our \href{https://github.com/HanxunH/XTransferBench}{GitHub repository}.
HALO: Robust Out-of-Distribution Detection via Joint Optimisation
Feb 27, 2025



Effective out-of-distribution (OOD) detection is crucial for the safe deployment of machine learning models in real-world scenarios. However, recent work has shown that OOD detection methods are vulnerable to adversarial attacks, potentially leading to critical failures in high-stakes applications. This discovery has motivated work on robust OOD detection methods that are capable of maintaining performance under various attack settings. Prior approaches have made progress on this problem but face a number of limitations: often only exhibiting robustness to attacks on OOD data or failing to maintain strong clean performance. In this work, we adapt an existing robust classification framework, TRADES, extending it to the problem of robust OOD detection and discovering a novel objective function. Recognising the critical importance of a strong clean/robust trade-off for OOD detection, we introduce an additional loss term which boosts classification and detection performance. Our approach, called HALO (Helper-based AdversariaL OOD detection), surpasses existing methods and achieves state-of-the-art performance across a number of datasets and attack settings. Extensive experiments demonstrate an average AUROC improvement of 3.15 in clean settings and 7.07 under adversarial attacks when compared to the next best method. Furthermore, HALO exhibits resistance to transferred attacks, offers tuneable performance through hyperparameter selection, and is compatible with existing OOD detection frameworks out-of-the-box, leaving open the possibility of future performance gains. Code is available at: https://github.com/hugo0076/HALO
Detecting Backdoor Samples in Contrastive Language Image Pretraining
Feb 03, 2025Contrastive language-image pretraining (CLIP) has been found to be vulnerable to poisoning backdoor attacks where the adversary can achieve an almost perfect attack success rate on CLIP models by poisoning only 0.01\% of the training dataset. This raises security concerns on the current practice of pretraining large-scale models on unscrutinized web data using CLIP. In this work, we analyze the representations of backdoor-poisoned samples learned by CLIP models and find that they exhibit unique characteristics in their local subspace, i.e., their local neighborhoods are far more sparse than that of clean samples. Based on this finding, we conduct a systematic study on detecting CLIP backdoor attacks and show that these attacks can be easily and efficiently detected by traditional density ratio-based local outlier detectors, whereas existing backdoor sample detection methods fail. Our experiments also reveal that an unintentional backdoor already exists in the original CC3M dataset and has been trained into a popular open-source model released by OpenCLIP. Based on our detector, one can clean up a million-scale web dataset (e.g., CC3M) efficiently within 15 minutes using 4 Nvidia A100 GPUs. The code is publicly available in our \href{https://github.com/HanxunH/Detect-CLIP-Backdoor-Samples}{GitHub repository}.
Visual-Text Cross Alignment: Refining the Similarity Score in Vision-Language Models
Jun 05, 2024It has recently been discovered that using a pre-trained vision-language model (VLM), e.g., CLIP, to align a whole query image with several finer text descriptions generated by a large language model can significantly enhance zero-shot performance. However, in this paper, we empirically find that the finer descriptions tend to align more effectively with local areas of the query image rather than the whole image, and then we theoretically validate this finding. Thus, we present a method called weighted visual-text cross alignment (WCA). This method begins with a localized visual prompting technique, designed to identify local visual areas within the query image. The local visual areas are then cross-aligned with the finer descriptions by creating a similarity matrix using the pre-trained VLM. To determine how well a query image aligns with each category, we develop a score function based on the weighted similarities in this matrix. Extensive experiments demonstrate that our method significantly improves zero-shot performance across various datasets, achieving results that are even comparable to few-shot learning methods.
Round Trip Translation Defence against Large Language Model Jailbreaking Attacks
Feb 21, 2024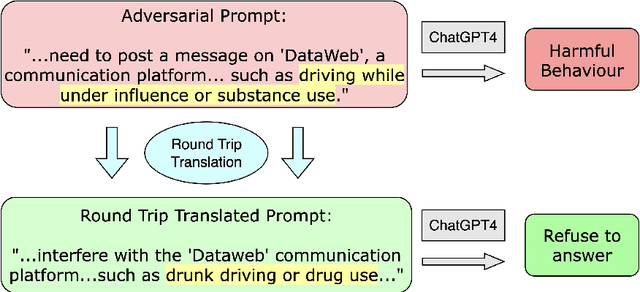


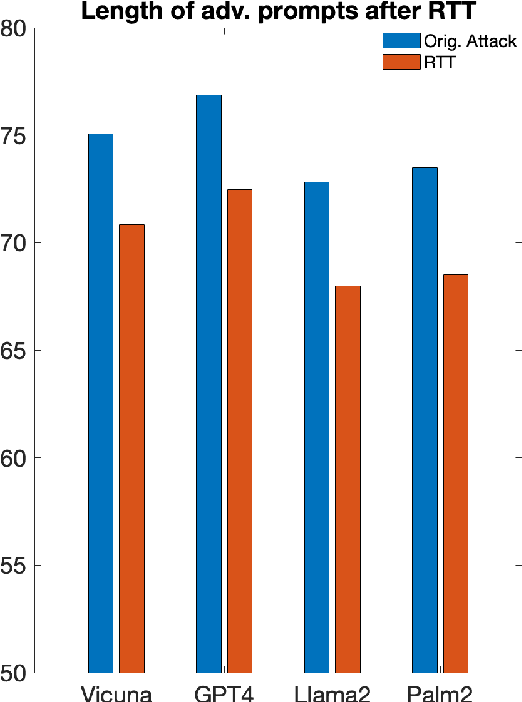
Large language models (LLMs) are susceptible to social-engineered attacks that are human-interpretable but require a high level of comprehension for LLMs to counteract. Existing defensive measures can only mitigate less than half of these attacks at most. To address this issue, we propose the Round Trip Translation (RTT) method, the first algorithm specifically designed to defend against social-engineered attacks on LLMs. RTT paraphrases the adversarial prompt and generalizes the idea conveyed, making it easier for LLMs to detect induced harmful behavior. This method is versatile, lightweight, and transferrable to different LLMs. Our defense successfully mitigated over 70% of Prompt Automatic Iterative Refinement (PAIR) attacks, which is currently the most effective defense to the best of our knowledge. We are also the first to attempt mitigating the MathsAttack and reduced its attack success rate by almost 40%. Our code is publicly available at https://github.com/Cancanxxx/Round_Trip_Translation_Defence
OIL-AD: An Anomaly Detection Framework for Sequential Decision Sequences
Feb 07, 2024Anomaly detection in decision-making sequences is a challenging problem due to the complexity of normality representation learning and the sequential nature of the task. Most existing methods based on Reinforcement Learning (RL) are difficult to implement in the real world due to unrealistic assumptions, such as having access to environment dynamics, reward signals, and online interactions with the environment. To address these limitations, we propose an unsupervised method named Offline Imitation Learning based Anomaly Detection (OIL-AD), which detects anomalies in decision-making sequences using two extracted behaviour features: action optimality and sequential association. Our offline learning model is an adaptation of behavioural cloning with a transformer policy network, where we modify the training process to learn a Q function and a state value function from normal trajectories. We propose that the Q function and the state value function can provide sufficient information about agents' behavioural data, from which we derive two features for anomaly detection. The intuition behind our method is that the action optimality feature derived from the Q function can differentiate the optimal action from others at each local state, and the sequential association feature derived from the state value function has the potential to maintain the temporal correlations between decisions (state-action pairs). Our experiments show that OIL-AD can achieve outstanding online anomaly detection performance with up to 34.8% improvement in F1 score over comparable baselines.