 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Targeted Syntactic Evaluation of Language Models
Paper and Code

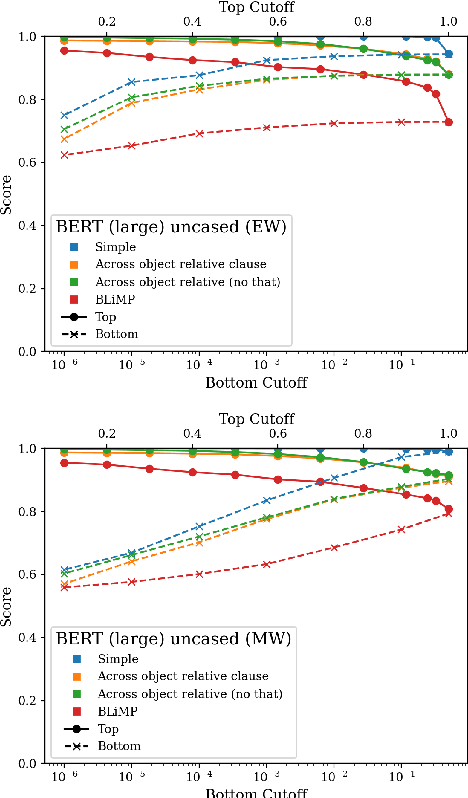
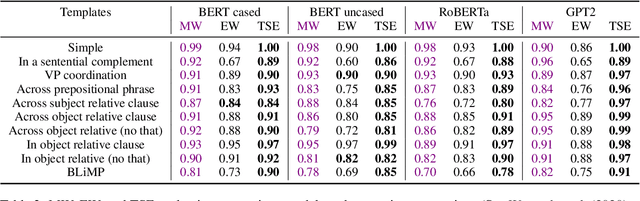
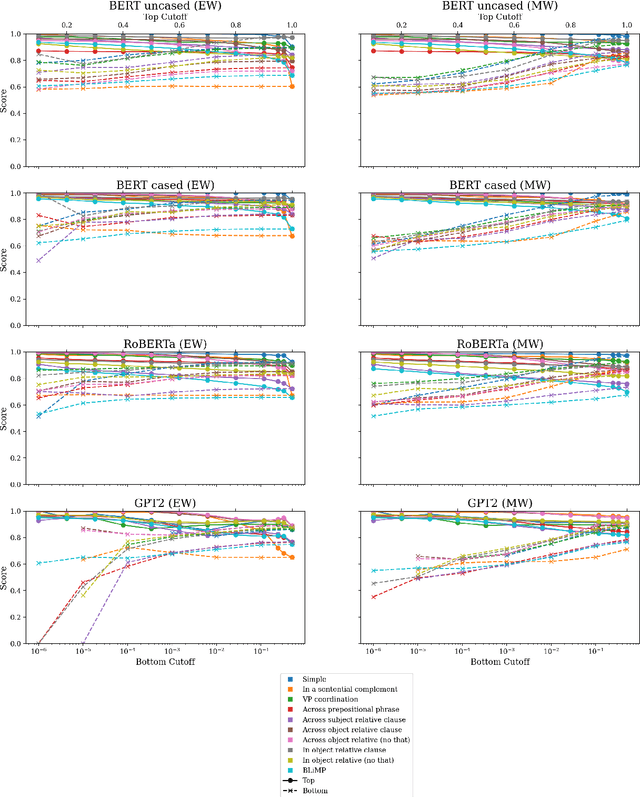
Targeted syntactic evaluation of subject-verb number agreement in English (TSE) evaluates language models' syntactic knowledge using hand-crafted minimal pairs of sentences that differ only in the main verb's conjugation. The method evaluates whether language models rate each grammatical sentence as more likely than its ungrammatical counterpart. We identify two distinct goals for TSE. First, evaluating the systematicity of a language model's syntactic knowledge: given a sentence, can it conjugate arbitrary verbs correctly? Second, evaluating a model's likely behavior: given a sentence, does the model concentrate its probability mass on correctly conjugated verbs, even if only on a subset of the possible verbs? We argue that current implementations of TSE do not directly capture either of these goals, and propose new metrics to capture each goal separately. Under our metrics, we find that TSE overestimates systematicity of language models, but that models score up to 40% better on verbs that they predict are likely in context.