 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearnable Examples For Time Series
Feb 03, 2024Unlearnable examples (UEs) refer to training samples modified to be unlearnable to Deep Neural Networks (DNNs). These examples are usually generated by adding error-minimizing noises that can fool a DNN model into believing that there is nothing (no error) to learn from the data. The concept of UE has been proposed as a countermeasure against unauthorized data exploitation on personal data. While UE has been extensively studied on images, it is unclear how to craft effective UEs for time series data. In this work, we introduce the first UE generation method to protect time series data from unauthorized training by deep learning models. To this end, we propose a new form of error-minimizing noise that can be \emph{selectively} applied to specific segments of time series, rendering them unlearnable to DNN models while remaining imperceptible to human observers. Through extensive experiments on a wide range of time series datasets, we demonstrate that the proposed UE generation method is effective in both classification and generation tasks. It can protect time series data against unauthorized exploitation, while preserving their utility for legitimate usage, thereby contributing to the development of secure and trustworthy machine learning systems.
End-to-End Anti-Backdoor Learning on Images and Time Series
Jan 06, 2024Backdoor attacks present a substantial security concern for deep learning models, especially those utilized in applications critical to safety and security. These attacks manipulate model behavior by embedding a hidden trigger during the training phase, allowing unauthorized control over the model's output during inference time. Although numerous defenses exist for image classification models, there is a conspicuous absence of defenses tailored for time series data, as well as an end-to-end solution capable of training clean models on poisoned data. To address this gap, this paper builds upon Anti-Backdoor Learning (ABL) and introduces an innovative method, End-to-End Anti-Backdoor Learning (E2ABL), for robust training against backdoor attacks. Unlike the original ABL, which employs a two-stage training procedure, E2ABL accomplishes end-to-end training through an additional classification head linked to the shallow layers of a Deep Neural Network (DNN). This secondary head actively identifies potential backdoor triggers, allowing the model to dynamically cleanse these samples and their corresponding labels during training. Our experiments reveal that E2ABL significantly improves on existing defenses and is effective against a broad range of backdoor attacks in both image and time series domains.
Backdoor Attacks on Time Series: A Generative Approach
Dec 07, 2022Backdoor attacks have emerged as one of the major security threats to deep learning models as they can easily control the model's test-time predictions by pre-injecting a backdoor trigger into the model at training time. While backdoor attacks have been extensively studied on images, few works have investigated the threat of backdoor attacks on time series data. To fill this gap, in this paper we present a novel generative approach for time series backdoor attacks against deep learning based time series classifiers. Backdoor attacks have two main goals: high stealthiness and high attack success rate. We find that, compared to images, it can be more challenging to achieve the two goals on time series. This is because time series have fewer input dimensions and lower degrees of freedom, making it hard to achieve a high attack success rate without compromising stealthiness. Our generative approach addresses this challenge by generating trigger patterns that are as realistic as real-time series patterns while achieving a high attack success rate without causing a significant drop in clean accuracy. We also show that our proposed attack is resistant to potential backdoor defenses. Furthermore, we propose a novel universal generator that can poison any type of time series with a single generator that allows universal attacks without the need to fine-tune the generative model for new time series datasets.
Dual Head Adversarial Training
Apr 22, 2021
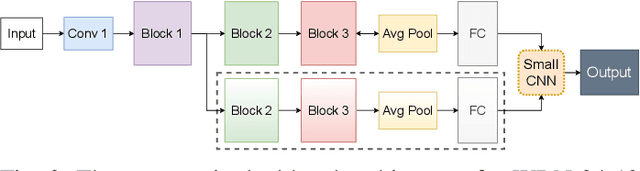
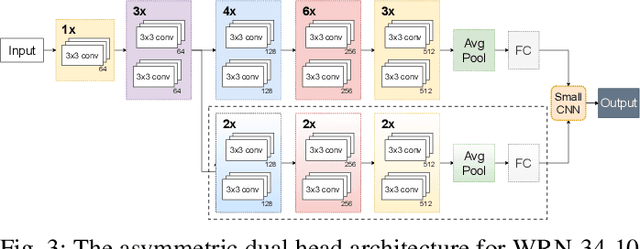
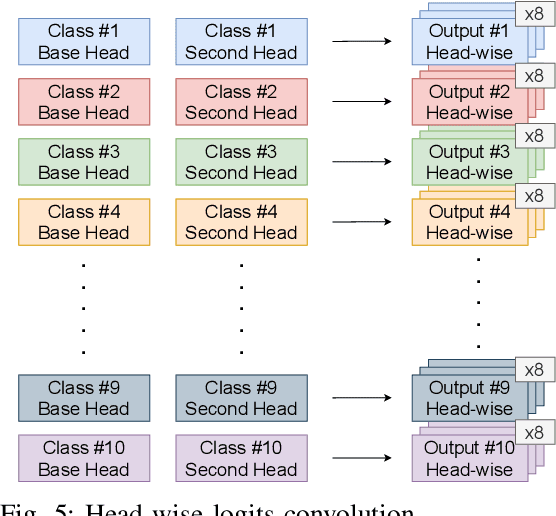
Deep neural networks (DNNs) are known to be vulnerable to adversarial examples/attacks, raising concerns about their reliability in safety-critical applications. A number of defense methods have been proposed to train robust DNNs resistant to adversarial attacks, among which adversarial training has so far demonstrated the most promising results. However, recent studies have shown that there exists an inherent tradeoff between accuracy and robustness in adversarially-trained DNNs. In this paper, we propose a novel technique Dual Head Adversarial Training (DH-AT) to further improve the robustness of existing adversarial training methods. Different from existing improved variants of adversarial training, DH-AT modifies both the architecture of the network and the training strategy to seek more robustness. Specifically, DH-AT first attaches a second network head (or branch) to one intermediate layer of the network, then uses a lightweight convolutional neural network (CNN) to aggregate the outputs of the two heads. The training strategy is also adapted to reflect the relative importance of the two heads. We empirically show, on multiple benchmark datasets, that DH-AT can bring notable robustness improvements to existing adversarial training methods. Compared with TRADES, one state-of-the-art adversarial training method, our DH-AT can improve the robustness by 3.4% against PGD40 and 2.3% against AutoAttack, and also improve the clean accuracy by 1.8%.