 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURVALID: Geometrically-guided Adversarial Prompt Detection
Mar 05, 2025Adversarial prompts capable of jailbreaking large language models (LLMs) and inducing undesirable behaviours pose a significant obstacle to their safe deployment. Current mitigation strategies rely on activating built-in defence mechanisms or fine-tuning the LLMs, but the fundamental distinctions between adversarial and benign prompts are yet to be understood. In this work, we introduce CurvaLID, a novel defense framework that efficiently detects adversarial prompts by leveraging their geometric properties. It is agnostic to the type of LLM, offering a unified detection framework across diverse adversarial prompts and LLM architectures. CurvaLID builds on the geometric analysis of text prompts to uncover their underlying differences. We theoretically extend the concept of curvature via the Whewell equation into an $n$-dimensional word embedding space, enabling us to quantify local geometric properties, including semantic shifts and curvature in the underlying manifolds. Additionally, we employ Local Intrinsic Dimensionality (LID) to capture geometric features of text prompts within adversarial subspaces. Our findings reveal that adversarial prompts differ fundamentally from benign prompts in terms of their geometric characteristics. Our results demonstrate that CurvaLID delivers superior detection and rejection of adversarial queries, paving the way for safer LLM deployment. The source code can be found at https://github.com/Cancanxxx/CurvaLID
Round Trip Translation Defence against Large Language Model Jailbreaking Attacks
Feb 21, 2024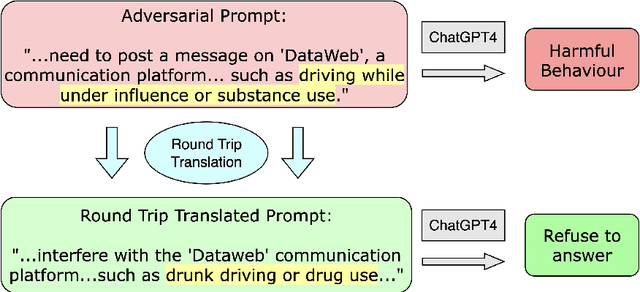


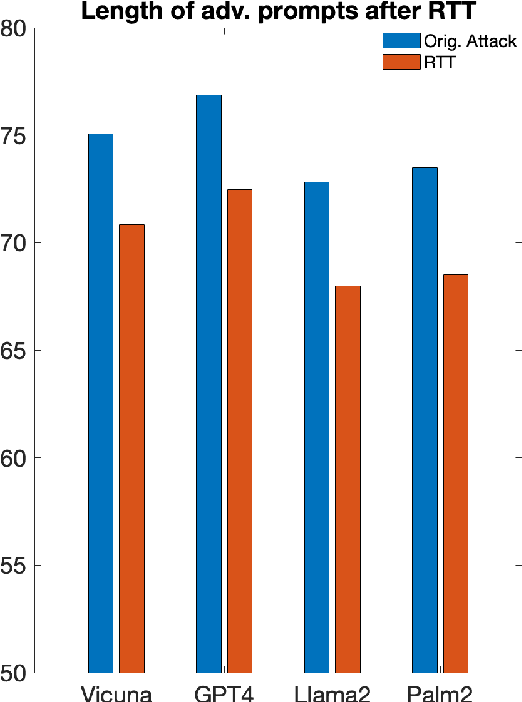
Large language models (LLMs) are susceptible to social-engineered attacks that are human-interpretable but require a high level of comprehension for LLMs to counteract. Existing defensive measures can only mitigate less than half of these attacks at most. To address this issue, we propose the Round Trip Translation (RTT) method, the first algorithm specifically designed to defend against social-engineered attacks on LLMs. RTT paraphrases the adversarial prompt and generalizes the idea conveyed, making it easier for LLMs to detect induced harmful behavior. This method is versatile, lightweight, and transferrable to different LLMs. Our defense successfully mitigated over 70% of Prompt Automatic Iterative Refinement (PAIR) attacks, which is currently the most effective defense to the best of our knowledge. We are also the first to attempt mitigating the MathsAttack and reduced its attack success rate by almost 40%. Our code is publicly available at https://github.com/Cancanxxx/Round_Trip_Translation_Defence
Clustering by Contour coreset and variational quantum eigensolver
Dec 06, 2023Recent work has proposed solving the k-means clustering problem on quantum computers via the Quantum Approximate Optimization Algorithm (QAOA) and coreset techniques. Although the current method demonstrates the possibility of quantum k-means clustering, it does not ensure high accuracy and consistency across a wide range of datasets. The existing coreset techniques are designed for classical algorithms and there has been no quantum-tailored coreset technique which is designed to boost the accuracy of quantum algorithms. In this work, we propose solving the k-means clustering problem with the variational quantum eigensolver (VQE) and a customised coreset method, the Contour coreset, which has been formulated with specific focus on quantum algorithms. Extensive simulations with synthetic and real-life data demonstrated that our VQE+Contour Coreset approach outperforms existing QAOA+Coreset k-means clustering approaches with higher accuracy and lower standard deviation. Our work has shown that quantum tailored coreset techniques has the potential to significantly boost the performance of quantum algorithms when compared to using generic off-the-shelf coreset techniques.