 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCT: Resource Constrained Training for Edge AI
Paper and Code
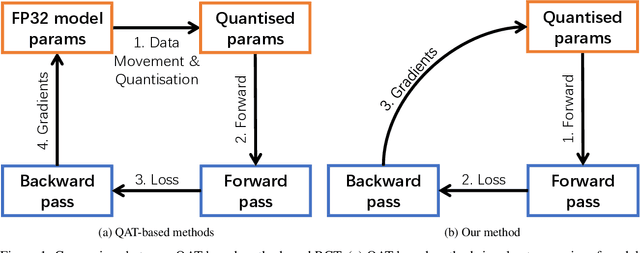
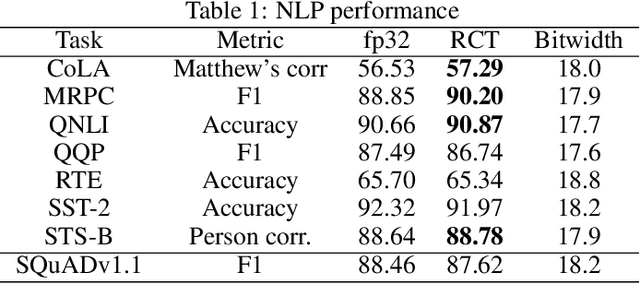
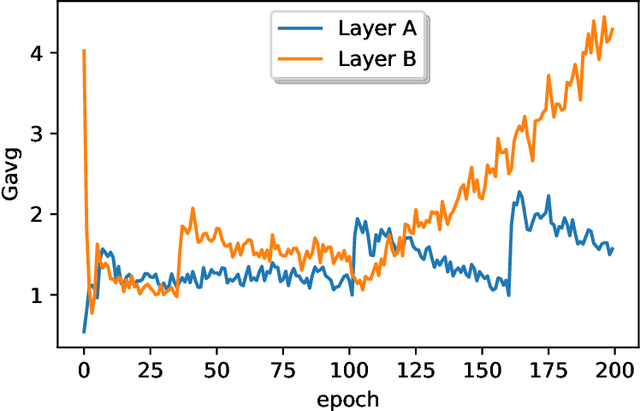
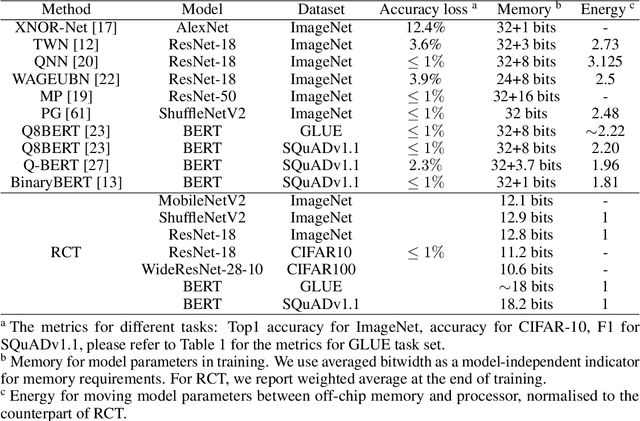
Neural networks training on edge terminals is essential for edge AI computing, which needs to be adaptive to evolving environment. Quantised models can efficiently run on edge devices, but existing training methods for these compact models are designed to run on powerful servers with abundant memory and energy budget. For example, quantisation-aware training (QAT) method involves two copies of model parameters, which is usually beyond the capacity of on-chip memory in edge devices. Data movement between off-chip and on-chip memory is energy demanding as well. The resource requirements are trivial for powerful servers, but critical for edge devices. To mitigate these issues, We propose Resource Constrained Training (RCT). RCT only keeps a quantised model throughout the training, so that the memory requirements for model parameters in training is reduced. It adjusts per-layer bitwidth dynamically in order to save energy when a model can learn effectively with lower precision. We carry out experiments with representative models and tasks in image application and natural language processing. Experiments show that RCT saves more than 86\% energy for General Matrix Multiply (GEMM) and saves more than 46\% memory for model parameters, with limited accuracy loss. Comparing with QAT-based method, RCT saves about half of energy on moving model parameters.