 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention in Space: Functional Roles of VLM Heads for Spatial Reasoning
Mar 21, 2026Despite remarkable advances in large Vision-Language Models (VLMs), spatial reasoning remains a persistent challenge. In this work, we investigate how attention heads within VLMs contribute to spatial reasoning by analyzing their functional roles through a mechanistic interpretability lens. We introduce CogVSR, a dataset that decomposes complex spatial reasoning questions into step-by-step subquestions designed to simulate human-like reasoning via a chain-of-thought paradigm, with each subquestion linked to specific cognitive functions such as spatial perception or relational reasoning. Building on CogVSR, we develop a probing framework to identify and characterize attention heads specialized for these functions. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions. Notably, spatially specialized heads are fewer than those for other cognitive functions, highlighting their scarcity. We propose methods to activate latent spatial heads, improving spatial understanding. Intervention experiments further demonstrate their critical role in spatial reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. This study provides new interpretability driven insights into how VLMs attend to space and paves the way for enhancing complex spatial reasoning in multimodal models.
Coarse-to-Fine Open-Set Graph Node Classification with Large Language Models
Dec 21, 2025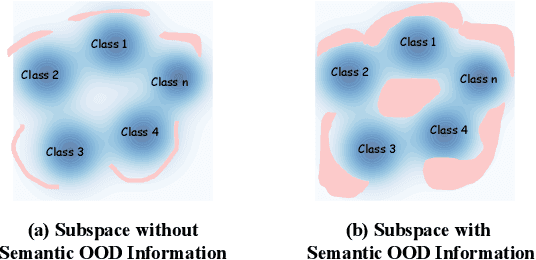
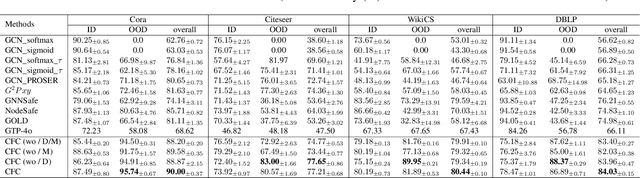

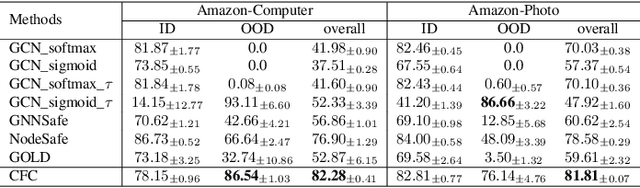
Developing open-set classification methods capable of classifying in-distribution (ID) data while detecting out-of-distribution (OOD) samples is essential for deploying graph neural networks (GNNs) in open-world scenarios. Existing methods typically treat all OOD samples as a single class, despite real-world applications, especially high-stake settings such as fraud detection and medical diagnosis, demanding deeper insights into OOD samples, including their probable labels. This raises a critical question: can OOD detection be extended to OOD classification without true label information? To address this question, we propose a Coarse-to-Fine open-set Classification (CFC) framework that leverages large language models (LLMs) for graph datasets. CFC consists of three key components: a coarse classifier that uses LLM prompts for OOD detection and outlier label generation, a GNN-based fine classifier trained with OOD samples identified by the coarse classifier for enhanced OOD detection and ID classification, and refined OOD classification achieved through LLM prompts and post-processed OOD labels. Unlike methods that rely on synthetic or auxiliary OOD samples, CFC employs semantic OOD instances that are genuinely out-of-distribution based on their inherent meaning, improving interpretability and practical utility. Experimental results show that CFC improves OOD detection by ten percent over state-of-the-art methods on graph and text domains and achieves up to seventy percent accuracy in OOD classification on graph datasets.
Investigating The Functional Roles of Attention Heads in Vision Language Models: Evidence for Reasoning Modules
Dec 11, 2025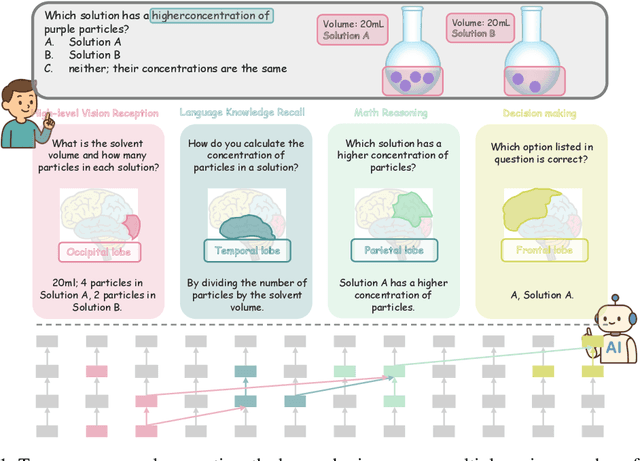
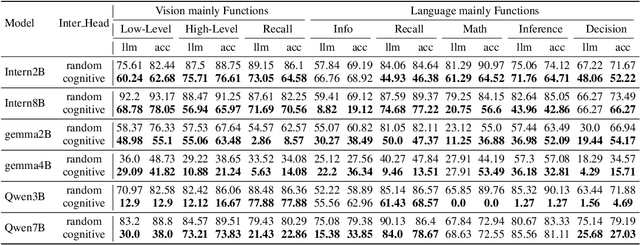
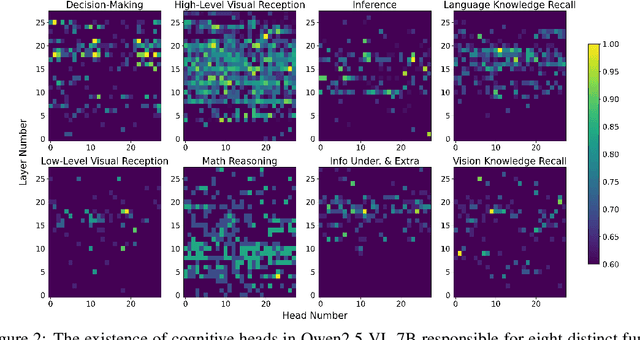

Despite excelling on multimodal benchmarks, vision-language models (VLMs) largely remain a black box. In this paper, we propose a novel interpretability framework to systematically analyze the internal mechanisms of VLMs, focusing on the functional roles of attention heads in multimodal reasoning. To this end, we introduce CogVision, a dataset that decomposes complex multimodal questions into step-by-step subquestions designed to simulate human reasoning through a chain-of-thought paradigm, with each subquestion associated with specific receptive or cognitive functions such as high-level visual reception and inference. Using a probing-based methodology, we identify attention heads that specialize in these functions and characterize them as functional heads. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions, and mediate interactions and hierarchical organization. Furthermore, intervention experiments demonstrate their critical role in multimodal reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. These findings provide new insights into the cognitive organization of VLMs and suggest promising directions for designing models with more human-aligned perceptual and reasoning abilities.
CURVALID: Geometrically-guided Adversarial Prompt Detection
Mar 05, 2025Adversarial prompts capable of jailbreaking large language models (LLMs) and inducing undesirable behaviours pose a significant obstacle to their safe deployment. Current mitigation strategies rely on activating built-in defence mechanisms or fine-tuning the LLMs, but the fundamental distinctions between adversarial and benign prompts are yet to be understood. In this work, we introduce CurvaLID, a novel defense framework that efficiently detects adversarial prompts by leveraging their geometric properties. It is agnostic to the type of LLM, offering a unified detection framework across diverse adversarial prompts and LLM architectures. CurvaLID builds on the geometric analysis of text prompts to uncover their underlying differences. We theoretically extend the concept of curvature via the Whewell equation into an $n$-dimensional word embedding space, enabling us to quantify local geometric properties, including semantic shifts and curvature in the underlying manifolds. Additionally, we employ Local Intrinsic Dimensionality (LID) to capture geometric features of text prompts within adversarial subspaces. Our findings reveal that adversarial prompts differ fundamentally from benign prompts in terms of their geometric characteristics. Our results demonstrate that CurvaLID delivers superior detection and rejection of adversarial queries, paving the way for safer LLM deployment. The source code can be found at https://github.com/Cancanxxx/CurvaLID
Efficient Neural Implicit Representation for 3D Human Reconstruction
Oct 23, 2024High-fidelity digital human representations are increasingly in demand in the digital world, particularly for interactive telepresence, AR/VR, 3D graphics, and the rapidly evolving metaverse. Even though they work well in small spaces, conventional methods for reconstructing 3D human motion frequently require the use of expensive hardware and have high processing costs. This study presents HumanAvatar, an innovative approach that efficiently reconstructs precise human avatars from monocular video sources. At the core of our methodology, we integrate the pre-trained HuMoR, a model celebrated for its proficiency in human motion estimation. This is adeptly fused with the cutting-edge neural radiance field technology, Instant-NGP, and the state-of-the-art articulated model, Fast-SNARF, to enhance the reconstruction fidelity and speed. By combining these two technologies, a system is created that can render quickly and effectively while also providing estimation of human pose parameters that are unmatched in accuracy. We have enhanced our system with an advanced posture-sensitive space reduction technique, which optimally balances rendering quality with computational efficiency. In our detailed experimental analysis using both artificial and real-world monocular videos, we establish the advanced performance of our approach. HumanAvatar consistently equals or surpasses contemporary leading-edge reconstruction techniques in quality. Furthermore, it achieves these complex reconstructions in minutes, a fraction of the time typically required by existing methods. Our models achieve a training speed that is 110X faster than that of State-of-The-Art (SoTA) NeRF-based models. Our technique performs noticeably better than SoTA dynamic human NeRF methods if given an identical runtime limit. HumanAvatar can provide effective visuals after only 30 seconds of training.
Unlearnable Examples For Time Series
Feb 03, 2024Unlearnable examples (UEs) refer to training samples modified to be unlearnable to Deep Neural Networks (DNNs). These examples are usually generated by adding error-minimizing noises that can fool a DNN model into believing that there is nothing (no error) to learn from the data. The concept of UE has been proposed as a countermeasure against unauthorized data exploitation on personal data. While UE has been extensively studied on images, it is unclear how to craft effective UEs for time series data. In this work, we introduce the first UE generation method to protect time series data from unauthorized training by deep learning models. To this end, we propose a new form of error-minimizing noise that can be \emph{selectively} applied to specific segments of time series, rendering them unlearnable to DNN models while remaining imperceptible to human observers. Through extensive experiments on a wide range of time series datasets, we demonstrate that the proposed UE generation method is effective in both classification and generation tasks. It can protect time series data against unauthorized exploitation, while preserving their utility for legitimate usage, thereby contributing to the development of secure and trustworthy machine learning systems.
LDReg: Local Dimensionality Regularized Self-Supervised Learning
Jan 19, 2024



Representations learned via self-supervised learning (SSL) can be susceptible to dimensional collapse, where the learned representation subspace is of extremely low dimensionality and thus fails to represent the full data distribution and modalities. Dimensional collapse also known as the "underfilling" phenomenon is one of the major causes of degraded performance on downstream tasks. Previous work has investigated the dimensional collapse problem of SSL at a global level. In this paper, we demonstrate that representations can span over high dimensional space globally, but collapse locally. To address this, we propose a method called $\textit{local dimensionality regularization (LDReg)}$. Our formulation is based on the derivation of the Fisher-Rao metric to compare and optimize local distance distributions at an asymptotically small radius for each data point. By increasing the local intrinsic dimensionality, we demonstrate through a range of experiments that LDReg improves the representation quality of SSL. The results also show that LDReg can regularize dimensionality at both local and global levels.
End-to-End Anti-Backdoor Learning on Images and Time Series
Jan 06, 2024Backdoor attacks present a substantial security concern for deep learning models, especially those utilized in applications critical to safety and security. These attacks manipulate model behavior by embedding a hidden trigger during the training phase, allowing unauthorized control over the model's output during inference time. Although numerous defenses exist for image classification models, there is a conspicuous absence of defenses tailored for time series data, as well as an end-to-end solution capable of training clean models on poisoned data. To address this gap, this paper builds upon Anti-Backdoor Learning (ABL) and introduces an innovative method, End-to-End Anti-Backdoor Learning (E2ABL), for robust training against backdoor attacks. Unlike the original ABL, which employs a two-stage training procedure, E2ABL accomplishes end-to-end training through an additional classification head linked to the shallow layers of a Deep Neural Network (DNN). This secondary head actively identifies potential backdoor triggers, allowing the model to dynamically cleanse these samples and their corresponding labels during training. Our experiments reveal that E2ABL significantly improves on existing defenses and is effective against a broad range of backdoor attacks in both image and time series domains.
Backdoor Attacks on Time Series: A Generative Approach
Dec 07, 2022Backdoor attacks have emerged as one of the major security threats to deep learning models as they can easily control the model's test-time predictions by pre-injecting a backdoor trigger into the model at training time. While backdoor attacks have been extensively studied on images, few works have investigated the threat of backdoor attacks on time series data. To fill this gap, in this paper we present a novel generative approach for time series backdoor attacks against deep learning based time series classifiers. Backdoor attacks have two main goals: high stealthiness and high attack success rate. We find that, compared to images, it can be more challenging to achieve the two goals on time series. This is because time series have fewer input dimensions and lower degrees of freedom, making it hard to achieve a high attack success rate without compromising stealthiness. Our generative approach addresses this challenge by generating trigger patterns that are as realistic as real-time series patterns while achieving a high attack success rate without causing a significant drop in clean accuracy. We also show that our proposed attack is resistant to potential backdoor defenses. Furthermore, we propose a novel universal generator that can poison any type of time series with a single generator that allows universal attacks without the need to fine-tune the generative model for new time series datasets.
Exploring Architectural Ingredients of Adversarially Robust Deep Neural Networks
Oct 21, 2021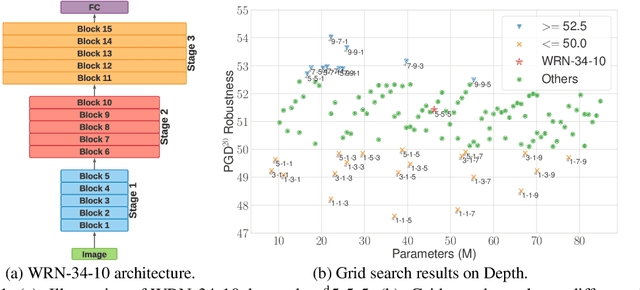
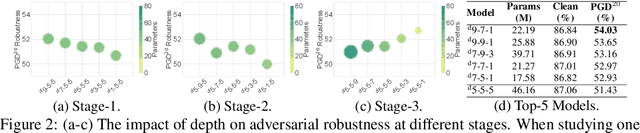
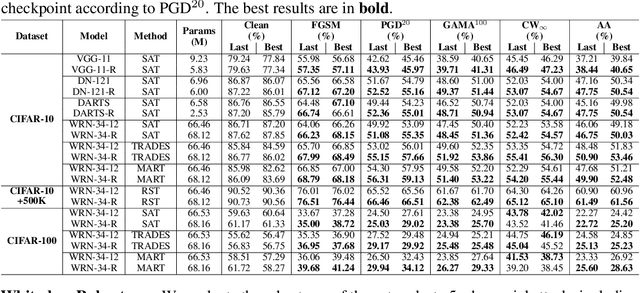
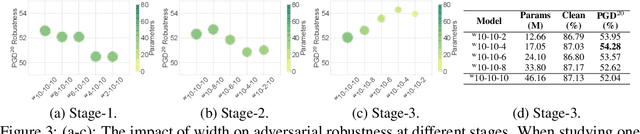
Deep neural networks (DNNs) are known to be vulnerable to adversarial attacks. A range of defense methods have been proposed to train adversarially robust DNNs, among which adversarial training has demonstrated promising results. However, despite preliminary understandings developed for adversarial training, it is still not clear, from the architectural perspective, what configurations can lead to more robust DNNs. In this paper, we address this gap via a comprehensive investigation on the impact of network width and depth on the robustness of adversarially trained DNNs. Specifically, we make the following key observations: 1) more parameters (higher model capacity) does not necessarily help adversarial robustness; 2) reducing capacity at the last stage (the last group of blocks) of the network can actually improve adversarial robustness; and 3) under the same parameter budget, there exists an optimal architectural configuration for adversarial robustness. We also provide a theoretical analysis explaning why such network configuration can help robustness. These architectural insights can help design adversarially robust DNNs. Code is available at \url{https://github.com/HanxunH/RobustWRN}.