 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Coverage for Non-Autoregressive Neural Machine Translation
Paper and Code
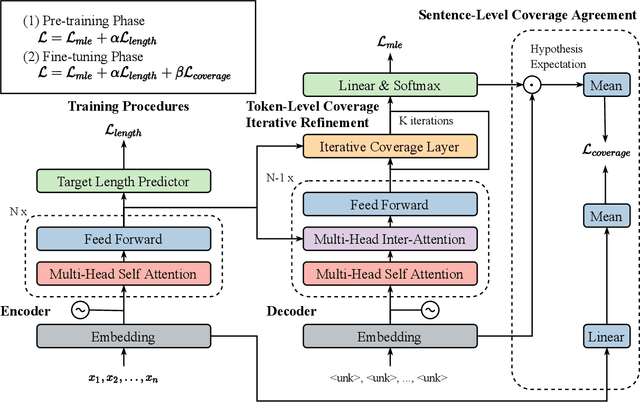
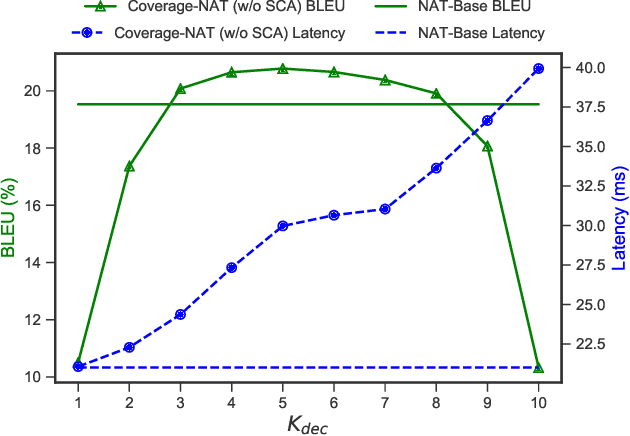

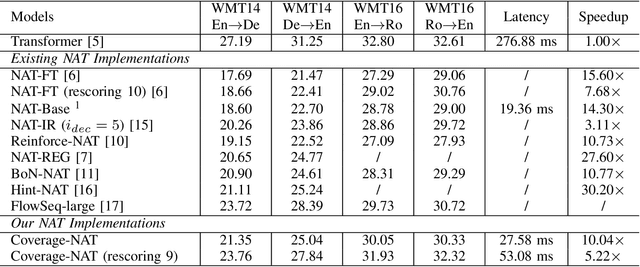
Non-Autoregressive Neural Machine Translation (NAT) has achieved significant inference speedup by generating all tokens simultaneously. Despite its high efficiency, NAT usually suffers from two kinds of translation errors: over-translation (e.g. repeated tokens) and under-translation (e.g. missing translations), which eventually limits the translation quality. In this paper, we argue that these issues of NAT can be addressed through coverage modeling, which has been proved to be useful in autoregressive decoding. We propose a novel Coverage-NAT to model the coverage information directly by a token-level coverage iterative refinement mechanism and a sentence-level coverage agreement, which can remind the model if a source token has been translated or not and improve the semantics consistency between the translation and the source, respectively. Experimental results on WMT14 En-De and WMT16 En-Ro translation tasks show that our method can alleviate those errors and achieve strong improvements over the baseline system.