 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriGen: NPU Architecture for End-to-End Acceleration of Large Language Models based on SW-HW Co-Design
Feb 13, 2026Recent studies have extensively explored NPU architectures for accelerating AI inference in on-device environments, which are inherently resource-constrained. Meanwhile, transformer-based large language models (LLMs) have become dominant, with rapidly increasing model sizes but low degree of parameter reuse compared to conventional CNNs, making end-to-end execution on resource-limited devices extremely challenging. To address these challenges, we propose TriGen, a novel NPU architecture tailored for resource-constrained environments through software-hardware co-design. Firstly, TriGen adopts low-precision computation using microscaling (MX) to enable additional optimization opportunities while preserving accuracy, and resolves the issues that arise by employing such precision. Secondly, to jointly optimize both nonlinear and linear operations, TriGen eliminates the need for specialized hardware for essential nonlinear operations by using fast and accurate LUT, thereby maximizing performance gains and reducing hardware-cost in on-device environments, and finally, by taking practical hardware constraints into account, further employs scheduling techniques to maximize computational utilization even under limited on-chip memory capacity. We evaluate the performance of TriGen on various LLMs and show that TriGen achieves an average 2.73x performance speedup and 52% less memory transfer over the baseline NPU design with negligible accuracy loss.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Back-Translated Task Adaptive Pretraining: Improving Accuracy and Robustness on Text Classification
Jul 22, 2021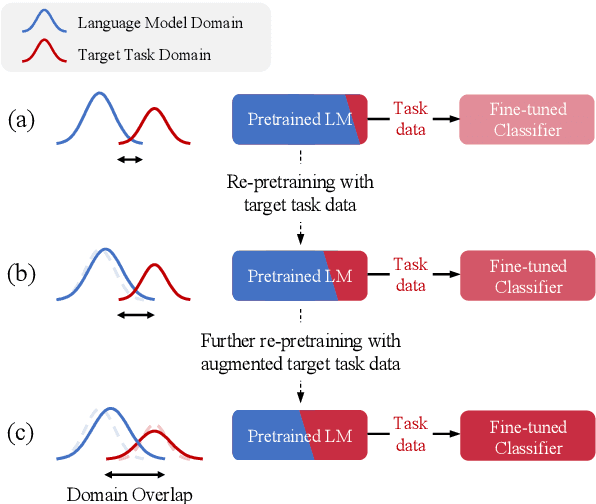
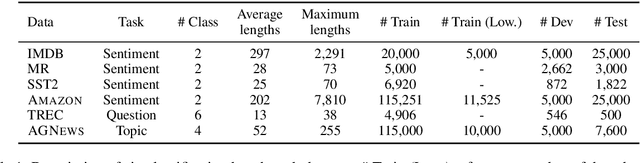
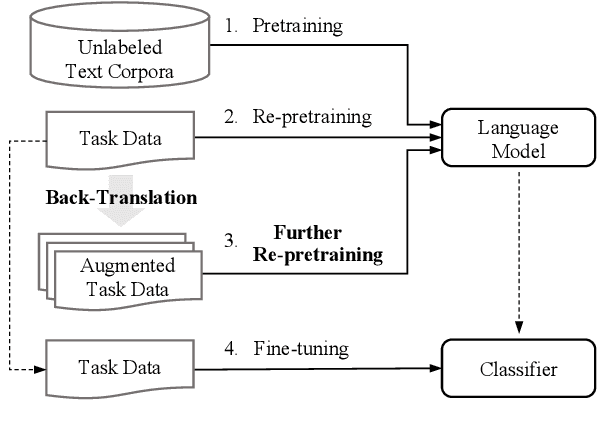
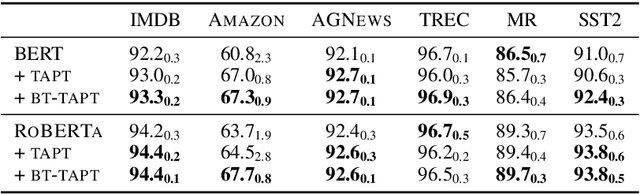
Language models (LMs) pretrained on a large text corpus and fine-tuned on a downstream text corpus and fine-tuned on a downstream task becomes a de facto training strategy for several natural language processing (NLP) tasks. Recently, an adaptive pretraining method retraining the pretrained language model with task-relevant data has shown significant performance improvements. However, current adaptive pretraining methods suffer from underfitting on the task distribution owing to a relatively small amount of data to re-pretrain the LM. To completely use the concept of adaptive pretraining, we propose a back-translated task-adaptive pretraining (BT-TAPT) method that increases the amount of task-specific data for LM re-pretraining by augmenting the task data using back-translation to generalize the LM to the target task domain. The experimental results show that the proposed BT-TAPT yields improved classification accuracy on both low- and high-resource data and better robustness to noise than the conventional adaptive pretraining method.
Validating uncertainty in medical image translation
Feb 11, 2020
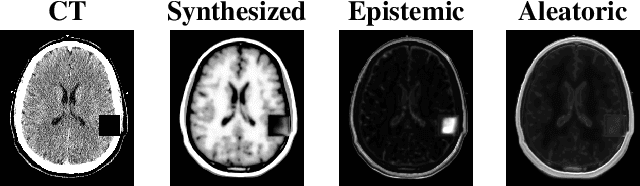
Medical images are increasingly used as input to deep neural networks to produce quantitative values that aid researchers and clinicians. However, standard deep neural networks do not provide a reliable measure of uncertainty in those quantitative values. Recent work has shown that using dropout during training and testing can provide estimates of uncertainty. In this work, we investigate using dropout to estimate epistemic and aleatoric uncertainty in a CT-to-MR image translation task. We show that both types of uncertainty are captured, as defined, providing confidence in the output uncertainty estimates.
Finding novelty with uncertainty
Feb 11, 2020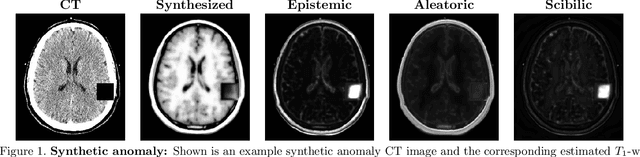
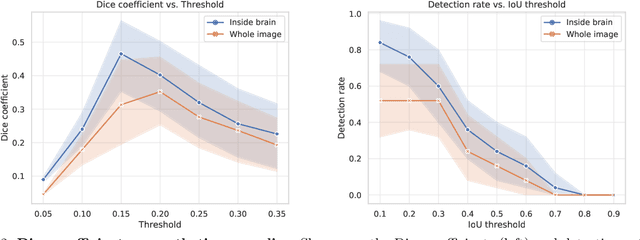
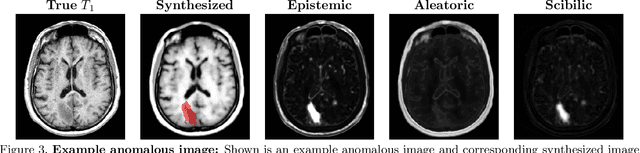
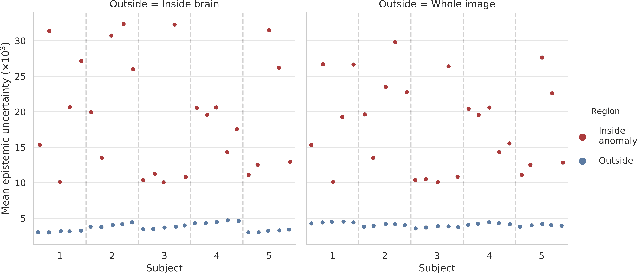
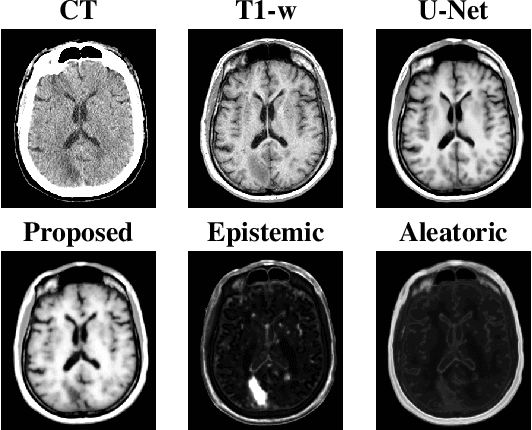
Medical images are often used to detect and characterize pathology and disease; however, automatically identifying and segmenting pathology in medical images is challenging because the appearance of pathology across diseases varies widely. To address this challenge, we propose a Bayesian deep learning method that learns to translate healthy computed tomography images to magnetic resonance images and simultaneously calculates voxel-wise uncertainty. Since high uncertainty occurs in pathological regions of the image, this uncertainty can be used for unsupervised anomaly segmentation. We show encouraging experimental results on an unsupervised anomaly segmentation task by combining two types of uncertainty into a novel quantity we call scibilic uncertainty.
Unpaired Brain MR-to-CT Synthesis using a Structure-Constrained CycleGAN
Sep 12, 2018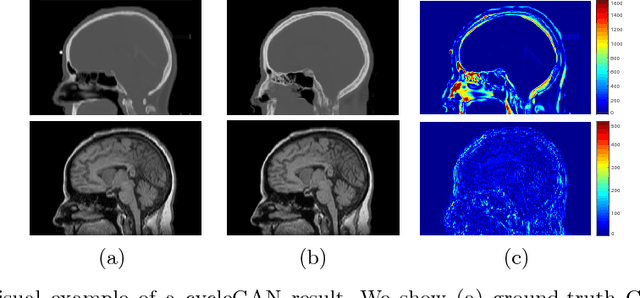
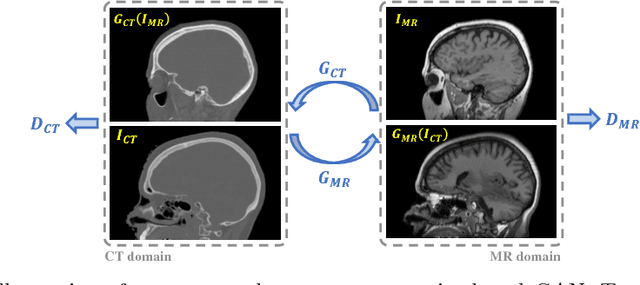
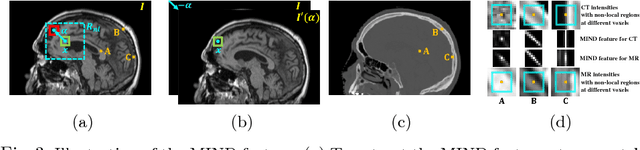
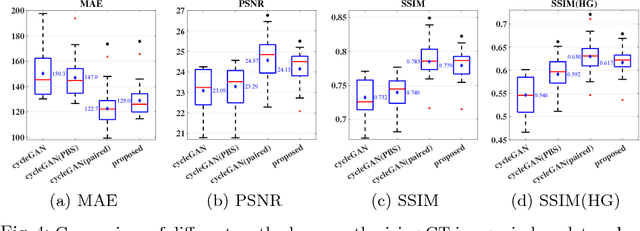
The cycleGAN is becoming an influential method in medical image synthesis. However, due to a lack of direct constraints between input and synthetic images, the cycleGAN cannot guarantee structural consistency between these two images, and such consistency is of extreme importance in medical imaging. To overcome this, we propose a structure-constrained cycleGAN for brain MR-to-CT synthesis using unpaired data that defines an extra structure-consistency loss based on the modality independent neighborhood descriptor to constrain structural consistency. Additionally, we use a position-based selection strategy for selecting training images instead of a completely random selection scheme. Experimental results on synthesizing CT images from brain MR images demonstrate that our method is better than the conventional cycleGAN and approximates the cycleGAN trained with paired data.