 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High-Fidelity Text-Guided 3D Face Generation and Manipulation Using only Images
Aug 31, 2023
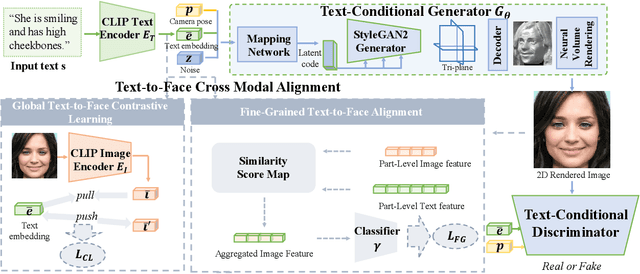
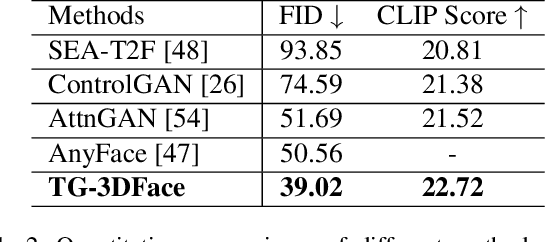

Generating 3D faces from textual descriptions has a multitude of applications, such as gaming, movie, and robotics. Recent progresses have demonstrated the success of unconditional 3D face generation and text-to-3D shape generation. However, due to the limited text-3D face data pairs, text-driven 3D face generation remains an open problem. In this paper, we propose a text-guided 3D faces generation method, refer as TG-3DFace, for generating realistic 3D faces using text guidance. Specifically, we adopt an unconditional 3D face generation framework and equip it with text conditions, which learns the text-guided 3D face generation with only text-2D face data. On top of that, we propose two text-to-face cross-modal alignment techniques, including the global contrastive learning and the fine-grained alignment module, to facilitate high semantic consistency between generated 3D faces and input texts. Besides, we present directional classifier guidance during the inference process, which encourages creativity for out-of-domain generations. Compared to the existing methods, TG-3DFace creates more realistic and aesthetically pleasing 3D faces, boosting 9% multi-view consistency (MVIC) over Latent3D. The rendered face images generated by TG-3DFace achieve higher FID and CLIP score than text-to-2D face/image generation models, demonstrating our superiority in generating realistic and semantic-consistent textures.
Reconstructing A Large Scale 3D Face Dataset for Deep 3D Face Identification
Oct 16, 2020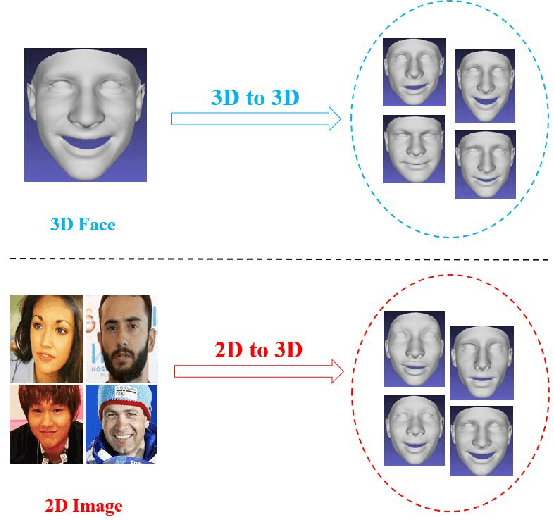
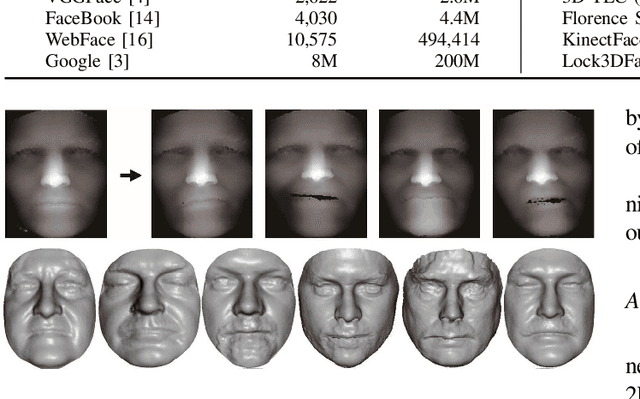


Deep learning methods have brought many breakthroughs to computer vision, especially in 2D face recognition. However, the bottleneck of deep learning based 3D face recognition is that it is difficult to collect millions of 3D faces, whether for industry or academia. In view of this situation, there are many methods to generate more 3D faces from existing 3D faces through 3D face data augmentation, which are used to train deep 3D face recognition models. However, to the best of our knowledge, there is no method to generate 3D faces from 2D face images for training deep 3D face recognition models. This letter focuses on the role of reconstructed 3D facial surfaces in 3D face identification and proposes a framework of 2D-aided deep 3D face identification. In particular, we propose to reconstruct millions of 3D face scans from a large scale 2D face database (i.e.VGGFace2), using a deep learning based 3D face reconstruction method (i.e.ExpNet). Then, we adopt a two-phase training approach: In the first phase, we use millions of face images to pre-train the deep convolutional neural network (DCNN), and in the second phase, we use normal component images (NCI) of reconstructed 3D face scans to train the DCNN. Extensive experimental results illustrate that the proposed approach can greatly improve the rank-1 score of 3D face identification on the FRGC v2.0, the Bosphorus, and the BU-3DFE 3D face databases, compared to the model trained by 2D face images. Finally, our proposed approach achieves state-of-the-art rank-1 scores on the FRGC v2.0 (97.6%), Bosphorus (98.4%), and BU-3DFE (98.8%) databases. The experimental results show that the reconstructed 3D facial surfaces are useful and our 2D-aided deep 3D face identification framework is meaningful, facing the scarcity of 3D faces.