 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Multiple Chain-of-Thought in Contrastive Reasoning for Implicit Sentiment Analysis
Mar 10, 2025
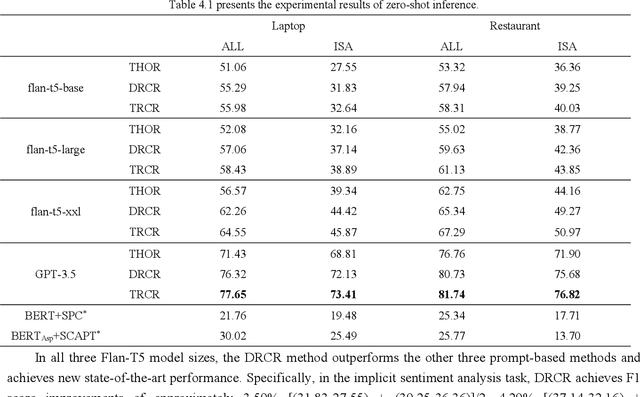
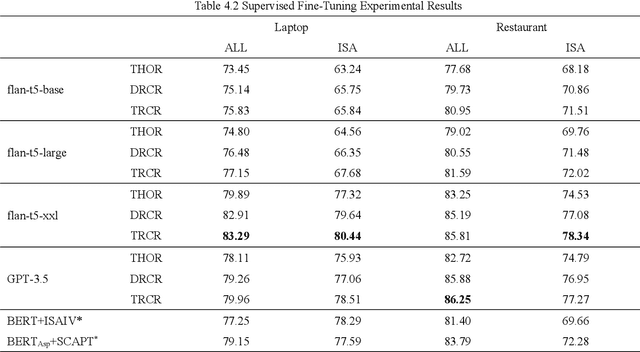
Implicit sentiment analysis aims to uncover emotions that are subtly expressed, often obscured by ambiguity and figurative language. To accomplish this task, large language models and multi-step reasoning are needed to identify those sentiments that are not explicitly stated. In this study, we propose a novel Dual Reverse Chain Reasoning (DRCR) framework to enhance the performance of implicit sentiment analysis. Inspired by deductive reasoning, the framework consists of three key steps: 1) hypothesize an emotional polarity and derive a reasoning process, 2) negate the initial hypothesis and derive a new reasoning process, and 3) contrast the two reasoning paths to deduce the final sentiment polarity. Building on this, we also introduce a Triple Reverse Chain Reasoning (TRCR) framework to address the limitations of random hypotheses. Both methods combine contrastive mechanisms and multi-step reasoning, significantly improving the accuracy of implicit sentiment classification. Experimental results demonstrate that both approaches outperform existing methods across various model scales, achieving state-of-the-art performance. This validates the effectiveness of combining contrastive reasoning and multi-step reasoning for implicit sentiment analysis.
Optimal Transport-Guided Conditional Score-Based Diffusion Models
Nov 02, 2023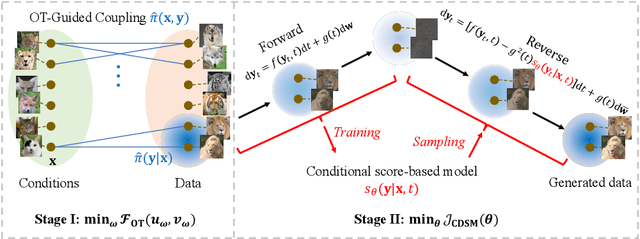
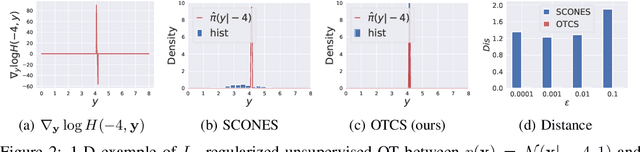


Conditional score-based diffusion model (SBDM) is for conditional generation of target data with paired data as condition, and has achieved great success in image translation. However, it requires the paired data as condition, and there would be insufficient paired data provided in real-world applications. To tackle the applications with partially paired or even unpaired dataset, we propose a novel Optimal Transport-guided Conditional Score-based diffusion model (OTCS) in this paper. We build the coupling relationship for the unpaired or partially paired dataset based on $L_2$-regularized unsupervised or semi-supervised optimal transport, respectively. Based on the coupling relationship, we develop the objective for training the conditional score-based model for unpaired or partially paired settings, which is based on a reformulation and generalization of the conditional SBDM for paired setting. With the estimated coupling relationship, we effectively train the conditional score-based model by designing a ``resampling-by-compatibility'' strategy to choose the sampled data with high compatibility as guidance. Extensive experiments on unpaired super-resolution and semi-paired image-to-image translation demonstrated the effectiveness of the proposed OTCS model. From the viewpoint of optimal transport, OTCS provides an approach to transport data across distributions, which is a challenge for OT on large-scale datasets. We theoretically prove that OTCS realizes the data transport in OT with a theoretical bound. Code is available at \url{https://github.com/XJTU-XGU/OTCS}.
DeepFire2: A Convolutional Spiking Neural Network Accelerator on FPGAs
May 09, 2023



Brain-inspired spiking neural networks (SNNs) replace the multiply-accumulate operations of traditional neural networks by integrate-and-fire neurons, with the goal of achieving greater energy efficiency. Specialized hardware implementations of those neurons clearly have advantages over general-purpose devices in terms of power and performance, but exhibit poor scalability when it comes to accelerating large neural networks. DeepFire2 introduces a hardware architecture which can map large network layers efficiently across multiple super logic regions in a multi-die FPGA. That gives more control over resource allocation and parallelism, benefiting both throughput and energy consumption. Avoiding the use of lookup tables to implement the AND operations of an SNN, prevents the layer size to be limited by logic resources. A deep pipeline does not only lead to an increased clock speed of up to 600 MHz. We double the throughput and power efficiency compared to our previous version of DeepFire, which equates to an almost 10-fold improvement over other previous implementations. Importantly, we are able to deploy a large ImageNet model, while maintaining a throughput of over 1500 frames per second.
Generalized Semantic Segmentation by Self-Supervised Source Domain Projection and Multi-Level Contrastive Learning
Mar 03, 2023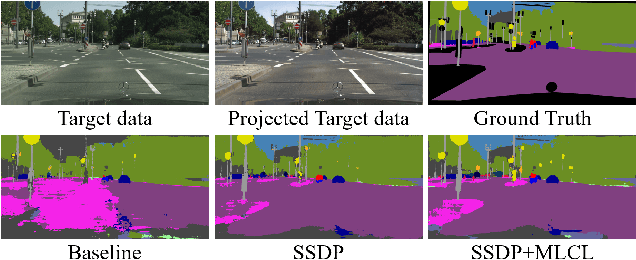
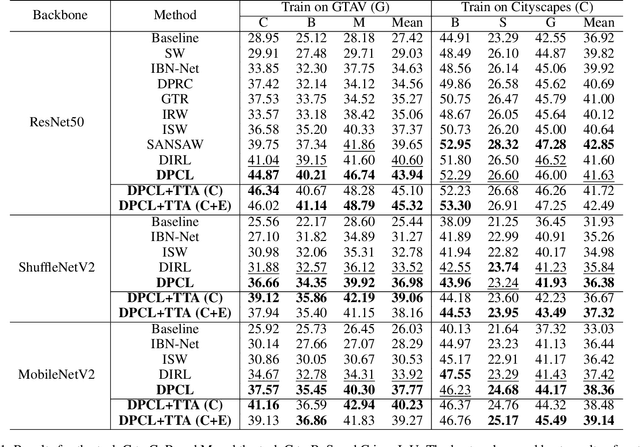
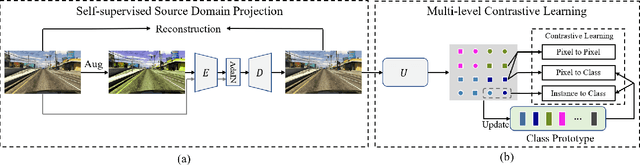

Deep networks trained on the source domain show degraded performance when tested on unseen target domain data. To enhance the model's generalization ability, most existing domain generalization methods learn domain invariant features by suppressing domain sensitive features. Different from them, we propose a Domain Projection and Contrastive Learning (DPCL) approach for generalized semantic segmentation, which includes two modules: Self-supervised Source Domain Projection (SSDP) and Multi-level Contrastive Learning (MLCL). SSDP aims to reduce domain gap by projecting data to the source domain, while MLCL is a learning scheme to learn discriminative and generalizable features on the projected data. During test time, we first project the target data by SSDP to mitigate domain shift, then generate the segmentation results by the learned segmentation network based on MLCL. At test time, we can update the projected data by minimizing our proposed pixel-to-pixel contrastive loss to obtain better results. Extensive experiments for semantic segmentation demonstrate the favorable generalization capability of our method on benchmark datasets.
A Unified Hyper-GAN Model for Unpaired Multi-contrast MR Image Translation
Jul 26, 2021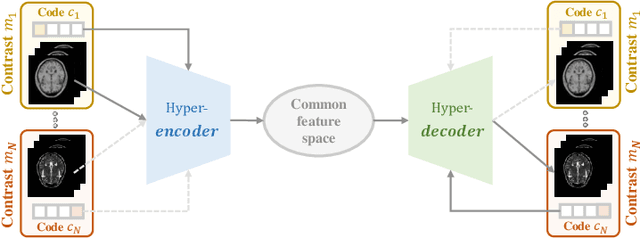
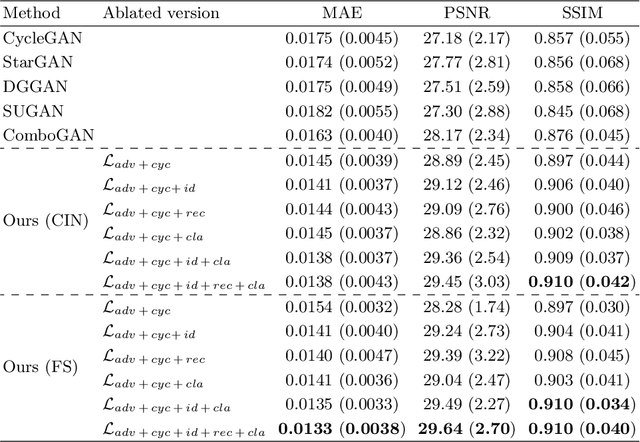
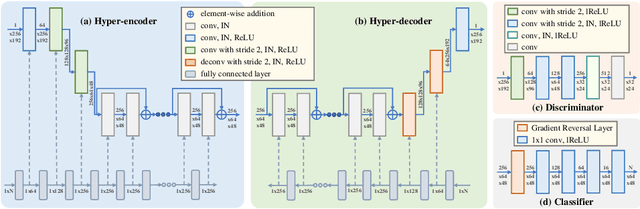
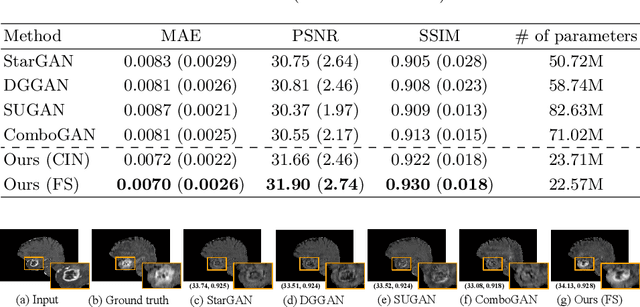
Cross-contrast image translation is an important task for completing missing contrasts in clinical diagnosis. However, most existing methods learn separate translator for each pair of contrasts, which is inefficient due to many possible contrast pairs in real scenarios. In this work, we propose a unified Hyper-GAN model for effectively and efficiently translating between different contrast pairs. Hyper-GAN consists of a pair of hyper-encoder and hyper-decoder to first map from the source contrast to a common feature space, and then further map to the target contrast image. To facilitate the translation between different contrast pairs, contrast-modulators are designed to tune the hyper-encoder and hyper-decoder adaptive to different contrasts. We also design a common space loss to enforce that multi-contrast images of a subject share a common feature space, implicitly modeling the shared underlying anatomical structures. Experiments on two datasets of IXI and BraTS 2019 show that our Hyper-GAN achieves state-of-the-art results in both accuracy and efficiency, e.g., improving more than 1.47 and 1.09 dB in PSNR on two datasets with less than half the amount of parameters.