 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTumorGen: Boundary-Aware Tumor-Mask Synthesis with Rectified Flow Matching
May 30, 2025


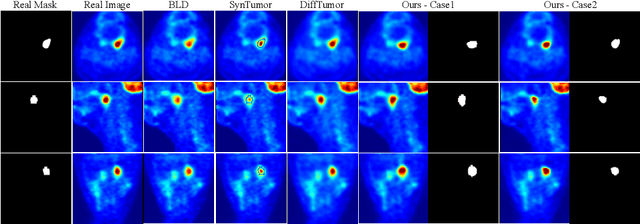
Tumor data synthesis offers a promising solution to the shortage of annotated medical datasets. However, current approaches either limit tumor diversity by using predefined masks or employ computationally expensive two-stage processes with multiple denoising steps, causing computational inefficiency. Additionally, these methods typically rely on binary masks that fail to capture the gradual transitions characteristic of tumor boundaries. We present TumorGen, a novel Boundary-Aware Tumor-Mask Synthesis with Rectified Flow Matching for efficient 3D tumor synthesis with three key components: a Boundary-Aware Pseudo Mask Generation module that replaces strict binary masks with flexible bounding boxes; a Spatial-Constraint Vector Field Estimator that simultaneously synthesizes tumor latents and masks using rectified flow matching to ensure computational efficiency; and a VAE-guided mask refiner that enhances boundary realism. TumorGen significantly improves computational efficiency by requiring fewer sampling steps while maintaining pathological accuracy through coarse and fine-grained spatial constraints. Experimental results demonstrate TumorGen's superior performance over existing tumor synthesis methods in both efficiency and realism, offering a valuable contribution to AI-driven cancer diagnostics.
Semi-supervised Semantic Segmentation Meets Masked Modeling:Fine-grained Locality Learning Matters in Consistency Regularization
Dec 14, 2023



Semi-supervised semantic segmentation aims to utilize limited labeled images and abundant unlabeled images to achieve label-efficient learning, wherein the weak-to-strong consistency regularization framework, popularized by FixMatch, is widely used as a benchmark scheme. Despite its effectiveness, we observe that such scheme struggles with satisfactory segmentation for the local regions. This can be because it originally stems from the image classification task and lacks specialized mechanisms to capture fine-grained local semantics that prioritizes in dense prediction. To address this issue, we propose a novel framework called \texttt{MaskMatch}, which enables fine-grained locality learning to achieve better dense segmentation. On top of the original teacher-student framework, we design a masked modeling proxy task that encourages the student model to predict the segmentation given the unmasked image patches (even with 30\% only) and enforces the predictions to be consistent with pseudo-labels generated by the teacher model using the complete image. Such design is motivated by the intuition that if the predictions are more consistent given insufficient neighboring information, stronger fine-grained locality perception is achieved. Besides, recognizing the importance of reliable pseudo-labels in the above locality learning and the original consistency learning scheme, we design a multi-scale ensembling strategy that considers context at different levels of abstraction for pseudo-label generation. Extensive experiments on benchmark datasets demonstrate the superiority of our method against previous approaches and its plug-and-play flexibility.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Human-machine Interactive Tissue Prototype Learning for Label-efficient Histopathology Image Segmentation
Nov 26, 2022Recently, deep neural networks have greatly advanced histopathology image segmentation but usually require abundant annotated data. However, due to the gigapixel scale of whole slide images and pathologists' heavy daily workload, obtaining pixel-level labels for supervised learning in clinical practice is often infeasible. Alternatively, weakly-supervised segmentation methods have been explored with less laborious image-level labels, but their performance is unsatisfactory due to the lack of dense supervision. Inspired by the recent success of self-supervised learning methods, we present a label-efficient tissue prototype dictionary building pipeline and propose to use the obtained prototypes to guide histopathology image segmentation. Particularly, taking advantage of self-supervised contrastive learning, an encoder is trained to project the unlabeled histopathology image patches into a discriminative embedding space where these patches are clustered to identify the tissue prototypes by efficient pathologists' visual examination. Then, the encoder is used to map the images into the embedding space and generate pixel-level pseudo tissue masks by querying the tissue prototype dictionary. Finally, the pseudo masks are used to train a segmentation network with dense supervision for better performance. Experiments on two public datasets demonstrate that our human-machine interactive tissue prototype learning method can achieve comparable segmentation performance as the fully-supervised baselines with less annotation burden and outperform other weakly-supervised methods. Codes will be available upon publication.
Learn2Reg: comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning
Dec 23, 2021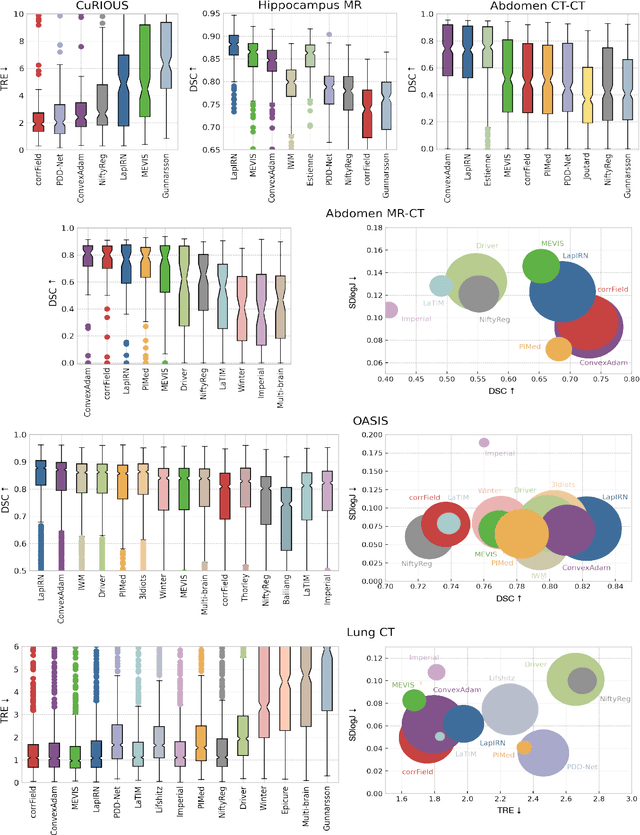
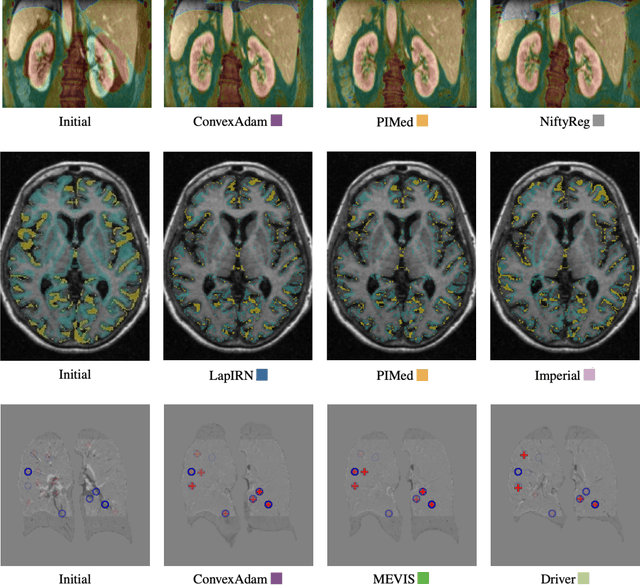
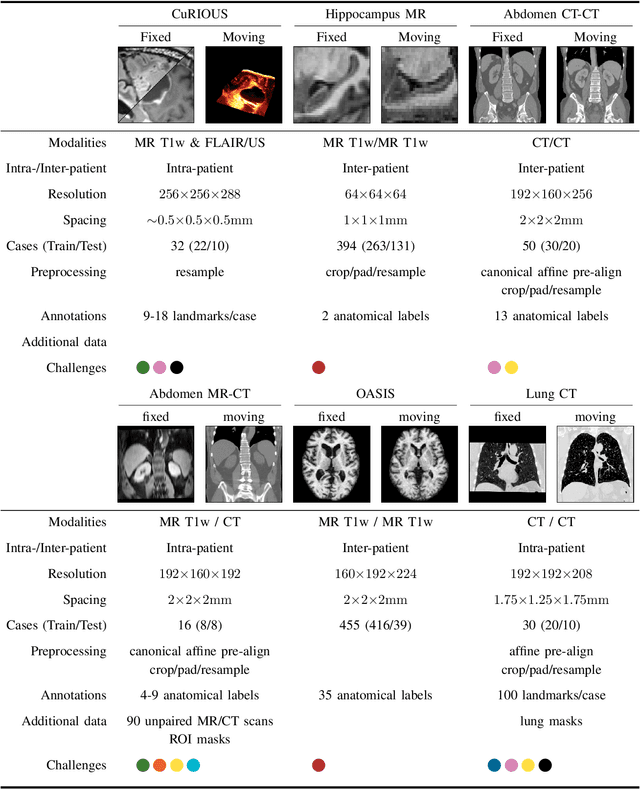
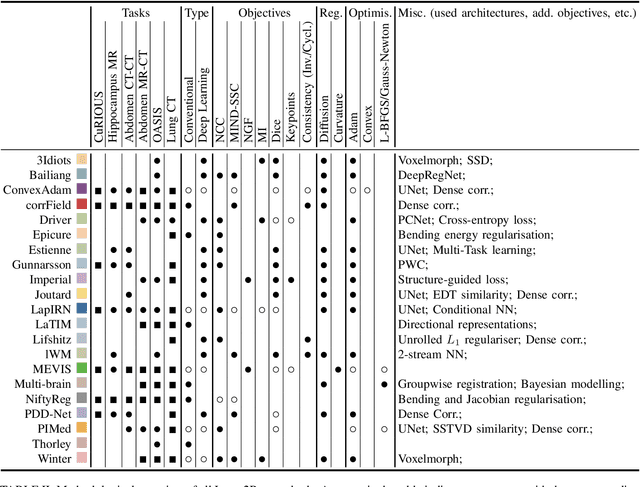
Image registration is a fundamental medical image analysis task, and a wide variety of approaches have been proposed. However, only a few studies have comprehensively compared medical image registration approaches on a wide range of clinically relevant tasks, in part because of the lack of availability of such diverse data. This limits the development of registration methods, the adoption of research advances into practice, and a fair benchmark across competing approaches. The Learn2Reg challenge addresses these limitations by providing a multi-task medical image registration benchmark for comprehensive characterisation of deformable registration algorithms. A continuous evaluation will be possible at https://learn2reg.grand-challenge.org. Learn2Reg covers a wide range of anatomies (brain, abdomen, and thorax), modalities (ultrasound, CT, MR), availability of annotations, as well as intra- and inter-patient registration evaluation. We established an easily accessible framework for training and validation of 3D registration methods, which enabled the compilation of results of over 65 individual method submissions from more than 20 unique teams. We used a complementary set of metrics, including robustness, accuracy, plausibility, and runtime, enabling unique insight into the current state-of-the-art of medical image registration. This paper describes datasets, tasks, evaluation methods and results of the challenge, and the results of further analysis of transferability to new datasets, the importance of label supervision, and resulting bias.