 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Precision Training for Resource Constrained Devices
Paper and Code
Dec 23, 2020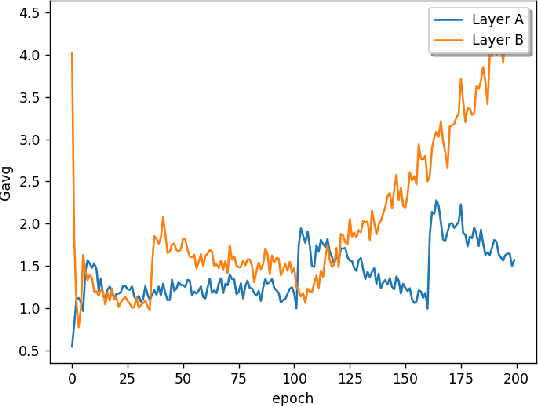
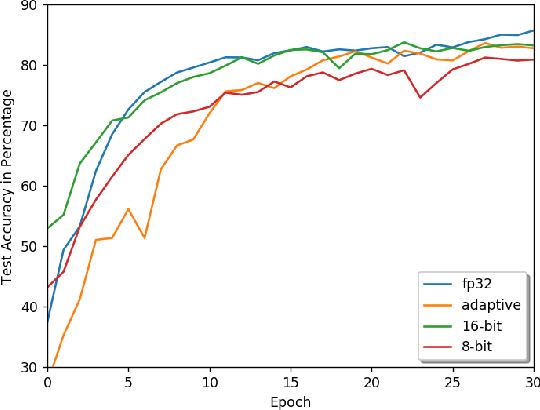
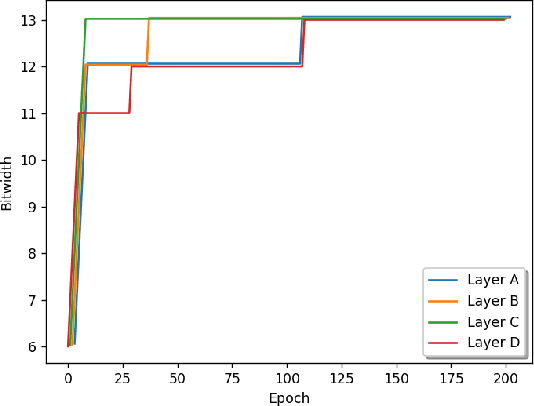
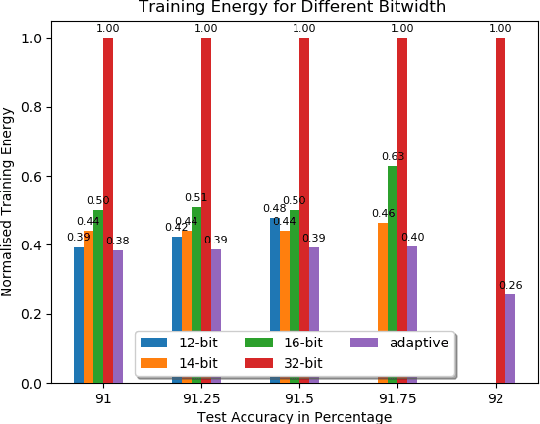
Learn in-situ is a growing trend for Edge AI. Training deep neural network (DNN) on edge devices is challenging because both energy and memory are constrained. Low precision training helps to reduce the energy cost of a single training iteration, but that does not necessarily translate to energy savings for the whole training process, because low precision could slows down the convergence rate. One evidence is that most works for low precision training keep an fp32 copy of the model during training, which in turn imposes memory requirements on edge devices. In this work we propose Adaptive Precision Training. It is able to save both total training energy cost and memory usage at the same time. We use model of the same precision for both forward and backward pass in order to reduce memory usage for training. Through evaluating the progress of training, APT allocates layer-wise precision dynamically so that the model learns quicker for longer time. APT provides an application specific hyper-parameter for users to play trade-off between training energy cost, memory usage and accuracy. Experiment shows that APT achieves more than 50% saving on training energy and memory usage with limited accuracy loss. 20% more savings of training energy and memory usage can be achieved in return for a 1% sacrifice in accuracy loss.