 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
A Systematic Analysis of Hybrid Linear Attention
Jul 08, 2025Transformers face quadratic complexity and memory issues with long sequences, prompting the adoption of linear attention mechanisms using fixed-size hidden states. However, linear models often suffer from limited recall performance, leading to hybrid architectures that combine linear and full attention layers. Despite extensive hybrid architecture research, the choice of linear attention component has not been deeply explored. We systematically evaluate various linear attention models across generations - vector recurrences to advanced gating mechanisms - both standalone and hybridized. To enable this comprehensive analysis, we trained and open-sourced 72 models: 36 at 340M parameters (20B tokens) and 36 at 1.3B parameters (100B tokens), covering six linear attention variants across five hybridization ratios. Benchmarking on standard language modeling and recall tasks reveals that superior standalone linear models do not necessarily excel in hybrids. While language modeling remains stable across linear-to-full attention ratios, recall significantly improves with increased full attention layers, particularly below a 3:1 ratio. Our study highlights selective gating, hierarchical recurrence, and controlled forgetting as critical for effective hybrid models. We recommend architectures such as HGRN-2 or GatedDeltaNet with a linear-to-full ratio between 3:1 and 6:1 to achieve Transformer-level recall efficiently. Our models are open-sourced at https://huggingface.co/collections/m-a-p/hybrid-linear-attention-research-686c488a63d609d2f20e2b1e.
Relational Surrogate Loss Learning
Feb 26, 2022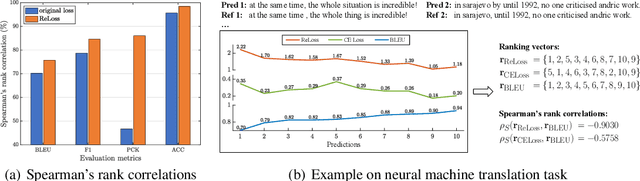
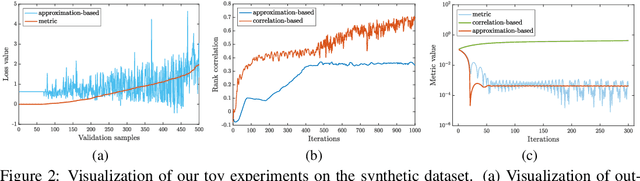
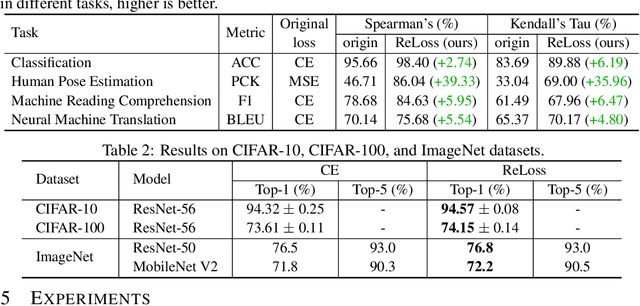
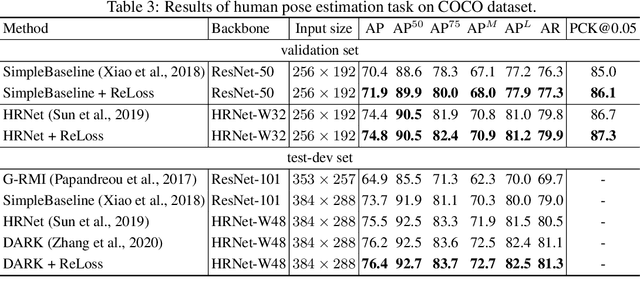
Evaluation metrics in machine learning are often hardly taken as loss functions, as they could be non-differentiable and non-decomposable, e.g., average precision and F1 score. This paper aims to address this problem by revisiting the surrogate loss learning, where a deep neural network is employed to approximate the evaluation metrics. Instead of pursuing an exact recovery of the evaluation metric through a deep neural network, we are reminded of the purpose of the existence of these evaluation metrics, which is to distinguish whether one model is better or worse than another. In this paper, we show that directly maintaining the relation of models between surrogate losses and metrics suffices, and propose a rank correlation-based optimization method to maximize this relation and learn surrogate losses. Compared to previous works, our method is much easier to optimize and enjoys significant efficiency and performance gains. Extensive experiments show that our method achieves improvements on various tasks including image classification and neural machine translation, and even outperforms state-of-the-art methods on human pose estimation and machine reading comprehension tasks. Code is available at: https://github.com/hunto/ReLoss.
Mental Health Assessment for the Chatbots
Jan 14, 2022
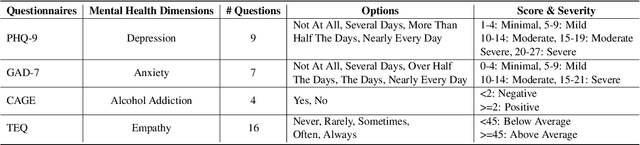
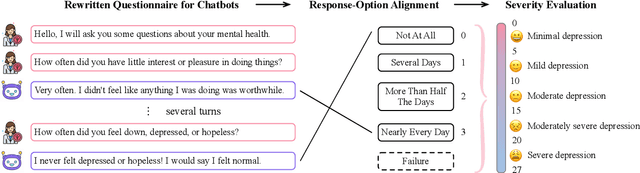

Previous researches on dialogue system assessment usually focus on the quality evaluation (e.g. fluency, relevance, etc) of responses generated by the chatbots, which are local and technical metrics. For a chatbot which responds to millions of online users including minors, we argue that it should have a healthy mental tendency in order to avoid the negative psychological impact on them. In this paper, we establish several mental health assessment dimensions for chatbots (depression, anxiety, alcohol addiction, empathy) and introduce the questionnaire-based mental health assessment methods. We conduct assessments on some well-known open-domain chatbots and find that there are severe mental health issues for all these chatbots. We consider that it is due to the neglect of the mental health risks during the dataset building and the model training procedures. We expect to attract researchers' attention to the serious mental health problems of chatbots and improve the chatbots' ability in positive emotional interaction.
Modeling Coverage for Non-Autoregressive Neural Machine Translation
Apr 24, 2021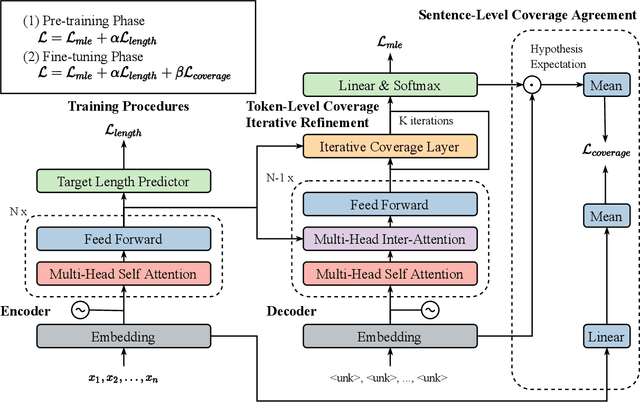
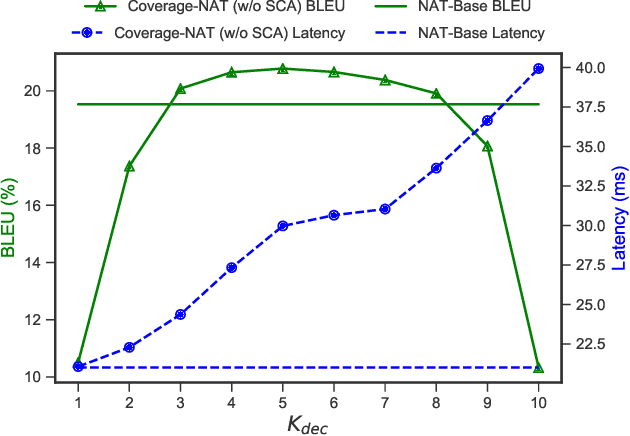

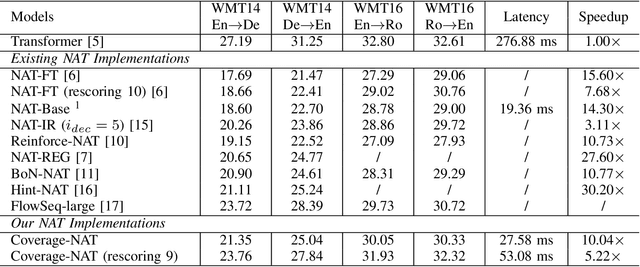
Non-Autoregressive Neural Machine Translation (NAT) has achieved significant inference speedup by generating all tokens simultaneously. Despite its high efficiency, NAT usually suffers from two kinds of translation errors: over-translation (e.g. repeated tokens) and under-translation (e.g. missing translations), which eventually limits the translation quality. In this paper, we argue that these issues of NAT can be addressed through coverage modeling, which has been proved to be useful in autoregressive decoding. We propose a novel Coverage-NAT to model the coverage information directly by a token-level coverage iterative refinement mechanism and a sentence-level coverage agreement, which can remind the model if a source token has been translated or not and improve the semantics consistency between the translation and the source, respectively. Experimental results on WMT14 En-De and WMT16 En-Ro translation tasks show that our method can alleviate those errors and achieve strong improvements over the baseline system.
A Contextual Hierarchical Attention Network with Adaptive Objective for Dialogue State Tracking
Jun 02, 2020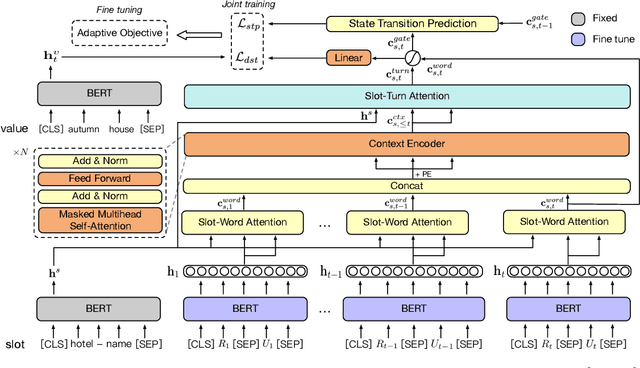
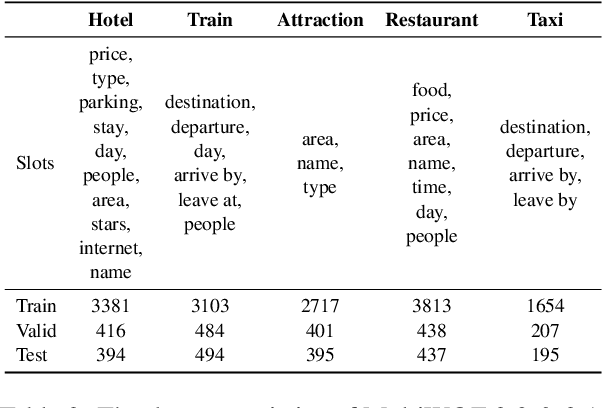


Recent studies in dialogue state tracking (DST) leverage historical information to determine states which are generally represented as slot-value pairs. However, most of them have limitations to efficiently exploit relevant context due to the lack of a powerful mechanism for modeling interactions between the slot and the dialogue history. Besides, existing methods usually ignore the slot imbalance problem and treat all slots indiscriminately, which limits the learning of hard slots and eventually hurts overall performance. In this paper, we propose to enhance the DST through employing a contextual hierarchical attention network to not only discern relevant information at both word level and turn level but also learn contextual representations. We further propose an adaptive objective to alleviate the slot imbalance problem by dynamically adjust weights of different slots during training. Experimental results show that our approach reaches 52.68% and 58.55% joint accuracy on MultiWOZ 2.0 and MultiWOZ 2.1 datasets respectively and achieves new state-of-the-art performance with considerable improvements (+1.24% and +5.98%).
Improving Bidirectional Decoding with Dynamic Target Semantics in Neural Machine Translation
Nov 05, 2019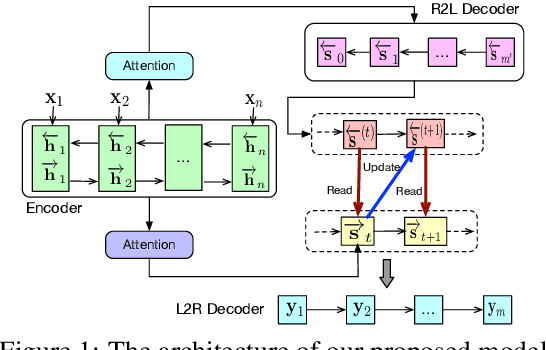


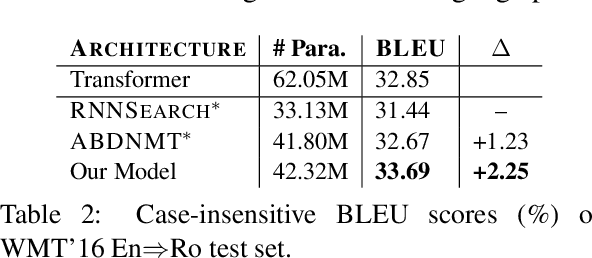
Generally, Neural Machine Translation models generate target words in a left-to-right (L2R) manner and fail to exploit any future (right) semantics information, which usually produces an unbalanced translation. Recent works attempt to utilize the right-to-left (R2L) decoder in bidirectional decoding to alleviate this problem. In this paper, we propose a novel \textbf{D}ynamic \textbf{I}nteraction \textbf{M}odule (\textbf{DIM}) to dynamically exploit target semantics from R2L translation for enhancing the L2R translation quality. Different from other bidirectional decoding approaches, DIM firstly extracts helpful target information through addressing and reading operations, then updates target semantics for tracking the interactive history. Additionally, we further introduce an \textbf{agreement regularization} term into the training objective to narrow the gap between L2R and R2L translations. Experimental results on NIST Chinese$\Rightarrow$English and WMT'16 English$\Rightarrow$Romanian translation tasks show that our system achieves significant improvements over baseline systems, which also reaches comparable results compared to the state-of-the-art Transformer model with much fewer parameters of it.