 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Low-Rank LeArning (Bella): A Practical Approach to Bayesian Neural Networks
Paper and Code
Jul 30, 2024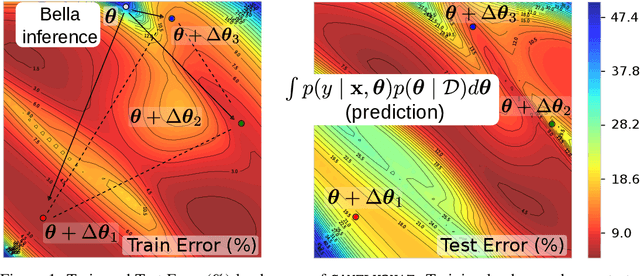

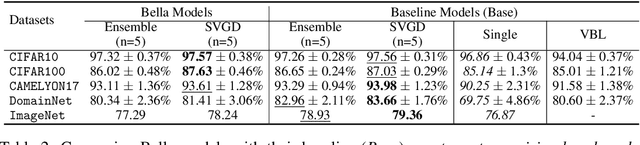

Computational complexity of Bayesian learning is impeding its adoption in practical, large-scale tasks. Despite demonstrations of significant merits such as improved robustness and resilience to unseen or out-of-distribution inputs over their non- Bayesian counterparts, their practical use has faded to near insignificance. In this study, we introduce an innovative framework to mitigate the computational burden of Bayesian neural networks (BNNs). Our approach follows the principle of Bayesian techniques based on deep ensembles, but significantly reduces their cost via multiple low-rank perturbations of parameters arising from a pre-trained neural network. Both vanilla version of ensembles as well as more sophisticated schemes such as Bayesian learning with Stein Variational Gradient Descent (SVGD), previously deemed impractical for large models, can be seamlessly implemented within the proposed framework, called Bayesian Low-Rank LeArning (Bella). In a nutshell, i) Bella achieves a dramatic reduction in the number of trainable parameters required to approximate a Bayesian posterior; and ii) it not only maintains, but in some instances, surpasses the performance of conventional Bayesian learning methods and non-Bayesian baselines. Our results with large-scale tasks such as ImageNet, CAMELYON17, DomainNet, VQA with CLIP, LLaVA demonstrate the effectiveness and versatility of Bella in building highly scalable and practical Bayesian deep models for real-world applications.