 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-EAGLE: Parallel-Drafting EAGLE with Scalable Training
Feb 01, 2026Reasoning LLMs produce longer outputs, requiring speculative decoding drafters trained on extended sequences. Parallel drafting - predicting multiple tokens per forward pass - offers latency benefits over sequential generation, but training complexity scales quadratically with the product of sequence length and parallel positions, rendering long-context training impractical. We present P(arallel)-EAGLE, which transforms EAGLE from autoregressive to parallel multi-token prediction via a learnable shared hidden state. To scale training to long contexts, we develop a framework featuring attention mask pre-computation and sequence partitioning techniques, enabling gradient accumulation within individual sequences for parallel-prediction training. We implement P-EAGLE in vLLM and demonstrate speedups of 1.10-1.36x over autoregressive EAGLE-3 across GPT-OSS 120B, 20B, and Qwen3-Coder 30B.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025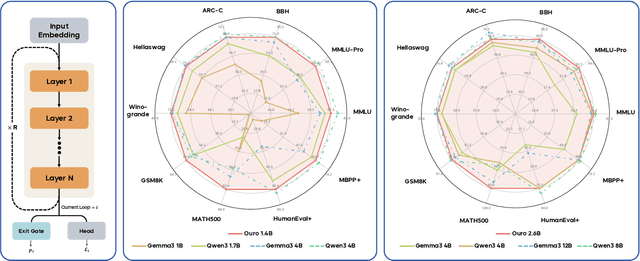
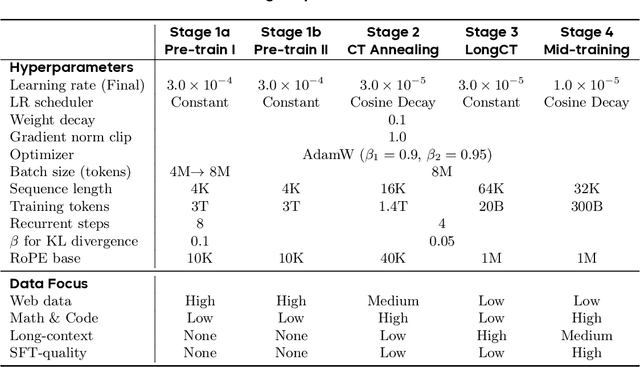
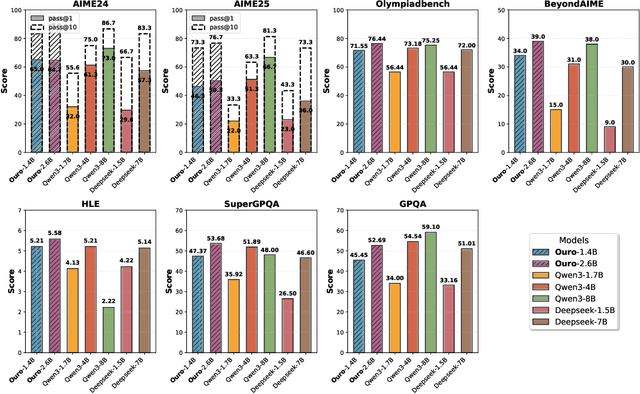

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
$\texttt{Complex-Edit}$: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark
Apr 17, 2025We introduce $\texttt{Complex-Edit}$, a comprehensive benchmark designed to systematically evaluate instruction-based image editing models across instructions of varying complexity. To develop this benchmark, we harness GPT-4o to automatically collect a diverse set of editing instructions at scale. Our approach follows a well-structured ``Chain-of-Edit'' pipeline: we first generate individual atomic editing tasks independently and then integrate them to form cohesive, complex instructions. Additionally, we introduce a suite of metrics to assess various aspects of editing performance, along with a VLM-based auto-evaluation pipeline that supports large-scale assessments. Our benchmark yields several notable insights: 1) Open-source models significantly underperform relative to proprietary, closed-source models, with the performance gap widening as instruction complexity increases; 2) Increased instructional complexity primarily impairs the models' ability to retain key elements from the input images and to preserve the overall aesthetic quality; 3) Decomposing a complex instruction into a sequence of atomic steps, executed in a step-by-step manner, substantially degrades performance across multiple metrics; 4) A straightforward Best-of-N selection strategy improves results for both direct editing and the step-by-step sequential approach; and 5) We observe a ``curse of synthetic data'': when synthetic data is involved in model training, the edited images from such models tend to appear increasingly synthetic as the complexity of the editing instructions rises -- a phenomenon that intriguingly also manifests in the latest GPT-4o outputs.
ARFlow: Autogressive Flow with Hybrid Linear Attention
Jan 27, 2025



Flow models are effective at progressively generating realistic images, but they generally struggle to capture long-range dependencies during the generation process as they compress all the information from previous time steps into a single corrupted image. To address this limitation, we propose integrating autoregressive modeling -- known for its excellence in modeling complex, high-dimensional joint probability distributions -- into flow models. During training, at each step, we construct causally-ordered sequences by sampling multiple images from the same semantic category and applying different levels of noise, where images with higher noise levels serve as causal predecessors to those with lower noise levels. This design enables the model to learn broader category-level variations while maintaining proper causal relationships in the flow process. During generation, the model autoregressively conditions the previously generated images from earlier denoising steps, forming a contextual and coherent generation trajectory. Additionally, we design a customized hybrid linear attention mechanism tailored to our modeling approach to enhance computational efficiency. Our approach, termed ARFlow, under 400k training steps, achieves 14.08 FID scores on ImageNet at 128 * 128 without classifier-free guidance, reaching 4.34 FID with classifier-free guidance 1.5, significantly outperforming the previous flow-based model SiT's 9.17 FID. Extensive ablation studies demonstrate the effectiveness of our modeling strategy and chunk-wise attention design.
FreqMark: Invisible Image Watermarking via Frequency Based Optimization in Latent Space
Oct 28, 2024Invisible watermarking is essential for safeguarding digital content, enabling copyright protection and content authentication. However, existing watermarking methods fall short in robustness against regeneration attacks. In this paper, we propose a novel method called FreqMark that involves unconstrained optimization of the image latent frequency space obtained after VAE encoding. Specifically, FreqMark embeds the watermark by optimizing the latent frequency space of the images and then extracts the watermark through a pre-trained image encoder. This optimization allows a flexible trade-off between image quality with watermark robustness and effectively resists regeneration attacks. Experimental results demonstrate that FreqMark offers significant advantages in image quality and robustness, permits flexible selection of the encoding bit number, and achieves a bit accuracy exceeding 90% when encoding a 48-bit hidden message under various attack scenarios.
Story-Adapter: A Training-free Iterative Framework for Long Story Visualization
Oct 08, 2024



Story visualization, the task of generating coherent images based on a narrative, has seen significant advancements with the emergence of text-to-image models, particularly diffusion models. However, maintaining semantic consistency, generating high-quality fine-grained interactions, and ensuring computational feasibility remain challenging, especially in long story visualization (i.e., up to 100 frames). In this work, we propose a training-free and computationally efficient framework, termed Story-Adapter, to enhance the generative capability of long stories. Specifically, we propose an iterative paradigm to refine each generated image, leveraging both the text prompt and all generated images from the previous iteration. Central to our framework is a training-free global reference cross-attention module, which aggregates all generated images from the previous iteration to preserve semantic consistency across the entire story, while minimizing computational costs with global embeddings. This iterative process progressively optimizes image generation by repeatedly incorporating text constraints, resulting in more precise and fine-grained interactions. Extensive experiments validate the superiority of Story-Adapter in improving both semantic consistency and generative capability for fine-grained interactions, particularly in long story scenarios. The project page and associated code can be accessed via https://jwmao1.github.io/storyadapter .
What If We Recaption Billions of Web Images with LLaMA-3?
Jun 12, 2024



Web-crawled image-text pairs are inherently noisy. Prior studies demonstrate that semantically aligning and enriching textual descriptions of these pairs can significantly enhance model training across various vision-language tasks, particularly text-to-image generation. However, large-scale investigations in this area remain predominantly closed-source. Our paper aims to bridge this community effort, leveraging the powerful and \textit{open-sourced} LLaMA-3, a GPT-4 level LLM. Our recaptioning pipeline is simple: first, we fine-tune a LLaMA-3-8B powered LLaVA-1.5 and then employ it to recaption 1.3 billion images from the DataComp-1B dataset. Our empirical results confirm that this enhanced dataset, Recap-DataComp-1B, offers substantial benefits in training advanced vision-language models. For discriminative models like CLIP, we observe enhanced zero-shot performance in cross-modal retrieval tasks. For generative models like text-to-image Diffusion Transformers, the generated images exhibit a significant improvement in alignment with users' text instructions, especially in following complex queries. Our project page is https://www.haqtu.me/Recap-Datacomp-1B/
HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing
Apr 15, 2024



This study introduces HQ-Edit, a high-quality instruction-based image editing dataset with around 200,000 edits. Unlike prior approaches relying on attribute guidance or human feedback on building datasets, we devise a scalable data collection pipeline leveraging advanced foundation models, namely GPT-4V and DALL-E 3. To ensure its high quality, diverse examples are first collected online, expanded, and then used to create high-quality diptychs featuring input and output images with detailed text prompts, followed by precise alignment ensured through post-processing. In addition, we propose two evaluation metrics, Alignment and Coherence, to quantitatively assess the quality of image edit pairs using GPT-4V. HQ-Edits high-resolution images, rich in detail and accompanied by comprehensive editing prompts, substantially enhance the capabilities of existing image editing models. For example, an HQ-Edit finetuned InstructPix2Pix can attain state-of-the-art image editing performance, even surpassing those models fine-tuned with human-annotated data. The project page is https://thefllood.github.io/HQEdit_web.
MicroDiffusion: Implicit Representation-Guided Diffusion for 3D Reconstruction from Limited 2D Microscopy Projections
Mar 16, 2024Volumetric optical microscopy using non-diffracting beams enables rapid imaging of 3D volumes by projecting them axially to 2D images but lacks crucial depth information. Addressing this, we introduce MicroDiffusion, a pioneering tool facilitating high-quality, depth-resolved 3D volume reconstruction from limited 2D projections. While existing Implicit Neural Representation (INR) models often yield incomplete outputs and Denoising Diffusion Probabilistic Models (DDPM) excel at capturing details, our method integrates INR's structural coherence with DDPM's fine-detail enhancement capabilities. We pretrain an INR model to transform 2D axially-projected images into a preliminary 3D volume. This pretrained INR acts as a global prior guiding DDPM's generative process through a linear interpolation between INR outputs and noise inputs. This strategy enriches the diffusion process with structured 3D information, enhancing detail and reducing noise in localized 2D images. By conditioning the diffusion model on the closest 2D projection, MicroDiffusion substantially enhances fidelity in resulting 3D reconstructions, surpassing INR and standard DDPM outputs with unparalleled image quality and structural fidelity. Our code and dataset are available at https://github.com/UCSC-VLAA/MicroDiffusion.
Unifying Layout Generation with a Decoupled Diffusion Model
Mar 09, 2023



Layout generation aims to synthesize realistic graphic scenes consisting of elements with different attributes including category, size, position, and between-element relation. It is a crucial task for reducing the burden on heavy-duty graphic design works for formatted scenes, e.g., publications, documents, and user interfaces (UIs). Diverse application scenarios impose a big challenge in unifying various layout generation subtasks, including conditional and unconditional generation. In this paper, we propose a Layout Diffusion Generative Model (LDGM) to achieve such unification with a single decoupled diffusion model. LDGM views a layout of arbitrary missing or coarse element attributes as an intermediate diffusion status from a completed layout. Since different attributes have their individual semantics and characteristics, we propose to decouple the diffusion processes for them to improve the diversity of training samples and learn the reverse process jointly to exploit global-scope contexts for facilitating generation. As a result, our LDGM can generate layouts either from scratch or conditional on arbitrary available attributes. Extensive qualitative and quantitative experiments demonstrate our proposed LDGM outperforms existing layout generation models in both functionality and performance.