 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVolumetric Attention for 3D Medical Image Segmentation and Detection
Apr 04, 2020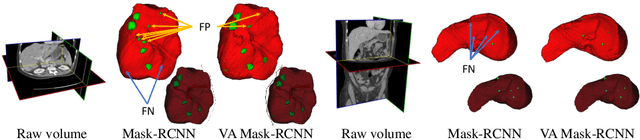



A volumetric attention(VA) module for 3D medical image segmentation and detection is proposed. VA attention is inspired by recent advances in video processing, enables 2.5D networks to leverage context information along the z direction, and allows the use of pretrained 2D detection models when training data is limited, as is often the case for medical applications. Its integration in the Mask R-CNN is shown to enable state-of-the-art performance on the Liver Tumor Segmentation (LiTS) Challenge, outperforming the previous challenge winner by 3.9 points and achieving top performance on the LiTS leader board at the time of paper submission. Detection experiments on the DeepLesion dataset also show that the addition of VA to existing object detectors enables a 69.1 sensitivity at 0.5 false positive per image, outperforming the best published results by 6.6 points.
* Accepted by MICCAI 2019
Validating uncertainty in medical image translation
Feb 11, 2020
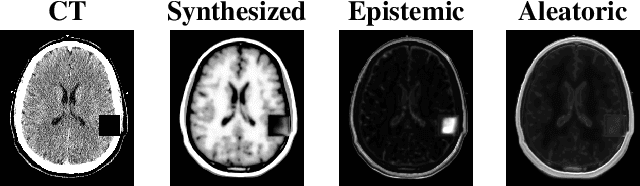
Medical images are increasingly used as input to deep neural networks to produce quantitative values that aid researchers and clinicians. However, standard deep neural networks do not provide a reliable measure of uncertainty in those quantitative values. Recent work has shown that using dropout during training and testing can provide estimates of uncertainty. In this work, we investigate using dropout to estimate epistemic and aleatoric uncertainty in a CT-to-MR image translation task. We show that both types of uncertainty are captured, as defined, providing confidence in the output uncertainty estimates.
Finding novelty with uncertainty
Feb 11, 2020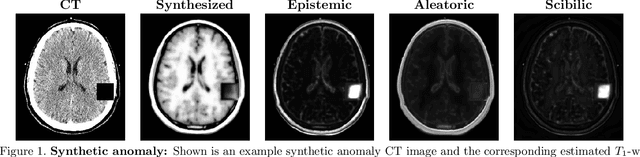
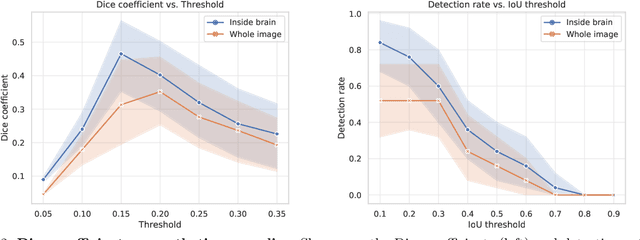
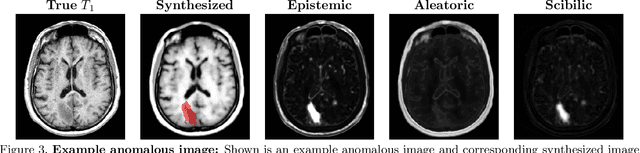
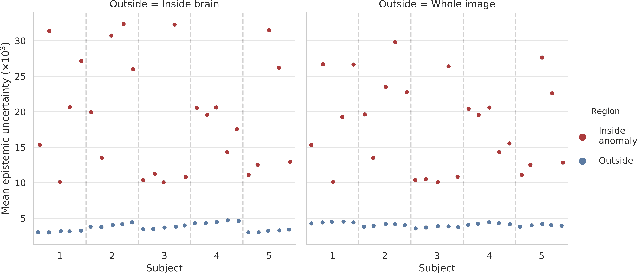
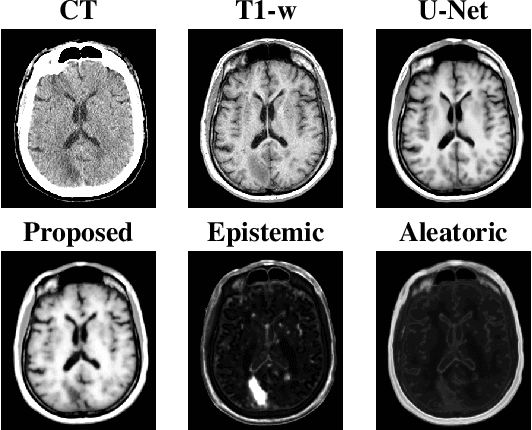
Medical images are often used to detect and characterize pathology and disease; however, automatically identifying and segmenting pathology in medical images is challenging because the appearance of pathology across diseases varies widely. To address this challenge, we propose a Bayesian deep learning method that learns to translate healthy computed tomography images to magnetic resonance images and simultaneously calculates voxel-wise uncertainty. Since high uncertainty occurs in pathological regions of the image, this uncertainty can be used for unsupervised anomaly segmentation. We show encouraging experimental results on an unsupervised anomaly segmentation task by combining two types of uncertainty into a novel quantity we call scibilic uncertainty.
Validation and Optimization of Multi-Organ Segmentation on Clinical Imaging Archives
Feb 10, 2020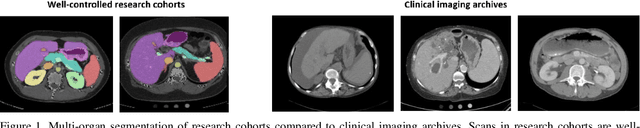
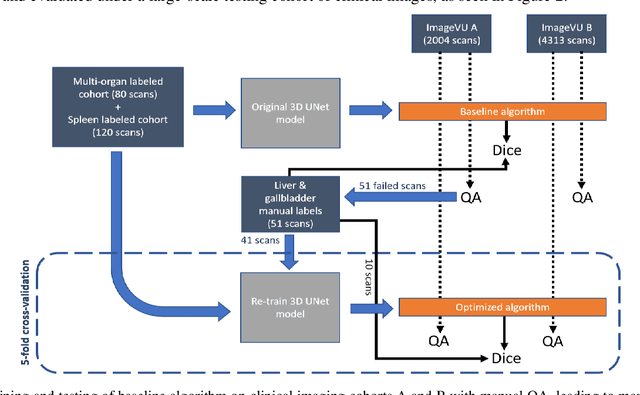
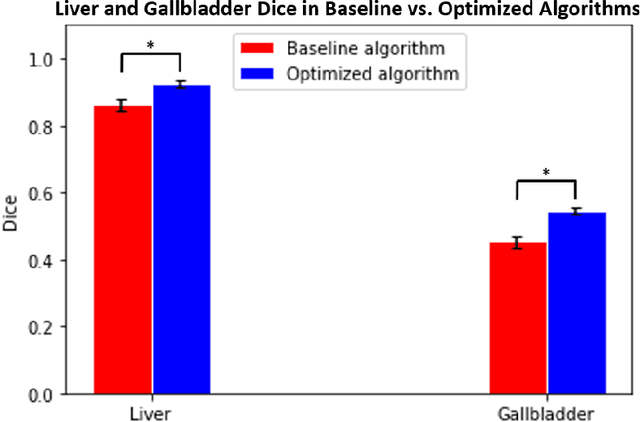
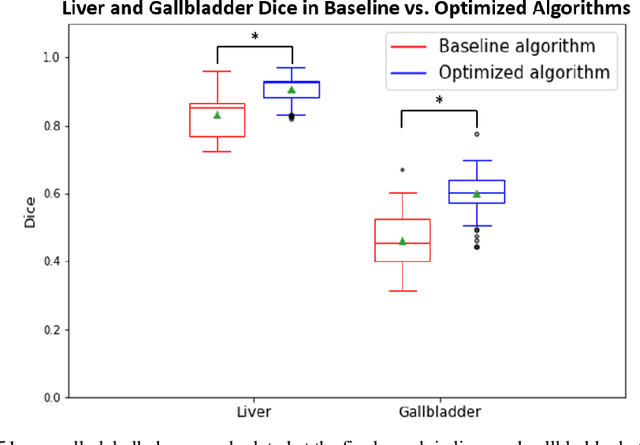
Segmentation of abdominal computed tomography(CT) provides spatial context, morphological properties, and a framework for tissue-specific radiomics to guide quantitative Radiological assessment. A 2015 MICCAI challenge spurred substantial innovation in multi-organ abdominal CT segmentation with both traditional and deep learning methods. Recent innovations in deep methods have driven performance toward levels for which clinical translation is appealing. However, continued cross-validation on open datasets presents the risk of indirect knowledge contamination and could result in circular reasoning. Moreover, 'real world' segmentations can be challenging due to the wide variability of abdomen physiology within patients. Herein, we perform two data retrievals to capture clinically acquired deidentified abdominal CT cohorts with respect to a recently published variation on 3D U-Net (baseline algorithm). First, we retrieved 2004 deidentified studies on 476 patients with diagnosis codes involving spleen abnormalities (cohort A). Second, we retrieved 4313 deidentified studies on 1754 patients without diagnosis codes involving spleen abnormalities (cohort B). We perform prospective evaluation of the existing algorithm on both cohorts, yielding 13% and 8% failure rate, respectively. Then, we identified 51 subjects in cohort A with segmentation failures and manually corrected the liver and gallbladder labels. We re-trained the model adding the manual labels, resulting in performance improvement of 9% and 6% failure rate for the A and B cohorts, respectively. In summary, the performance of the baseline on the prospective cohorts was similar to that on previously published datasets. Moreover, adding data from the first cohort substantively improved performance when evaluated on the second withheld validation cohort.
Outlier Guided Optimization of Abdominal Segmentation
Feb 10, 2020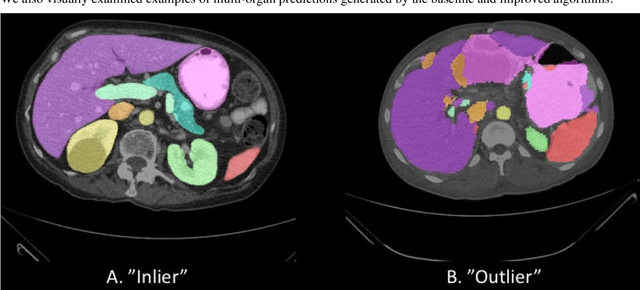
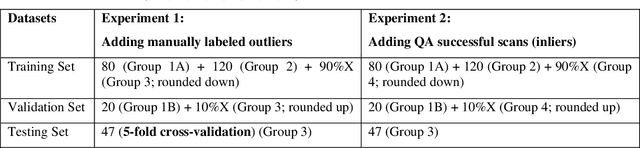
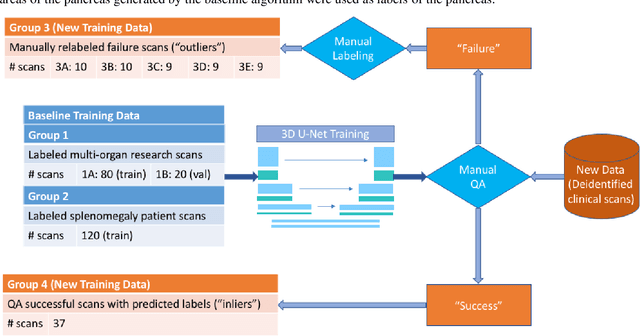
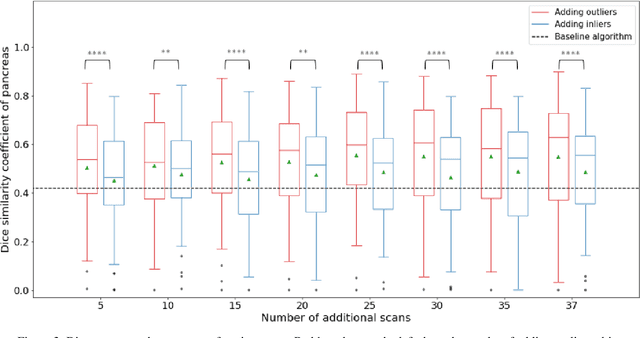
Abdominal multi-organ segmentation of computed tomography (CT) images has been the subject of extensive research interest. It presents a substantial challenge in medical image processing, as the shape and distribution of abdominal organs can vary greatly among the population and within an individual over time. While continuous integration of novel datasets into the training set provides potential for better segmentation performance, collection of data at scale is not only costly, but also impractical in some contexts. Moreover, it remains unclear what marginal value additional data have to offer. Herein, we propose a single-pass active learning method through human quality assurance (QA). We built on a pre-trained 3D U-Net model for abdominal multi-organ segmentation and augmented the dataset either with outlier data (e.g., exemplars for which the baseline algorithm failed) or inliers (e.g., exemplars for which the baseline algorithm worked). The new models were trained using the augmented datasets with 5-fold cross-validation (for outlier data) and withheld outlier samples (for inlier data). Manual labeling of outliers increased Dice scores with outliers by 0.130, compared to an increase of 0.067 with inliers (p<0.001, two-tailed paired t-test). By adding 5 to 37 inliers or outliers to training, we find that the marginal value of adding outliers is higher than that of adding inliers. In summary, improvement on single-organ performance was obtained without diminishing multi-organ performance or significantly increasing training time. Hence, identification and correction of baseline failure cases present an effective and efficient method of selecting training data to improve algorithm performance.
Stochastic tissue window normalization of deep learning on computed tomography
Dec 01, 2019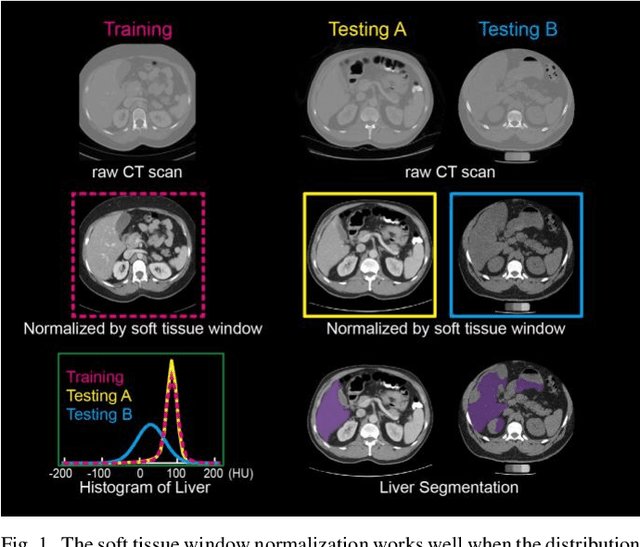
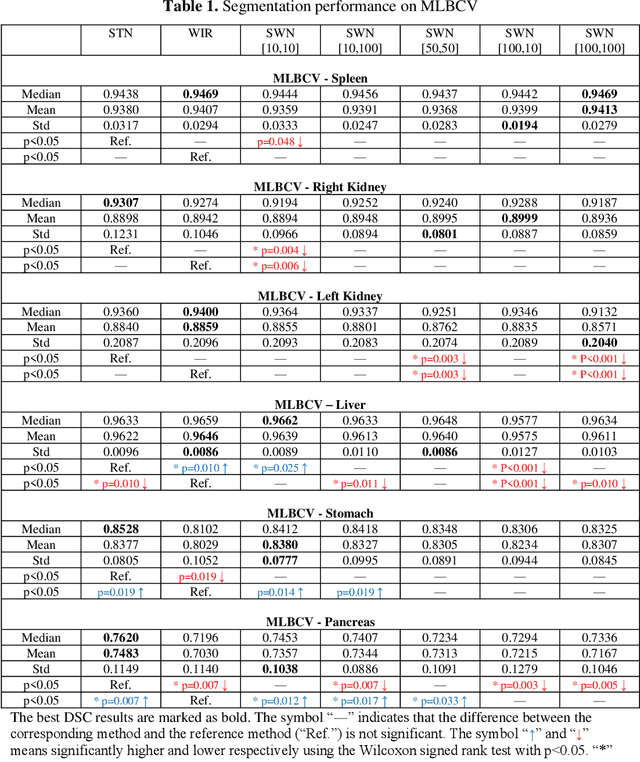
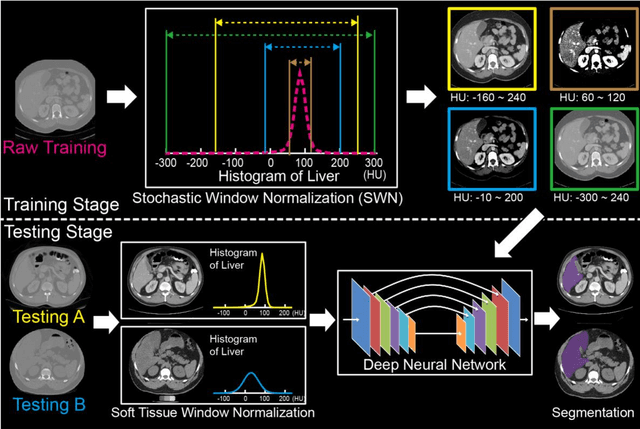
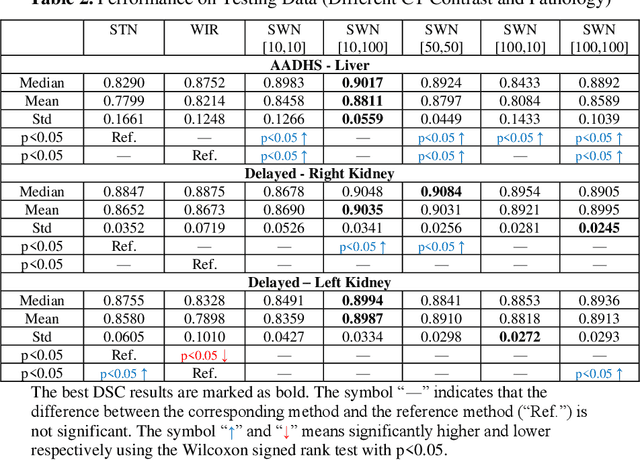
Tissue window filtering has been widely used in deep learning for computed tomography (CT) image analyses to improve training performance (e.g., soft tissue windows for abdominal CT). However, the effectiveness of tissue window normalization is questionable since the generalizability of the trained model might be further harmed, especially when such models are applied to new cohorts with different CT reconstruction kernels, contrast mechanisms, dynamic variations in the acquisition, and physiological changes. We evaluate the effectiveness of both with and without using soft tissue window normalization on multisite CT cohorts. Moreover, we propose a stochastic tissue window normalization (SWN) method to improve the generalizability of tissue window normalization. Different from the random sampling, the SWN method centers the randomization around the soft tissue window to maintain the specificity for abdominal organs. To evaluate the performance of different strategies, 80 training and 453 validation and testing scans from six datasets are employed to perform multi-organ segmentation using standard 2D U-Net. The six datasets cover the scenarios, where the training and testing scans are from (1) same scanner and same population, (2) same CT contrast but different pathology, and (3) different CT contrast and pathology. The traditional soft tissue window and nonwindowed approaches achieved better performance on (1). The proposed SWN achieved general superior performance on (2) and (3) with statistical analyses, which offers better generalizability for a trained model.
Contrast Phase Classification with a Generative Adversarial Network
Nov 14, 2019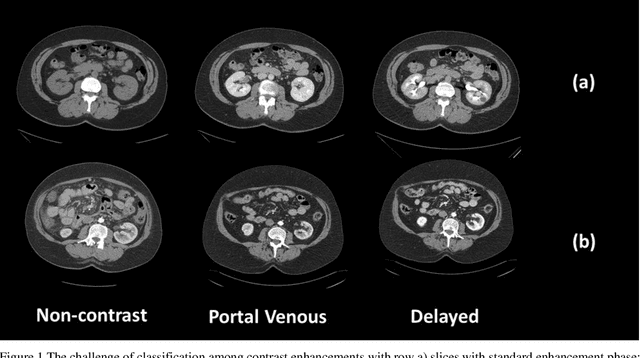
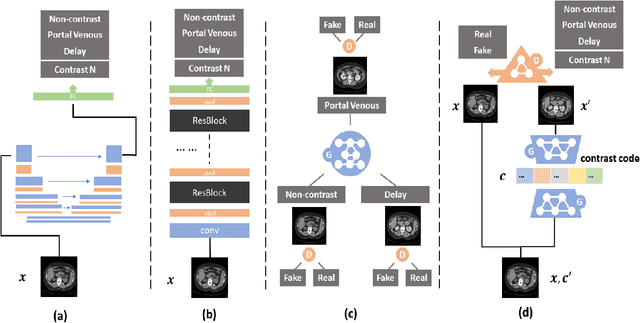
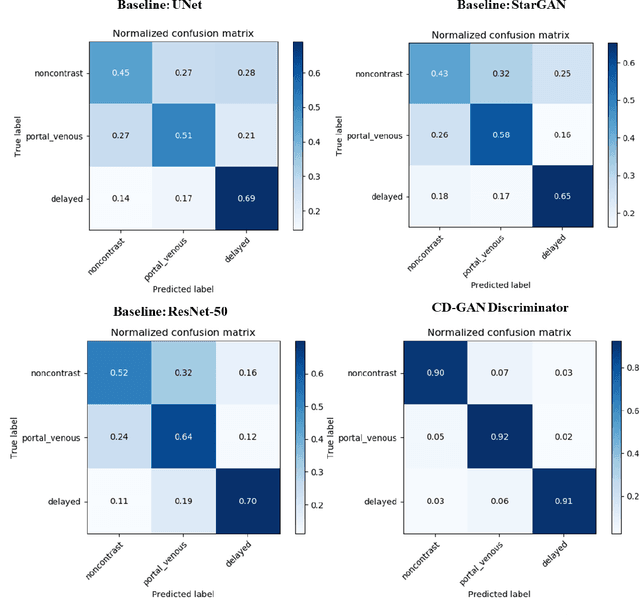
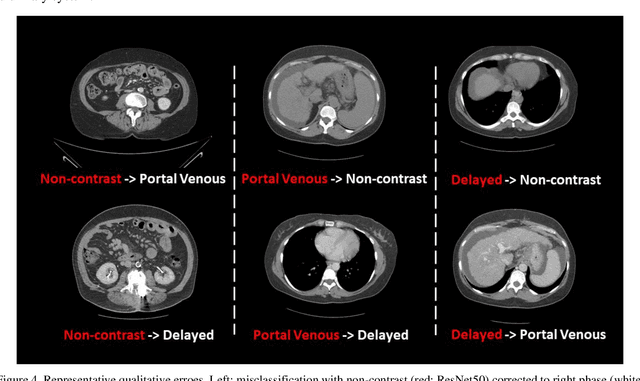
Dynamic contrast enhanced computed tomography (CT) is an imaging technique that provides critical information on the relationship of vascular structure and dynamics in the context of underlying anatomy. A key challenge for image processing with contrast enhanced CT is that phase discrepancies are latent in different tissues due to contrast protocols, vascular dynamics, and metabolism variance. Previous studies with deep learning frameworks have been proposed for classifying contrast enhancement with networks inspired by computer vision. Here, we revisit the challenge in the context of whole abdomen contrast enhanced CTs. To capture and compensate for the complex contrast changes, we propose a novel discriminator in the form of a multi-domain disentangled representation learning network. The goal of this network is to learn an intermediate representation that separates contrast enhancement from anatomy and enables classification of images with varying contrast time. Briefly, our unpaired contrast disentangling GAN(CD-GAN) Discriminator follows the ResNet architecture to classify a CT scan from different enhancement phases. To evaluate the approach, we trained the enhancement phase classifier on 21060 slices from two clinical cohorts of 230 subjects. Testing was performed on 9100 slices from 30 independent subjects who had been imaged with CT scans from all contrast phases. Performance was quantified in terms of the multi-class normalized confusion matrix. The proposed network significantly improved correspondence over baseline UNet, ResNet50 and StarGAN performance of accuracy scores 0.54. 0.55, 0.62 and 0.91, respectively. The proposed discriminator from the disentangled network presents a promising technique that may allow deeper modeling of dynamic imaging against patient specific anatomies.
* 8 pages, 4 figures
Semi-Supervised Multi-Organ Segmentation through Quality Assurance Supervision
Nov 12, 2019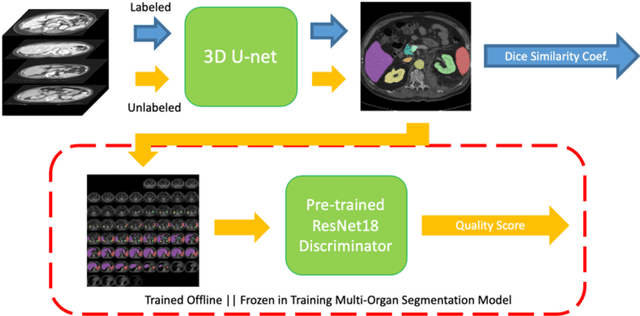
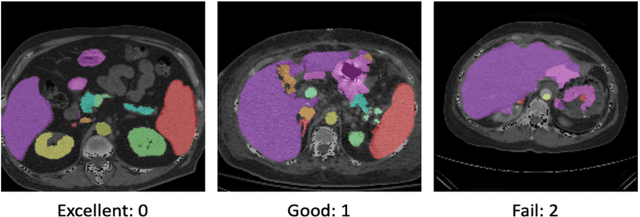
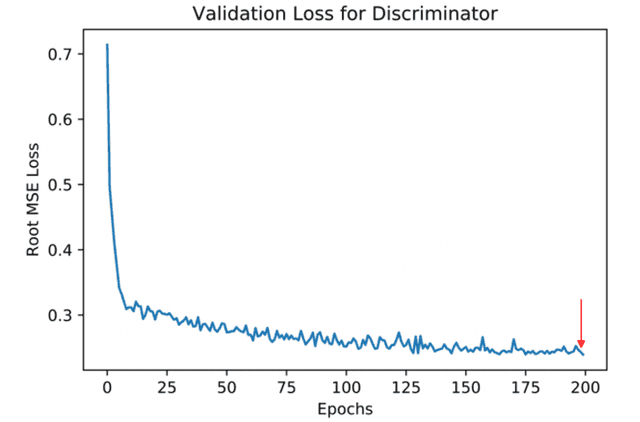
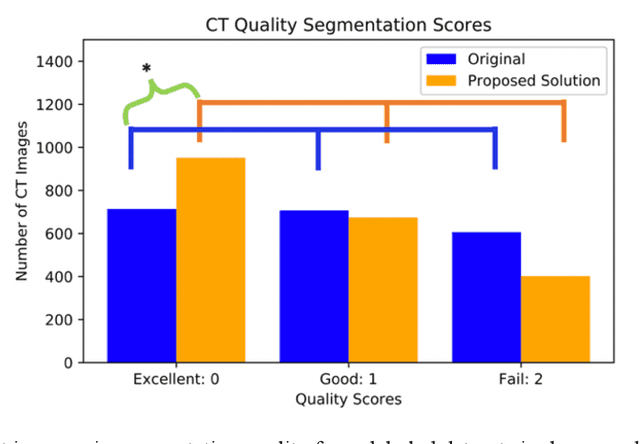
Human in-the-loop quality assurance (QA) is typically performed after medical image segmentation to ensure that the systems are performing as intended, as well as identifying and excluding outliers. By performing QA on large-scale, previously unlabeled testing data, categorical QA scores can be generatedIn this paper, we propose a semi-supervised multi-organ segmentation deep neural network consisting of a traditional segmentation model generator and a QA involved discriminator. A large-scale dataset of 2027 volumes are used to train the generator, whose 2-D montage images and segmentation mask with QA scores are used to train the discriminator. To generate the QA scores, the 2-D montage images were reviewed manually and coded 0 (success), 1 (errors consistent with published performance), and 2 (gross failure). Then, the ResNet-18 network was trained with 1623 montage images in equal distribution of all three code labels and achieved an accuracy 94% for classification predictions with 404 montage images withheld for the test cohort. To assess the performance of using the QA supervision, the discriminator was used as a loss function in a multi-organ segmentation pipeline. The inclusion of QA-loss function boosted performance on the unlabeled test dataset from 714 patients to 951 patients over the baseline model. Additionally, the number of failures decreased from 606 (29.90%) to 402 (19.83%). The contributions of the proposed method are threefold: We show that (1) the QA scores can be used as a loss function to perform semi-supervised learning for unlabeled data, (2) the well trained discriminator is learnt by QA score rather than traditional true/false, and (3) the performance of multi-organ segmentation on unlabeled datasets can be fine-tuned with more robust and higher accuracy than the original baseline method.