 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFire2: A Convolutional Spiking Neural Network Accelerator on FPGAs
May 09, 2023



Brain-inspired spiking neural networks (SNNs) replace the multiply-accumulate operations of traditional neural networks by integrate-and-fire neurons, with the goal of achieving greater energy efficiency. Specialized hardware implementations of those neurons clearly have advantages over general-purpose devices in terms of power and performance, but exhibit poor scalability when it comes to accelerating large neural networks. DeepFire2 introduces a hardware architecture which can map large network layers efficiently across multiple super logic regions in a multi-die FPGA. That gives more control over resource allocation and parallelism, benefiting both throughput and energy consumption. Avoiding the use of lookup tables to implement the AND operations of an SNN, prevents the layer size to be limited by logic resources. A deep pipeline does not only lead to an increased clock speed of up to 600 MHz. We double the throughput and power efficiency compared to our previous version of DeepFire, which equates to an almost 10-fold improvement over other previous implementations. Importantly, we are able to deploy a large ImageNet model, while maintaining a throughput of over 1500 frames per second.
Desire Backpropagation: A Lightweight Training Algorithm for Multi-Layer Spiking Neural Networks based on Spike-Timing-Dependent Plasticity
Nov 10, 2022

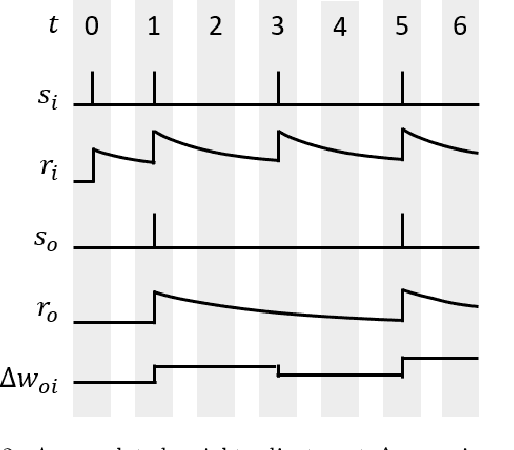

Spiking neural networks (SNN) are a viable alternative to conventional artificial neural networks when energy efficiency and computational complexity are of importance. A major advantage of SNNs is their binary information transfer through spike trains. The training of SNN has, however, been a challenge, since neuron models are non-differentiable and traditional gradient-based backpropagation algorithms cannot be applied directly. Furthermore, spike-timing-dependent plasticity (STDP), albeit being a spike-based learning rule, updates weights locally and does not optimize for the output error of the network. We present desire backpropagation, a method to derive the desired spike activity of neurons from the output error. The loss function can then be evaluated locally for every neuron. Incorporating the desire values into the STDP weight update leads to global error minimization and increasing classification accuracy. At the same time, the neuron dynamics and computational efficiency of STDP are maintained, making it a spike-based supervised learning rule. We trained three-layer networks to classify MNIST and Fashion-MNIST images and reached an accuracy of 98.41% and 87.56%, respectively. Furthermore, we show that desire backpropagation is computationally less complex than backpropagation in traditional neural networks.
A Resource-efficient Spiking Neural Network Accelerator Supporting Emerging Neural Encoding
Jun 06, 2022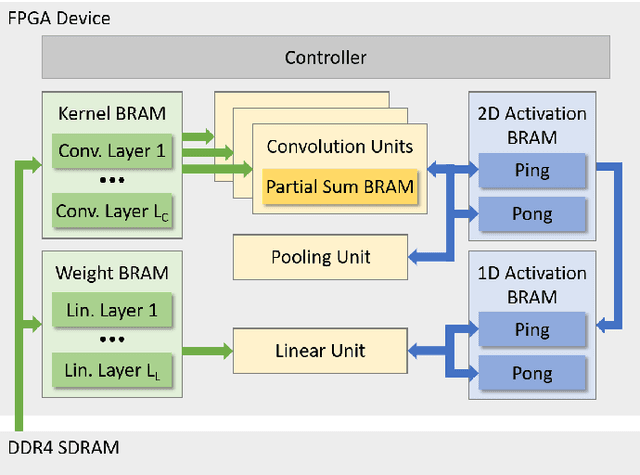
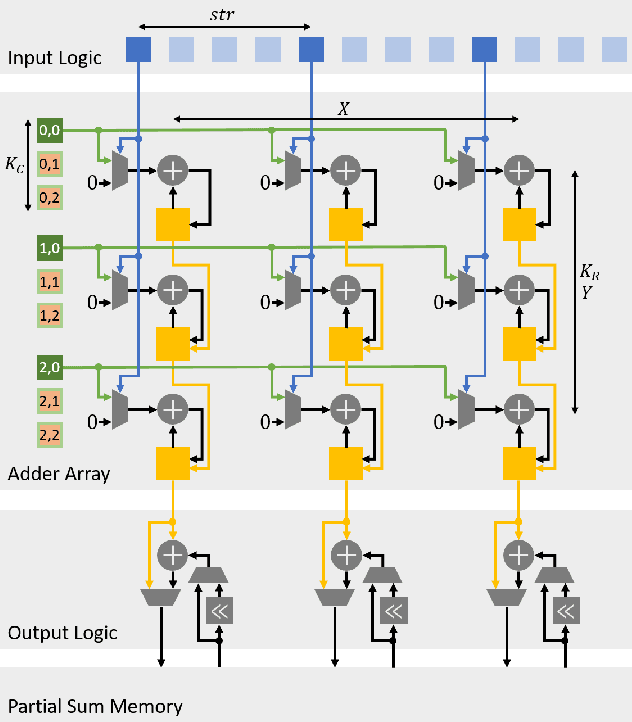
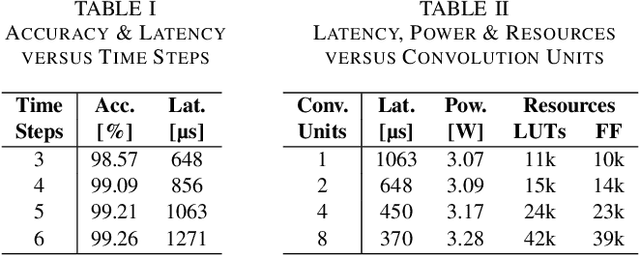
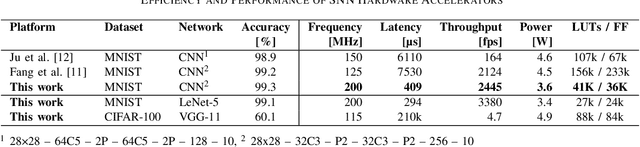
Spiking neural networks (SNNs) recently gained momentum due to their low-power multiplication-free computing and the closer resemblance of biological processes in the nervous system of humans. However, SNNs require very long spike trains (up to 1000) to reach an accuracy similar to their artificial neural network (ANN) counterparts for large models, which offsets efficiency and inhibits its application to low-power systems for real-world use cases. To alleviate this problem, emerging neural encoding schemes are proposed to shorten the spike train while maintaining the high accuracy. However, current accelerators for SNN cannot well support the emerging encoding schemes. In this work, we present a novel hardware architecture that can efficiently support SNN with emerging neural encoding. Our implementation features energy and area efficient processing units with increased parallelism and reduced memory accesses. We verified the accelerator on FPGA and achieve 25% and 90% improvement over previous work in power consumption and latency, respectively. At the same time, high area efficiency allows us to scale for large neural network models. To the best of our knowledge, this is the first work to deploy the large neural network model VGG on physical FPGA-based neuromorphic hardware.
E3NE: An End-to-End Framework for Accelerating Spiking Neural Networks with Emerging Neural Encoding on FPGAs
Nov 19, 2021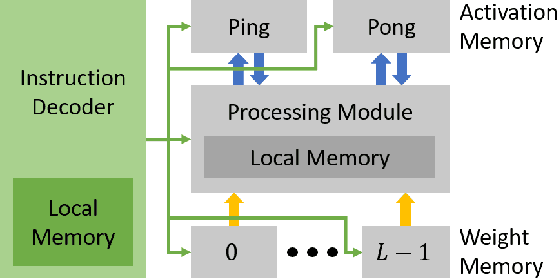

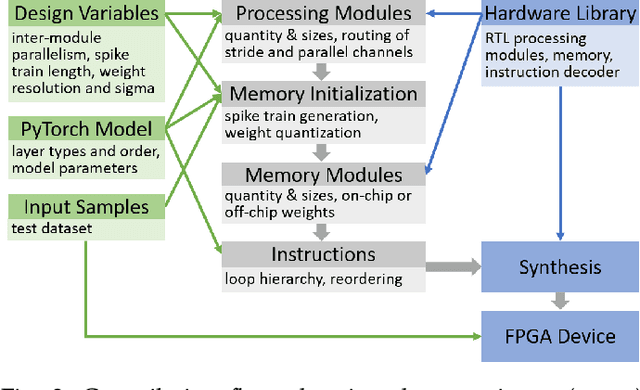
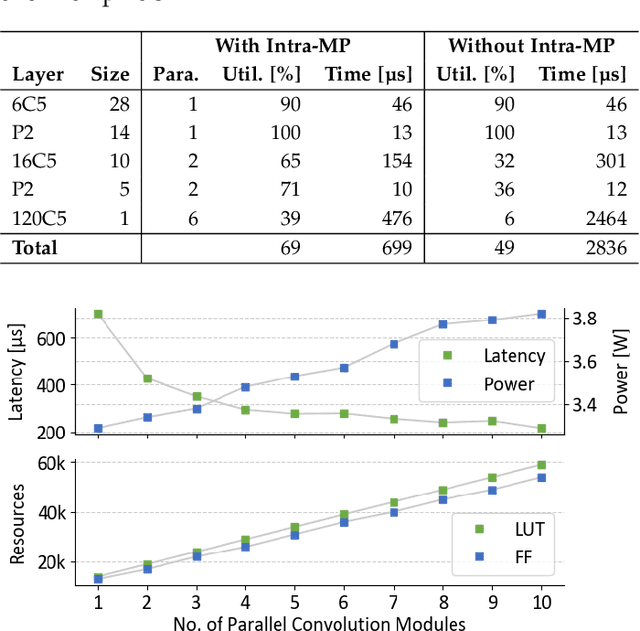
Compiler frameworks are crucial for the widespread use of FPGA-based deep learning accelerators. They allow researchers and developers, who are not familiar with hardware engineering, to harness the performance attained by domain-specific logic. There exists a variety of frameworks for conventional artificial neural networks. However, not much research effort has been put into the creation of frameworks optimized for spiking neural networks (SNNs). This new generation of neural networks becomes increasingly interesting for the deployment of AI on edge devices, which have tight power and resource constraints. Our end-to-end framework E3NE automates the generation of efficient SNN inference logic for FPGAs. Based on a PyTorch model and user parameters, it applies various optimizations and assesses trade-offs inherent to spike-based accelerators. Multiple levels of parallelism and the use of an emerging neural encoding scheme result in an efficiency superior to previous SNN hardware implementations. For a similar model, E3NE uses less than 50% of hardware resources and 20% less power, while reducing the latency by an order of magnitude. Furthermore, scalability and generality allowed the deployment of the large-scale SNN models AlexNet and VGG.