 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttitude-Aided Linear Calibration of Triaxial Accelerometers
Jun 04, 2026Triaxial MEMS accelerometers are widely used for inertial sensing, navigation, and sensor fusion, but existing calibration methods often rely on costly reference setups or nonlinear iterative optimization, limiting their efficiency and applicability to low-cost or self-calibrating systems. We present attitude-aided linear accelerometer calibration (ALAC), a method that operates on any platform providing orientation information, such as turntables, robotic arms, or inertial measurement units. ALAC constructs a combined error matrix (CEM) to represent sensor errors in a unified calibration model and enables linear least-squares estimation. The bias and gravity vector are jointly estimated, implicitly accounting for platform misalignment, and matrix decomposition of the CEM recovers scale, non-orthogonality, and alignment rotation parameters. Under static gravity, calibration is formulated as a constrained homogeneous least-squares (CHLS) problem and solved in closed form using standard linear algebra. Only five arbitrarily oriented measurements are required, and a recursive extension supports online or in-field calibration. Experiments on a stationary robot-mounted accelerometer and a quasi-static public IMU trajectory show that ALAC, in both offline and online modes, outperforms reference-based and online baselines in accuracy and robustness to sensor noise. On the same dataset, it matches iterative self-calibration under filtered conditions and surpasses all evaluated baselines on raw measurements. These results demonstrate a robust and practical calibration scheme for MEMS-based inertial platforms, especially low-cost IMUs and online calibration scenarios.
CoSPlay: Cooperative Self-Play at Test-Time with Self-Generated Code and Unit Test
May 25, 2026Recently, Reinforcement Learning with Verifiable Rewards (RLVR) and Test-Time Scaling (TTS) have advanced LLM code generation through executable verification. Yet Ground-Truth Unit Tests (GT UTs) remain a bottleneck: SOTA RLVR methods require them for costly training, while existing TTS methods lose competitiveness without them. This motivates GT-free TTS, where existing methods directly use self-generated UTs to refine and select code candidates. Yet such UTs are often noisy or spuriously coupled with wrong code, and UT quality in turn cannot be validated without reliable code. The key challenge is therefore to jointly improve both. To this end, we present CoSPlay, a GT-free, training-free framework that jointly improves codes and UTs through cooperative self-play. It first explores diverse solution ideas and identifies their potential failure modes to produce discriminative UT ideas. It then uses bidirectional pass-count signals from the Code-UT execution matrix to iteratively prune or fix weak codes and refresh or replace unreliable UTs, letting the two pools co-evolve. Finally, when multiple codes remain tied at the highest pass count, it picks the final code from the largest output-consensus cluster, since correct codes agree on the same inputs while wrong codes diverge. Experiments on four challenging benchmarks show that CoSPlay on Qwen2.5-7B-Instruct improves average BoN from 22.1% to 33.2% and UT accuracy from 14.6% to 78.3%, matching or surpassing the RLVR model CURE-7B. When applied to CURE-7B, it further improves BoN by 5.7%. CoSPlay also generalizes across diverse backbones and outperforms GT-free TTS baselines under comparable token budgets, with continued gains as the budget scales up. These results suggest a scalable inference strategy for competitive code generation without any GT data.
LLM-Based Data Generation and Clinical Skills Evaluation for Low-Resource French OSCEs
Apr 09, 2026Objective Structured Clinical Examinations (OSCEs) are the standard method for assessing medical students' clinical and communication skills through structured patient interviews. In France, however, the organization of training sessions is limited by human and logistical constraints, restricting students' access to repeated practice and structured feedback. Recent advances in Natural Language Processing (NLP) and Large Language Models (LLMs) now offer the opportunity to automatically evaluate such medical interviews, thereby alleviating the need for human examiners during training. Yet, real French OSCE annotated transcripts remain extremely scarce, limiting reproducible research and reliable benchmarking. To address these challenges, we investigate the use of LLMs for both generating and evaluating French OSCE dialogues in a low-resource context. We introduce a controlled pipeline that produces synthetic doctor-patient interview transcripts guided by scenario-specific evaluation criteria, combining ideal and perturbed performances to simulate varying student skill levels. The resulting dialogues are automatically silver-labeled through an LLM-assisted framework supporting adjustable evaluation strictness. Benchmarking multiple open-source and proprietary LLMs shows that mid-size models ($\le$32B parameters) achieve accuracies comparable to GPT-4o ($\sim$90\%) on synthetic data, highlighting the feasibility of locally deployable, privacy-preserving evaluation systems for medical education.
Is Quantum Optimization Ready? An Effort Towards Neural Network Compression using Adiabatic Quantum Computing
May 22, 2025



Quantum optimization is the most mature quantum computing technology to date, providing a promising approach towards efficiently solving complex combinatorial problems. Methods such as adiabatic quantum computing (AQC) have been employed in recent years on important optimization problems across various domains. In deep learning, deep neural networks (DNN) have reached immense sizes to support new predictive capabilities. Optimization of large-scale models is critical for sustainable deployment, but becomes increasingly challenging with ever-growing model sizes and complexity. While quantum optimization is suitable for solving complex problems, its application to DNN optimization is not straightforward, requiring thorough reformulation for compatibility with commercially available quantum devices. In this work, we explore the potential of adopting AQC for fine-grained pruning-quantization of convolutional neural networks. We rework established heuristics to formulate model compression as a quadratic unconstrained binary optimization (QUBO) problem, and assess the solution space offered by commercial quantum annealing devices. Through our exploratory efforts of reformulation, we demonstrate that AQC can achieve effective compression of practical DNN models. Experiments demonstrate that adiabatic quantum computing (AQC) not only outperforms classical algorithms like genetic algorithms and reinforcement learning in terms of time efficiency but also excels at identifying global optima.
Direct Preference-Based Evolutionary Multi-Objective Optimization with Dueling Bandit
Nov 23, 2023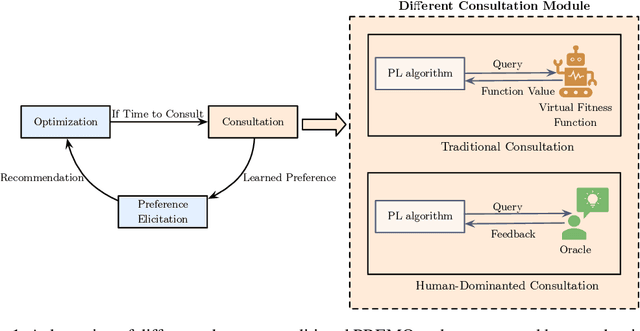


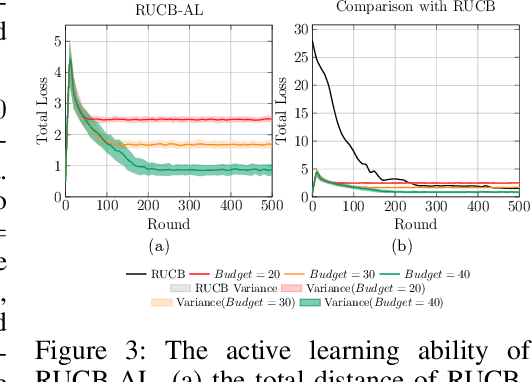
Optimization problems find widespread use in both single-objective and multi-objective scenarios. In practical applications, users aspire for solutions that converge to the region of interest (ROI) along the Pareto front (PF). While the conventional approach involves approximating a fitness function or an objective function to reflect user preferences, this paper explores an alternative avenue. Specifically, we aim to discover a method that sidesteps the need for calculating the fitness function, relying solely on human feedback. Our proposed approach entails conducting direct preference learning facilitated by an active dueling bandit algorithm. The experimental phase is structured into three sessions. Firstly, we assess the performance of our active dueling bandit algorithm. Secondly, we implement our proposed method within the context of Multi-objective Evolutionary Algorithms (MOEAs). Finally, we deploy our method in a practical problem, specifically in protein structure prediction (PSP). This research presents a novel interactive preference-based MOEA framework that not only addresses the limitations of traditional techniques but also unveils new possibilities for optimization problems.
DeepFire2: A Convolutional Spiking Neural Network Accelerator on FPGAs
May 09, 2023



Brain-inspired spiking neural networks (SNNs) replace the multiply-accumulate operations of traditional neural networks by integrate-and-fire neurons, with the goal of achieving greater energy efficiency. Specialized hardware implementations of those neurons clearly have advantages over general-purpose devices in terms of power and performance, but exhibit poor scalability when it comes to accelerating large neural networks. DeepFire2 introduces a hardware architecture which can map large network layers efficiently across multiple super logic regions in a multi-die FPGA. That gives more control over resource allocation and parallelism, benefiting both throughput and energy consumption. Avoiding the use of lookup tables to implement the AND operations of an SNN, prevents the layer size to be limited by logic resources. A deep pipeline does not only lead to an increased clock speed of up to 600 MHz. We double the throughput and power efficiency compared to our previous version of DeepFire, which equates to an almost 10-fold improvement over other previous implementations. Importantly, we are able to deploy a large ImageNet model, while maintaining a throughput of over 1500 frames per second.
Robust Motion Averaging for Multi-view Registration of Point Sets Based Maximum Correntropy Criterion
Aug 24, 2022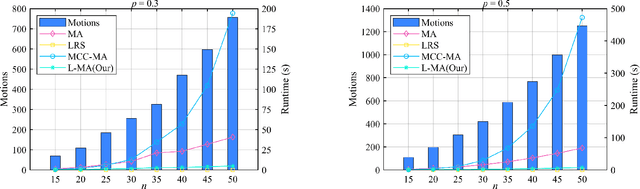
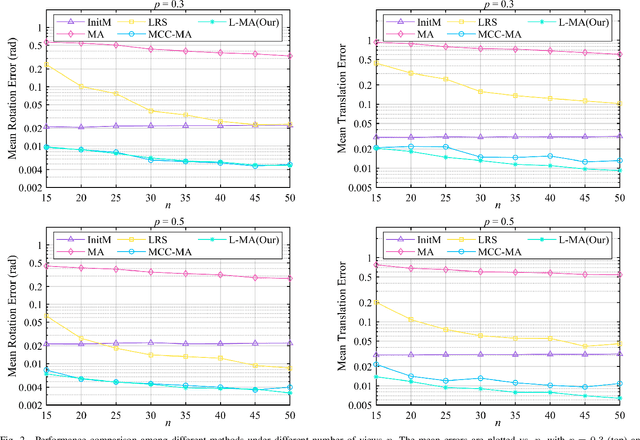
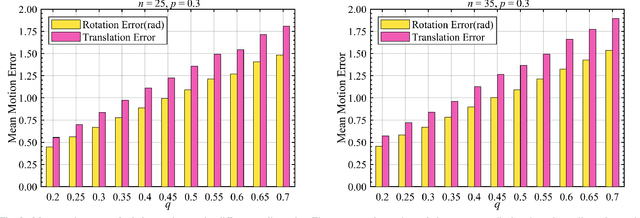
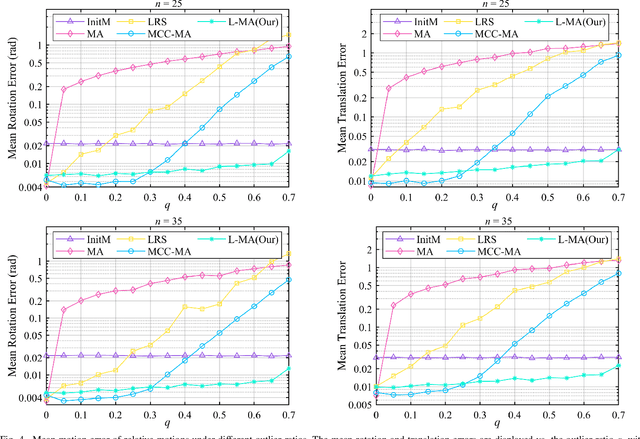
As an efficient algorithm to solve the multi-view registration problem,the motion averaging (MA) algorithm has been extensively studied and many MA-based algorithms have been introduced. They aim at recovering global motions from relative motions and exploiting information redundancy to average accumulative errors. However, one property of these methods is that they use Guass-Newton method to solve a least squares problem for the increment of global motions, which may lead to low efficiency and poor robustness to outliers. In this paper, we propose a novel motion averaging framework for the multi-view registration with Laplacian kernel-based maximum correntropy criterion (LMCC). Utilizing the Lie algebra motion framework and the correntropy measure, we propose a new cost function that takes all constraints supplied by relative motions into account. Obtaining the increment used to correct the global motions, can further be formulated as an optimization problem aimed at maximizing the cost function. By virtue of the quadratic technique, the optimization problem can be solved by dividing into two subproblems, i.e., computing the weight for each relative motion according to the current residuals and solving a second-order cone program problem (SOCP) for the increment in the next iteration. We also provide a novel strategy for determining the kernel width which ensures that our method can efficiently exploit information redundancy supplied by relative motions in the presence of many outliers. Finally, we compare the proposed method with other MA-based multi-view registration methods to verify its performance. Experimental tests on synthetic and real data demonstrate that our method achieves superior performance in terms of efficiency, accuracy and robustness.
RCT: Resource Constrained Training for Edge AI
Mar 26, 2021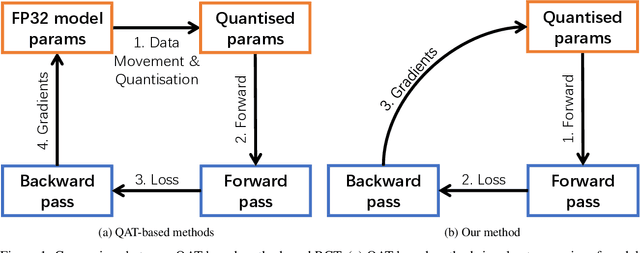
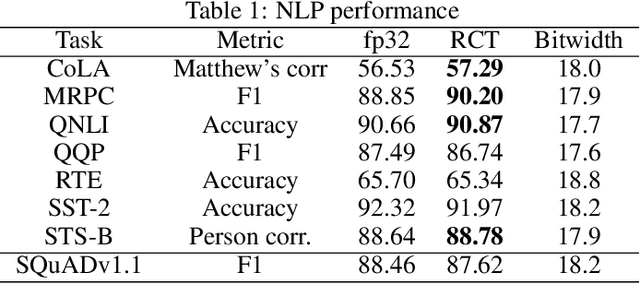
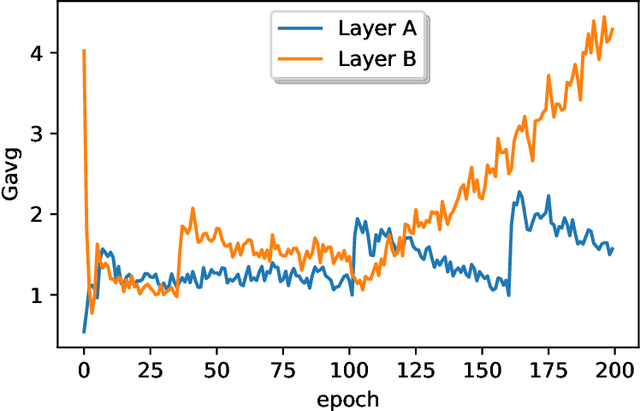
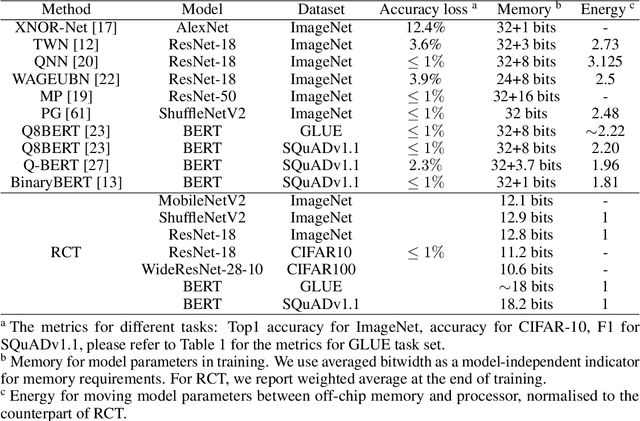
Neural networks training on edge terminals is essential for edge AI computing, which needs to be adaptive to evolving environment. Quantised models can efficiently run on edge devices, but existing training methods for these compact models are designed to run on powerful servers with abundant memory and energy budget. For example, quantisation-aware training (QAT) method involves two copies of model parameters, which is usually beyond the capacity of on-chip memory in edge devices. Data movement between off-chip and on-chip memory is energy demanding as well. The resource requirements are trivial for powerful servers, but critical for edge devices. To mitigate these issues, We propose Resource Constrained Training (RCT). RCT only keeps a quantised model throughout the training, so that the memory requirements for model parameters in training is reduced. It adjusts per-layer bitwidth dynamically in order to save energy when a model can learn effectively with lower precision. We carry out experiments with representative models and tasks in image application and natural language processing. Experiments show that RCT saves more than 86\% energy for General Matrix Multiply (GEMM) and saves more than 46\% memory for model parameters, with limited accuracy loss. Comparing with QAT-based method, RCT saves about half of energy on moving model parameters.
QROSS: QUBO Relaxation Parameter Optimisation via Learning Solver Surrogates
Mar 19, 2021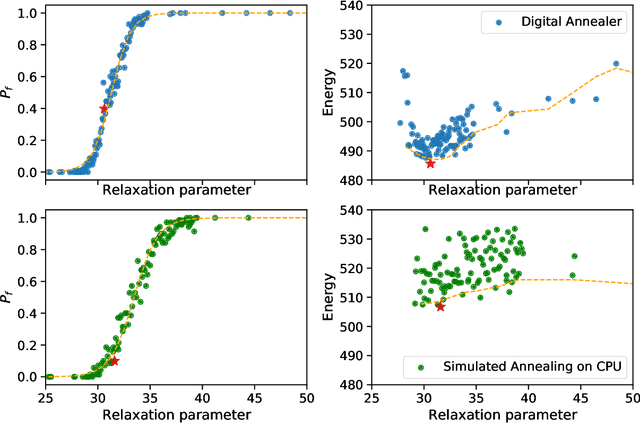
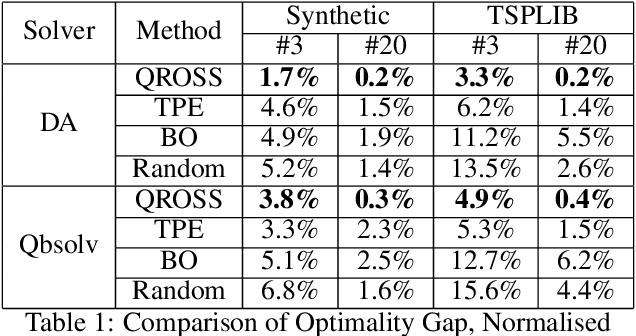
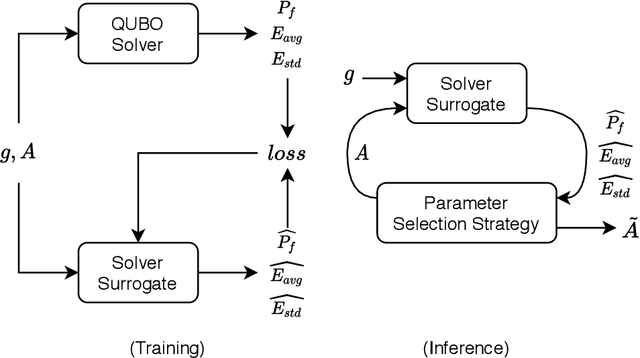
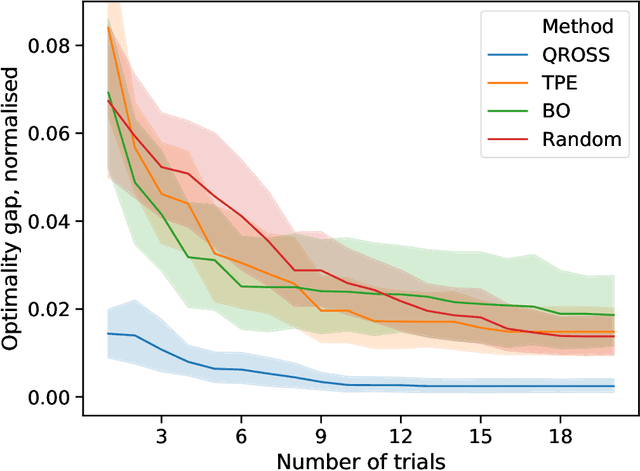
An increasingly popular method for solving a constrained combinatorial optimisation problem is to first convert it into a quadratic unconstrained binary optimisation (QUBO) problem, and solve it using a standard QUBO solver. However, this relaxation introduces hyper-parameters that balance the objective and penalty terms for the constraints, and their chosen values significantly impact performance. Hence, tuning these parameters is an important problem. Existing generic hyper-parameter tuning methods require multiple expensive calls to a QUBO solver, making them impractical for performance critical applications when repeated solutions of similar combinatorial optimisation problems are required. In this paper, we propose the QROSS method, in which we build surrogate models of QUBO solvers via learning from solver data on a collection of instances of a problem. In this way, we are able capture the common structure of the instances and their interactions with the solver, and produce good choices of penalty parameters with fewer number of calls to the QUBO solver. We take the Traveling Salesman Problem (TSP) as a case study, where we demonstrate that our method can find better solutions with fewer calls to QUBO solver compared with conventional hyper-parameter tuning techniques. Moreover, with simple adaptation methods, QROSS is shown to generalise well to out-of-distribution datasets and different types of QUBO solvers.
Adaptive Precision Training for Resource Constrained Devices
Dec 23, 2020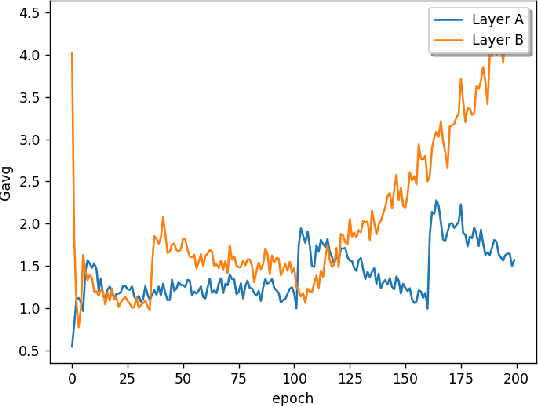
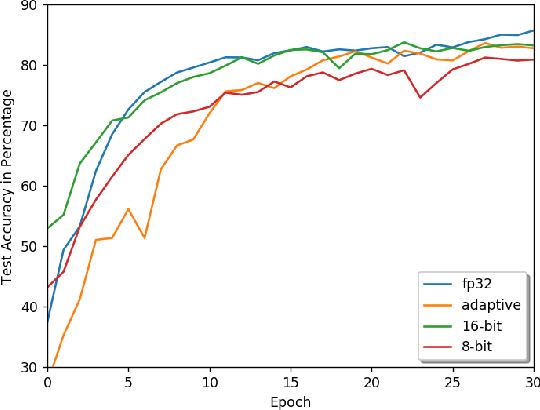
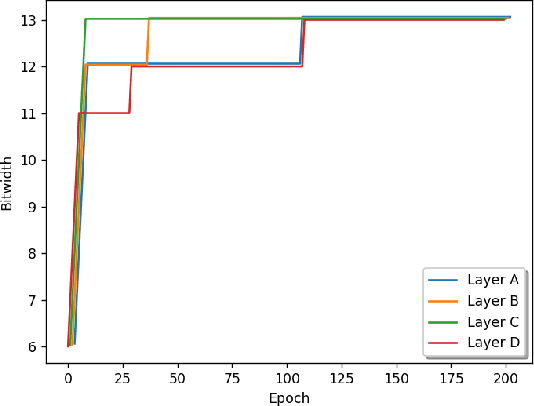
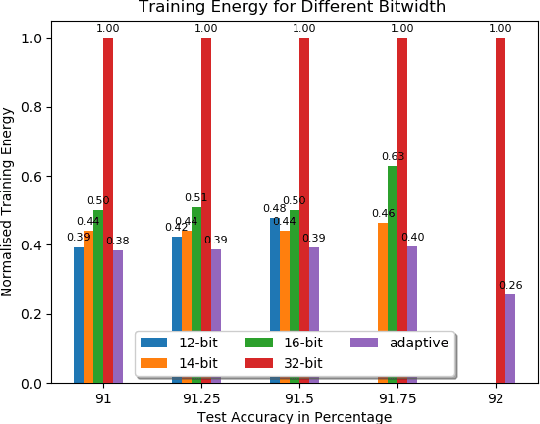
Learn in-situ is a growing trend for Edge AI. Training deep neural network (DNN) on edge devices is challenging because both energy and memory are constrained. Low precision training helps to reduce the energy cost of a single training iteration, but that does not necessarily translate to energy savings for the whole training process, because low precision could slows down the convergence rate. One evidence is that most works for low precision training keep an fp32 copy of the model during training, which in turn imposes memory requirements on edge devices. In this work we propose Adaptive Precision Training. It is able to save both total training energy cost and memory usage at the same time. We use model of the same precision for both forward and backward pass in order to reduce memory usage for training. Through evaluating the progress of training, APT allocates layer-wise precision dynamically so that the model learns quicker for longer time. APT provides an application specific hyper-parameter for users to play trade-off between training energy cost, memory usage and accuracy. Experiment shows that APT achieves more than 50% saving on training energy and memory usage with limited accuracy loss. 20% more savings of training energy and memory usage can be achieved in return for a 1% sacrifice in accuracy loss.