 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Cognitive Gap: Hierarchical Description Learning for Artistic Image Aesthetics Assessment
Dec 29, 2025The aesthetic quality assessment task is crucial for developing a human-aligned quantitative evaluation system for AIGC. However, its inherently complex nature, spanning visual perception, cognition, and emotion, poses fundamental challenges. Although aesthetic descriptions offer a viable representation of this complexity, two critical challenges persist: (1) data scarcity and imbalance: existing dataset overly focuses on visual perception and neglects deeper dimensions due to the expensive manual annotation; and (2) model fragmentation: current visual networks isolate aesthetic attributes with multi-branch encoder, while multimodal methods represented by contrastive learning struggle to effectively process long-form textual descriptions. To resolve challenge (1), we first present the Refined Aesthetic Description (RAD) dataset, a large-scale (70k), multi-dimensional structured dataset, generated via an iterative pipeline without heavy annotation costs and easy to scale. To address challenge (2), we propose ArtQuant, an aesthetics assessment framework for artistic images which not only couples isolated aesthetic dimensions through joint description generation, but also better models long-text semantics with the help of LLM decoders. Besides, theoretical analysis confirms this symbiosis: RAD's semantic adequacy (data) and generation paradigm (model) collectively minimize prediction entropy, providing mathematical grounding for the framework. Our approach achieves state-of-the-art performance on several datasets while requiring only 33% of conventional training epochs, narrowing the cognitive gap between artistic images and aesthetic judgment. We will release both code and dataset to support future research.
Semi-supervised Semantic Segmentation Meets Masked Modeling:Fine-grained Locality Learning Matters in Consistency Regularization
Dec 14, 2023



Semi-supervised semantic segmentation aims to utilize limited labeled images and abundant unlabeled images to achieve label-efficient learning, wherein the weak-to-strong consistency regularization framework, popularized by FixMatch, is widely used as a benchmark scheme. Despite its effectiveness, we observe that such scheme struggles with satisfactory segmentation for the local regions. This can be because it originally stems from the image classification task and lacks specialized mechanisms to capture fine-grained local semantics that prioritizes in dense prediction. To address this issue, we propose a novel framework called \texttt{MaskMatch}, which enables fine-grained locality learning to achieve better dense segmentation. On top of the original teacher-student framework, we design a masked modeling proxy task that encourages the student model to predict the segmentation given the unmasked image patches (even with 30\% only) and enforces the predictions to be consistent with pseudo-labels generated by the teacher model using the complete image. Such design is motivated by the intuition that if the predictions are more consistent given insufficient neighboring information, stronger fine-grained locality perception is achieved. Besides, recognizing the importance of reliable pseudo-labels in the above locality learning and the original consistency learning scheme, we design a multi-scale ensembling strategy that considers context at different levels of abstraction for pseudo-label generation. Extensive experiments on benchmark datasets demonstrate the superiority of our method against previous approaches and its plug-and-play flexibility.
HQG-Net: Unpaired Medical Image Enhancement with High-Quality Guidance
Jul 15, 2023
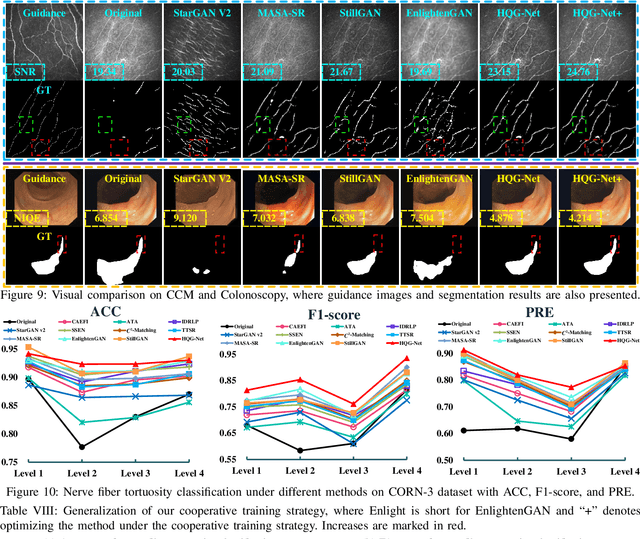

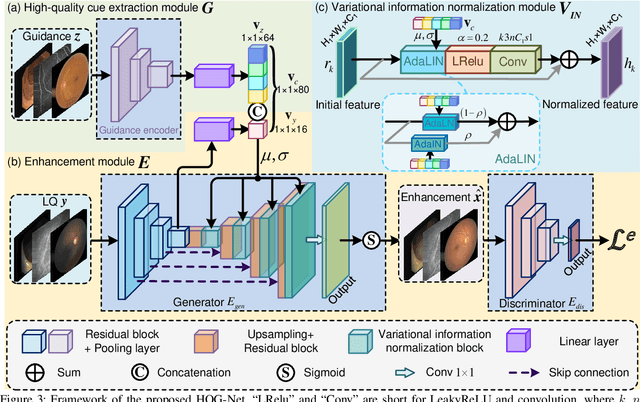
Unpaired Medical Image Enhancement (UMIE) aims to transform a low-quality (LQ) medical image into a high-quality (HQ) one without relying on paired images for training. While most existing approaches are based on Pix2Pix/CycleGAN and are effective to some extent, they fail to explicitly use HQ information to guide the enhancement process, which can lead to undesired artifacts and structural distortions. In this paper, we propose a novel UMIE approach that avoids the above limitation of existing methods by directly encoding HQ cues into the LQ enhancement process in a variational fashion and thus model the UMIE task under the joint distribution between the LQ and HQ domains. Specifically, we extract features from an HQ image and explicitly insert the features, which are expected to encode HQ cues, into the enhancement network to guide the LQ enhancement with the variational normalization module. We train the enhancement network adversarially with a discriminator to ensure the generated HQ image falls into the HQ domain. We further propose a content-aware loss to guide the enhancement process with wavelet-based pixel-level and multi-encoder-based feature-level constraints. Additionally, as a key motivation for performing image enhancement is to make the enhanced images serve better for downstream tasks, we propose a bi-level learning scheme to optimize the UMIE task and downstream tasks cooperatively, helping generate HQ images both visually appealing and favorable for downstream tasks. Experiments on three medical datasets, including two newly collected datasets, verify that the proposed method outperforms existing techniques in terms of both enhancement quality and downstream task performance. We will make the code and the newly collected datasets publicly available for community study.
Uncertainty-driven Trajectory Truncation for Model-based Offline Reinforcement Learning
Apr 10, 2023



Equipped with the trained environmental dynamics, model-based offline reinforcement learning (RL) algorithms can often successfully learn good policies from fixed-sized datasets, even some datasets with poor quality. Unfortunately, however, it can not be guaranteed that the generated samples from the trained dynamics model are reliable (e.g., some synthetic samples may lie outside of the support region of the static dataset). To address this issue, we propose Trajectory Truncation with Uncertainty (TATU), which adaptively truncates the synthetic trajectory if the accumulated uncertainty along the trajectory is too large. We theoretically show the performance bound of TATU to justify its benefits. To empirically show the advantages of TATU, we first combine it with two classical model-based offline RL algorithms, MOPO and COMBO. Furthermore, we integrate TATU with several off-the-shelf model-free offline RL algorithms, e.g., BCQ. Experimental results on the D4RL benchmark show that TATU significantly improves their performance, often by a large margin.
Human-machine Interactive Tissue Prototype Learning for Label-efficient Histopathology Image Segmentation
Nov 26, 2022Recently, deep neural networks have greatly advanced histopathology image segmentation but usually require abundant annotated data. However, due to the gigapixel scale of whole slide images and pathologists' heavy daily workload, obtaining pixel-level labels for supervised learning in clinical practice is often infeasible. Alternatively, weakly-supervised segmentation methods have been explored with less laborious image-level labels, but their performance is unsatisfactory due to the lack of dense supervision. Inspired by the recent success of self-supervised learning methods, we present a label-efficient tissue prototype dictionary building pipeline and propose to use the obtained prototypes to guide histopathology image segmentation. Particularly, taking advantage of self-supervised contrastive learning, an encoder is trained to project the unlabeled histopathology image patches into a discriminative embedding space where these patches are clustered to identify the tissue prototypes by efficient pathologists' visual examination. Then, the encoder is used to map the images into the embedding space and generate pixel-level pseudo tissue masks by querying the tissue prototype dictionary. Finally, the pseudo masks are used to train a segmentation network with dense supervision for better performance. Experiments on two public datasets demonstrate that our human-machine interactive tissue prototype learning method can achieve comparable segmentation performance as the fully-supervised baselines with less annotation burden and outperform other weakly-supervised methods. Codes will be available upon publication.
Seeking Common Ground While Reserving Differences: Multiple Anatomy Collaborative Framework for Undersampled MRI Reconstruction
Jun 16, 2022
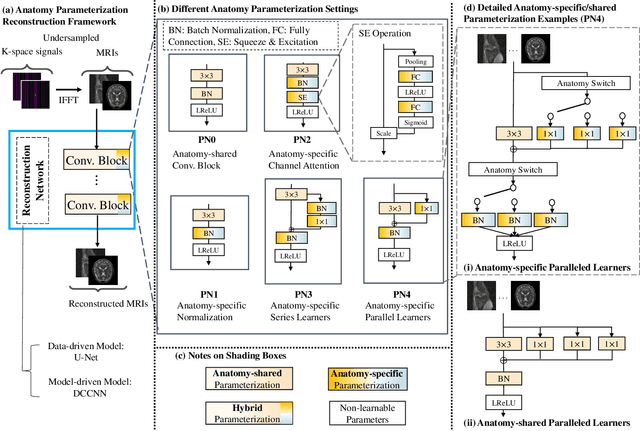
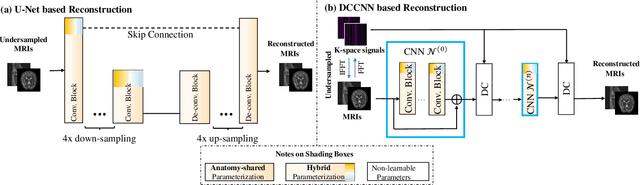
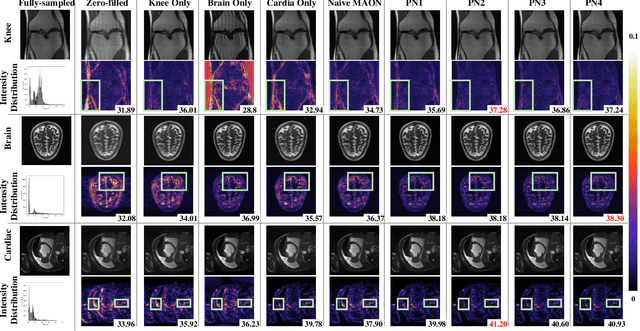
Recently, deep neural networks have greatly advanced undersampled Magnetic Resonance Image (MRI) reconstruction, wherein most studies follow the one-anatomy-one-network fashion, i.e., each expert network is trained and evaluated for a specific anatomy. Apart from inefficiency in training multiple independent models, such convention ignores the shared de-aliasing knowledge across various anatomies which can benefit each other. To explore the shared knowledge, one naive way is to combine all the data from various anatomies to train an all-round network. Unfortunately, despite the existence of the shared de-aliasing knowledge, we reveal that the exclusive knowledge across different anatomies can deteriorate specific reconstruction targets, yielding overall performance degradation. Observing this, in this study, we present a novel deep MRI reconstruction framework with both anatomy-shared and anatomy-specific parameterized learners, aiming to "seek common ground while reserving differences" across different anatomies.Particularly, the primary anatomy-shared learners are exposed to different anatomies to model flourishing shared knowledge, while the efficient anatomy-specific learners are trained with their target anatomy for exclusive knowledge. Four different implementations of anatomy-specific learners are presented and explored on the top of our framework in two MRI reconstruction networks. Comprehensive experiments on brain, knee and cardiac MRI datasets demonstrate that three of these learners are able to enhance reconstruction performance via multiple anatomy collaborative learning.
UniInst: Unique Representation for End-to-End Instance Segmentation
May 26, 2022

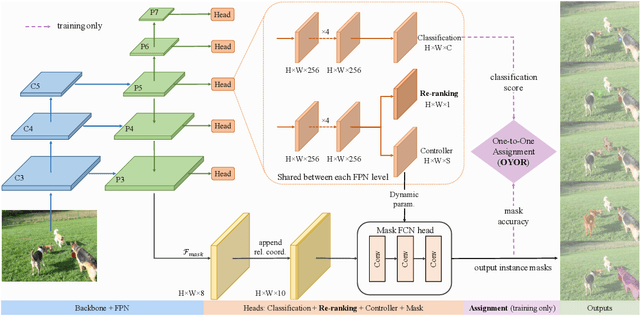

Existing instance segmentation methods have achieved impressive performance but still suffer from a common dilemma: redundant representations (e.g., multiple boxes, grids, and anchor points) are inferred for one instance, which leads to multiple duplicated predictions. Thus, mainstream methods usually rely on a hand-designed non-maximum suppression (NMS) post-processing step to select the optimal prediction result, which hinders end-to-end training. To address this issue, we propose a box-free and NMS-free end-to-end instance segmentation framework, termed UniInst, that yields only one unique representation for each instance. Specifically, we design an instance-aware one-to-one assignment scheme, namely Only Yield One Representation (OYOR), which dynamically assigns one unique representation to each instance according to the matching quality between predictions and ground truths. Then, a novel prediction re-ranking strategy is elegantly integrated into the framework to address the misalignment between the classification score and the mask quality, enabling the learned representation to be more discriminative. With these techniques, our UniInst, the first FCN-based end-to-end instance segmentation framework, achieves competitive performance, e.g., 39.0 mask AP using ResNet-50-FPN and 40.2 mask AP using ResNet-101-FPN, against mainstream methods on COCO test-dev. Moreover, the proposed instance-aware method is robust to occlusion scenes, outperforming common baselines by remarkable mask AP on the heavily-occluded OCHuman benchmark. Our codes will be available upon publication.
Towards better understanding and better generalization of few-shot classification in histology images with contrastive learning
Feb 18, 2022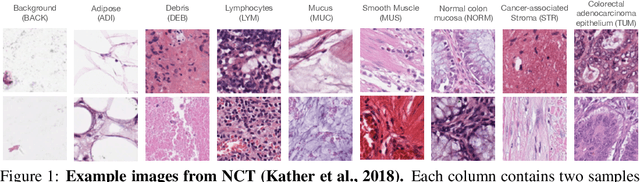
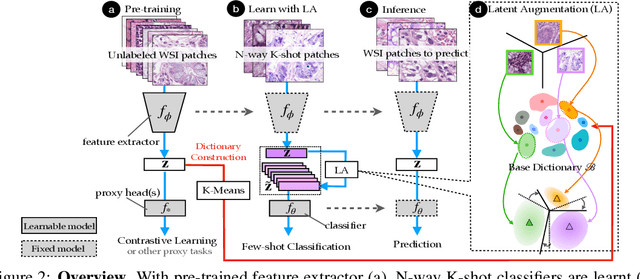


Few-shot learning is an established topic in natural images for years, but few work is attended to histology images, which is of high clinical value since well-labeled datasets and rare abnormal samples are expensive to collect. Here, we facilitate the study of few-shot learning in histology images by setting up three cross-domain tasks that simulate real clinics problems. To enable label-efficient learning and better generalizability, we propose to incorporate contrastive learning (CL) with latent augmentation (LA) to build a few-shot system. CL learns useful representations without manual labels, while LA transfers semantic variations of the base dataset in an unsupervised way. These two components fully exploit unlabeled training data and can scale gracefully to other label-hungry problems. In experiments, we find i) models learned by CL generalize better than supervised learning for histology images in unseen classes, and ii) LA brings consistent gains over baselines. Prior studies of self-supervised learning mainly focus on ImageNet-like images, which only present a dominant object in their centers. Recent attention has been paid to images with multi-objects and multi-textures. Histology images are a natural choice for such a study. We show the superiority of CL over supervised learning in terms of generalization for such data and provide our empirical understanding for this observation. The findings in this work could contribute to understanding how the model generalizes in the context of both representation learning and histological image analysis. Code is available.
Value Activation for Bias Alleviation: Generalized-activated Deep Double Deterministic Policy Gradients
Dec 21, 2021

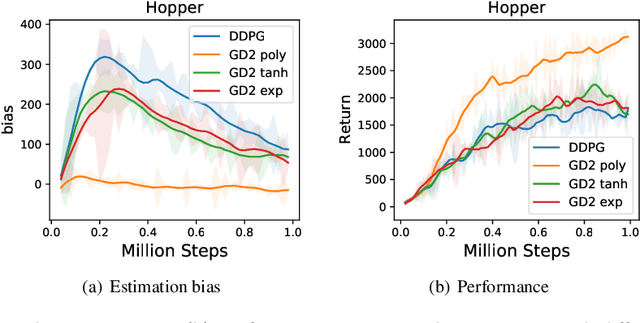

It is vital to accurately estimate the value function in Deep Reinforcement Learning (DRL) such that the agent could execute proper actions instead of suboptimal ones. However, existing actor-critic methods suffer more or less from underestimation bias or overestimation bias, which negatively affect their performance. In this paper, we reveal a simple but effective principle: proper value correction benefits bias alleviation, where we propose the generalized-activated weighting operator that uses any non-decreasing function, namely activation function, as weights for better value estimation. Particularly, we integrate the generalized-activated weighting operator into value estimation and introduce a novel algorithm, Generalized-activated Deep Double Deterministic Policy Gradients (GD3). We theoretically show that GD3 is capable of alleviating the potential estimation bias. We interestingly find that simple activation functions lead to satisfying performance with no additional tricks, and could contribute to faster convergence. Experimental results on numerous challenging continuous control tasks show that GD3 with task-specific activation outperforms the common baseline methods. We also uncover a fact that fine-tuning the polynomial activation function achieves superior results on most of the tasks.
Implicit Feature Refinement for Instance Segmentation
Dec 09, 2021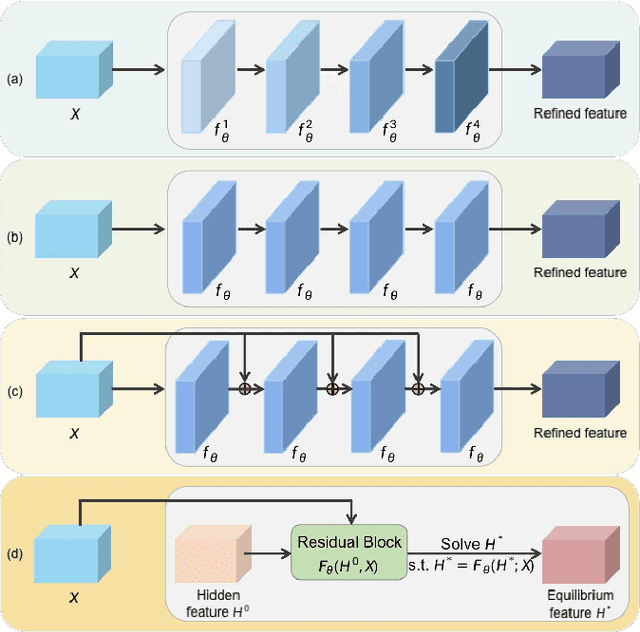

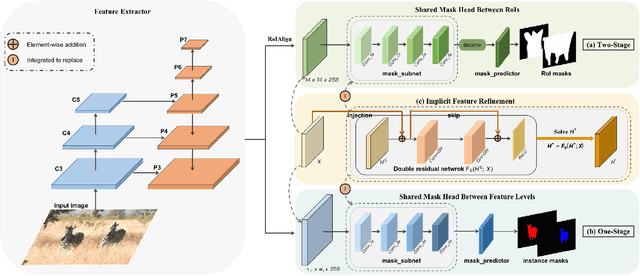
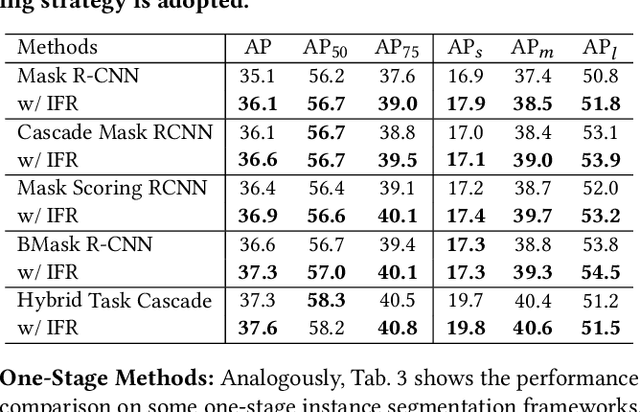
We propose a novel implicit feature refinement module for high-quality instance segmentation. Existing image/video instance segmentation methods rely on explicitly stacked convolutions to refine instance features before the final prediction. In this paper, we first give an empirical comparison of different refinement strategies,which reveals that the widely-used four consecutive convolutions are not necessary. As an alternative, weight-sharing convolution blocks provides competitive performance. When such block is iterated for infinite times, the block output will eventually convergeto an equilibrium state. Based on this observation, the implicit feature refinement (IFR) is developed by constructing an implicit function. The equilibrium state of instance features can be obtained by fixed-point iteration via a simulated infinite-depth network. Our IFR enjoys several advantages: 1) simulates an infinite-depth refinement network while only requiring parameters of single residual block; 2) produces high-level equilibrium instance features of global receptive field; 3) serves as a plug-and-play general module easily extended to most object recognition frameworks. Experiments on the COCO and YouTube-VIS benchmarks show that our IFR achieves improved performance on state-of-the-art image/video instance segmentation frameworks, while reducing the parameter burden (e.g.1% AP improvement on Mask R-CNN with only 30.0% parameters in mask head). Code is made available at https://github.com/lufanma/IFR.git