 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack-Translated Task Adaptive Pretraining: Improving Accuracy and Robustness on Text Classification
Paper and Code
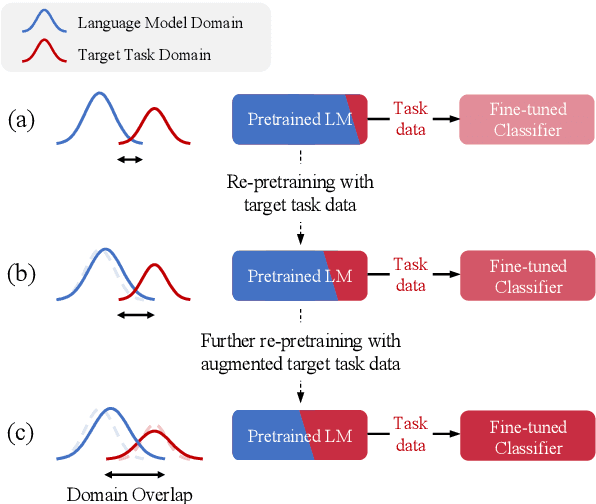
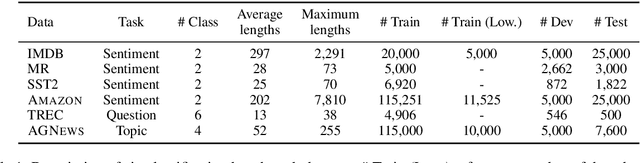
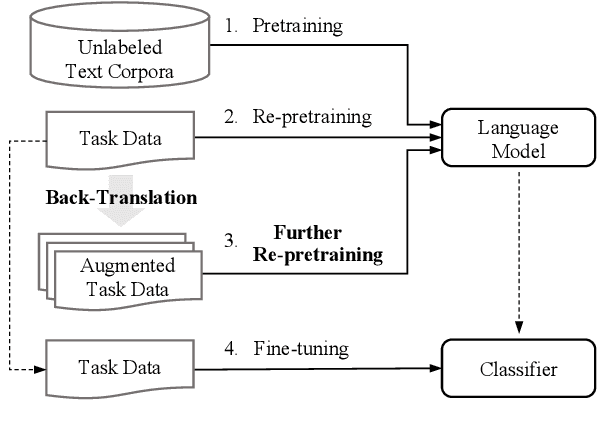
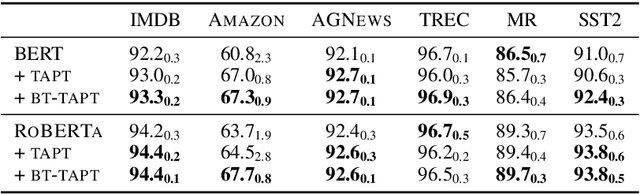
Language models (LMs) pretrained on a large text corpus and fine-tuned on a downstream text corpus and fine-tuned on a downstream task becomes a de facto training strategy for several natural language processing (NLP) tasks. Recently, an adaptive pretraining method retraining the pretrained language model with task-relevant data has shown significant performance improvements. However, current adaptive pretraining methods suffer from underfitting on the task distribution owing to a relatively small amount of data to re-pretrain the LM. To completely use the concept of adaptive pretraining, we propose a back-translated task-adaptive pretraining (BT-TAPT) method that increases the amount of task-specific data for LM re-pretraining by augmenting the task data using back-translation to generalize the LM to the target task domain. The experimental results show that the proposed BT-TAPT yields improved classification accuracy on both low- and high-resource data and better robustness to noise than the conventional adaptive pretraining method.