 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashMesh: Faster and Better Autoregressive Mesh Synthesis via Structured Speculation
Nov 19, 2025Autoregressive models can generate high-quality 3D meshes by sequentially producing vertices and faces, but their token-by-token decoding results in slow inference, limiting practical use in interactive and large-scale applications. We present FlashMesh, a fast and high-fidelity mesh generation framework that rethinks autoregressive decoding through a predict-correct-verify paradigm. The key insight is that mesh tokens exhibit strong structural and geometric correlations that enable confident multi-token speculation. FlashMesh leverages this by introducing a speculative decoding scheme tailored to the commonly used hourglass transformer architecture, enabling parallel prediction across face, point, and coordinate levels. Extensive experiments show that FlashMesh achieves up to a 2 x speedup over standard autoregressive models while also improving generation fidelity. Our results demonstrate that structural priors in mesh data can be systematically harnessed to accelerate and enhance autoregressive generation.
PartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data
Sep 26, 2025Segmenting 3D objects into parts is a long-standing challenge in computer vision. To overcome taxonomy constraints and generalize to unseen 3D objects, recent works turn to open-world part segmentation. These approaches typically transfer supervision from 2D foundation models, such as SAM, by lifting multi-view masks into 3D. However, this indirect paradigm fails to capture intrinsic geometry, leading to surface-only understanding, uncontrolled decomposition, and limited generalization. We present PartSAM, the first promptable part segmentation model trained natively on large-scale 3D data. Following the design philosophy of SAM, PartSAM employs an encoder-decoder architecture in which a triplane-based dual-branch encoder produces spatially structured tokens for scalable part-aware representation learning. To enable large-scale supervision, we further introduce a model-in-the-loop annotation pipeline that curates over five million 3D shape-part pairs from online assets, providing diverse and fine-grained labels. This combination of scalable architecture and diverse 3D data yields emergent open-world capabilities: with a single prompt, PartSAM achieves highly accurate part identification, and in a Segment-Every-Part mode, it automatically decomposes shapes into both surface and internal structures. Extensive experiments show that PartSAM outperforms state-of-the-art methods by large margins across multiple benchmarks, marking a decisive step toward foundation models for 3D part understanding. Our code and model will be released soon.
FreqMark: Invisible Image Watermarking via Frequency Based Optimization in Latent Space
Oct 28, 2024Invisible watermarking is essential for safeguarding digital content, enabling copyright protection and content authentication. However, existing watermarking methods fall short in robustness against regeneration attacks. In this paper, we propose a novel method called FreqMark that involves unconstrained optimization of the image latent frequency space obtained after VAE encoding. Specifically, FreqMark embeds the watermark by optimizing the latent frequency space of the images and then extracts the watermark through a pre-trained image encoder. This optimization allows a flexible trade-off between image quality with watermark robustness and effectively resists regeneration attacks. Experimental results demonstrate that FreqMark offers significant advantages in image quality and robustness, permits flexible selection of the encoding bit number, and achieves a bit accuracy exceeding 90% when encoding a 48-bit hidden message under various attack scenarios.
SEABO: A Simple Search-Based Method for Offline Imitation Learning
Feb 06, 2024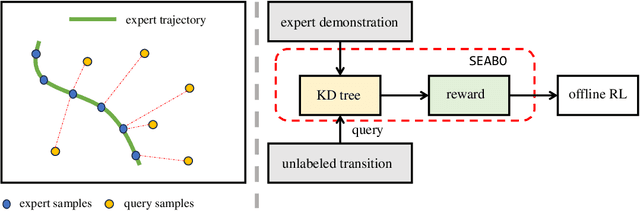
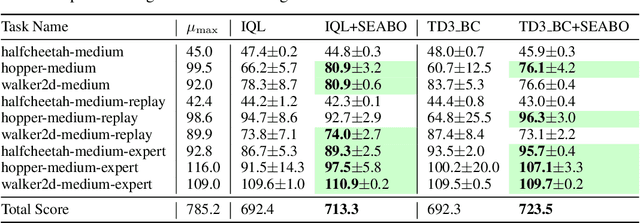
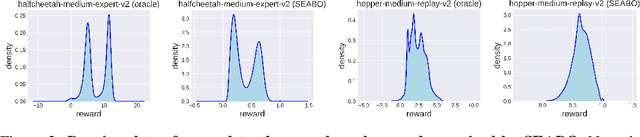

Offline reinforcement learning (RL) has attracted much attention due to its ability in learning from static offline datasets and eliminating the need of interacting with the environment. Nevertheless, the success of offline RL relies heavily on the offline transitions annotated with reward labels. In practice, we often need to hand-craft the reward function, which is sometimes difficult, labor-intensive, or inefficient. To tackle this challenge, we set our focus on the offline imitation learning (IL) setting, and aim at getting a reward function based on the expert data and unlabeled data. To that end, we propose a simple yet effective search-based offline IL method, tagged SEABO. SEABO allocates a larger reward to the transition that is close to its closest neighbor in the expert demonstration, and a smaller reward otherwise, all in an unsupervised learning manner. Experimental results on a variety of D4RL datasets indicate that SEABO can achieve competitive performance to offline RL algorithms with ground-truth rewards, given only a single expert trajectory, and can outperform prior reward learning and offline IL methods across many tasks. Moreover, we demonstrate that SEABO also works well if the expert demonstrations contain only observations. Our code is publicly available at https://github.com/dmksjfl/SEABO.
Understanding What Affects Generalization Gap in Visual Reinforcement Learning: Theory and Empirical Evidence
Feb 05, 2024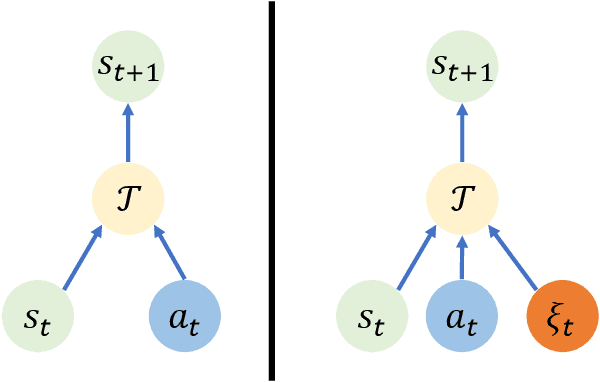


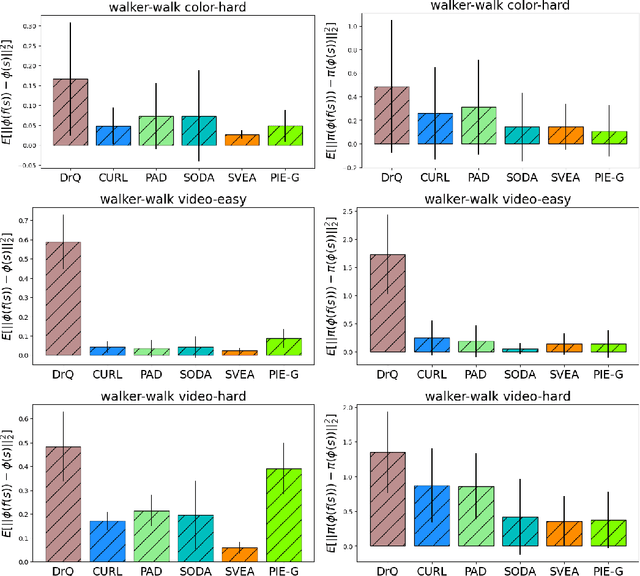
Recently, there are many efforts attempting to learn useful policies for continuous control in visual reinforcement learning (RL). In this scenario, it is important to learn a generalizable policy, as the testing environment may differ from the training environment, e.g., there exist distractors during deployment. Many practical algorithms are proposed to handle this problem. However, to the best of our knowledge, none of them provide a theoretical understanding of what affects the generalization gap and why their proposed methods work. In this paper, we bridge this issue by theoretically answering the key factors that contribute to the generalization gap when the testing environment has distractors. Our theories indicate that minimizing the representation distance between training and testing environments, which aligns with human intuition, is the most critical for the benefit of reducing the generalization gap. Our theoretical results are supported by the empirical evidence in the DMControl Generalization Benchmark (DMC-GB).
Off-Policy RL Algorithms Can be Sample-Efficient for Continuous Control via Sample Multiple Reuse
May 29, 2023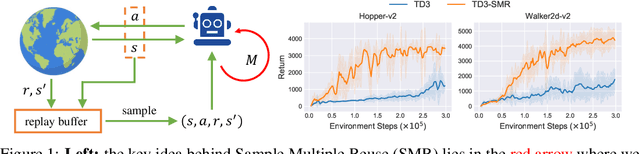
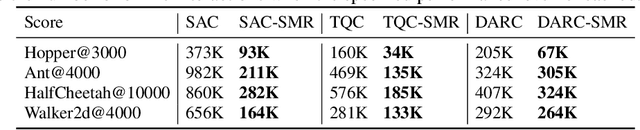
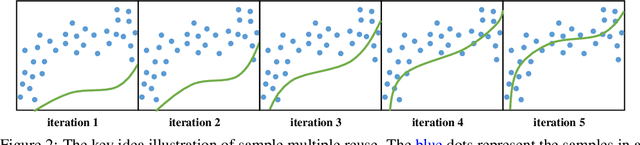
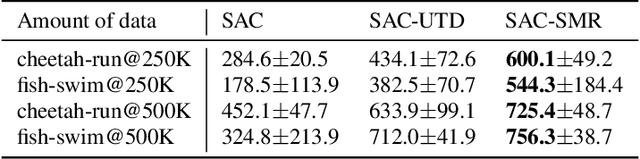
Sample efficiency is one of the most critical issues for online reinforcement learning (RL). Existing methods achieve higher sample efficiency by adopting model-based methods, Q-ensemble, or better exploration mechanisms. We, instead, propose to train an off-policy RL agent via updating on a fixed sampled batch multiple times, thus reusing these samples and better exploiting them within a single optimization loop. We name our method sample multiple reuse (SMR). We theoretically show the properties of Q-learning with SMR, e.g., convergence. Furthermore, we incorporate SMR with off-the-shelf off-policy RL algorithms and conduct experiments on a variety of continuous control benchmarks. Empirical results show that SMR significantly boosts the sample efficiency of the base methods across most of the evaluated tasks without any hyperparameter tuning or additional tricks.
Uncertainty-driven Trajectory Truncation for Model-based Offline Reinforcement Learning
Apr 10, 2023



Equipped with the trained environmental dynamics, model-based offline reinforcement learning (RL) algorithms can often successfully learn good policies from fixed-sized datasets, even some datasets with poor quality. Unfortunately, however, it can not be guaranteed that the generated samples from the trained dynamics model are reliable (e.g., some synthetic samples may lie outside of the support region of the static dataset). To address this issue, we propose Trajectory Truncation with Uncertainty (TATU), which adaptively truncates the synthetic trajectory if the accumulated uncertainty along the trajectory is too large. We theoretically show the performance bound of TATU to justify its benefits. To empirically show the advantages of TATU, we first combine it with two classical model-based offline RL algorithms, MOPO and COMBO. Furthermore, we integrate TATU with several off-the-shelf model-free offline RL algorithms, e.g., BCQ. Experimental results on the D4RL benchmark show that TATU significantly improves their performance, often by a large margin.
State Advantage Weighting for Offline RL
Oct 09, 2022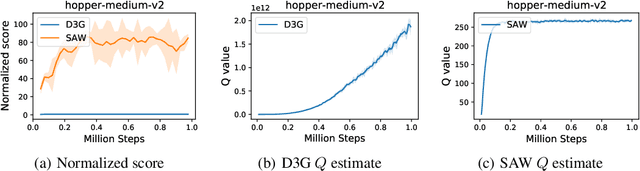
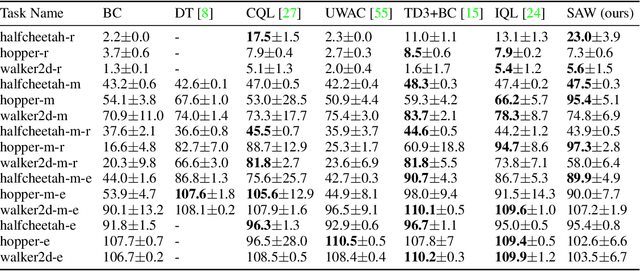

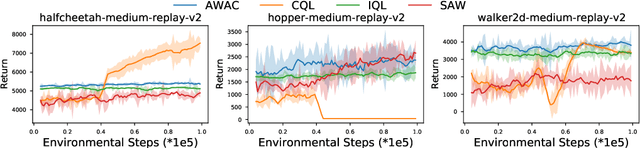
We present state advantage weighting for offline reinforcement learning (RL). In contrast to action advantage $A(s,a)$ that we commonly adopt in QSA learning, we leverage state advantage $A(s,s^\prime)$ and QSS learning for offline RL, hence decoupling the action from values. We expect the agent can get to the high-reward state and the action is determined by how the agent can get to that corresponding state. Experiments on D4RL datasets show that our proposed method can achieve remarkable performance against the common baselines. Furthermore, our method shows good generalization capability when transferring from offline to online.