 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE3NE: An End-to-End Framework for Accelerating Spiking Neural Networks with Emerging Neural Encoding on FPGAs
Paper and Code
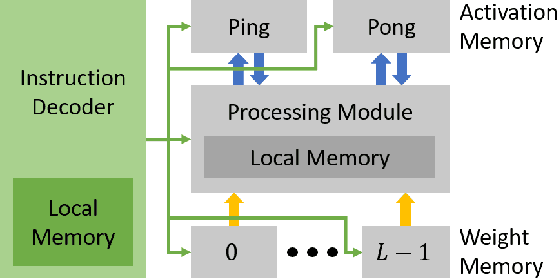

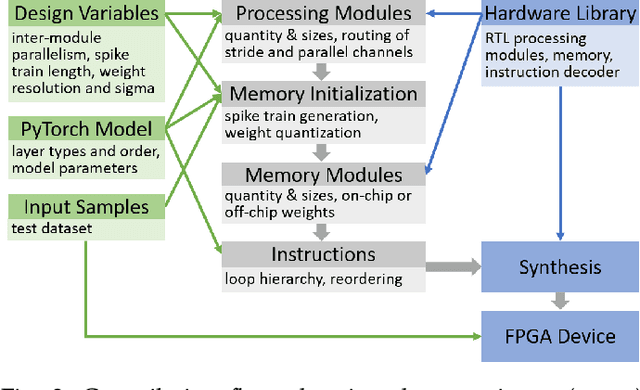
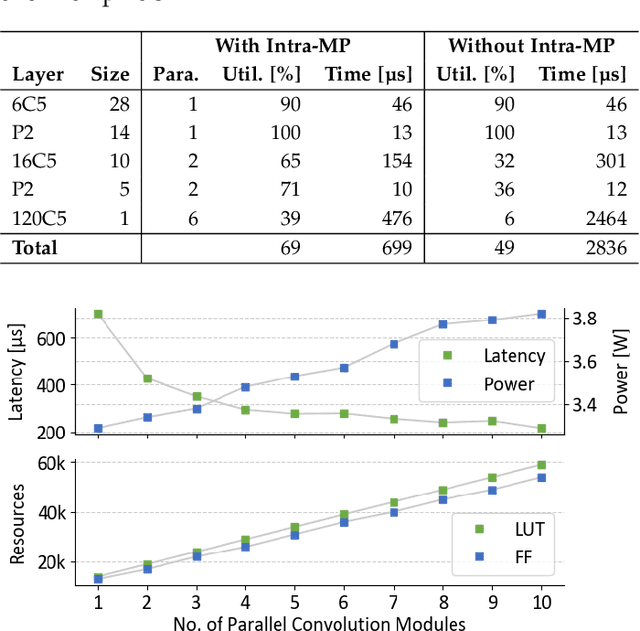
Compiler frameworks are crucial for the widespread use of FPGA-based deep learning accelerators. They allow researchers and developers, who are not familiar with hardware engineering, to harness the performance attained by domain-specific logic. There exists a variety of frameworks for conventional artificial neural networks. However, not much research effort has been put into the creation of frameworks optimized for spiking neural networks (SNNs). This new generation of neural networks becomes increasingly interesting for the deployment of AI on edge devices, which have tight power and resource constraints. Our end-to-end framework E3NE automates the generation of efficient SNN inference logic for FPGAs. Based on a PyTorch model and user parameters, it applies various optimizations and assesses trade-offs inherent to spike-based accelerators. Multiple levels of parallelism and the use of an emerging neural encoding scheme result in an efficiency superior to previous SNN hardware implementations. For a similar model, E3NE uses less than 50% of hardware resources and 20% less power, while reducing the latency by an order of magnitude. Furthermore, scalability and generality allowed the deployment of the large-scale SNN models AlexNet and VGG.