 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan2-Sum: Instruction Finetune Baichuan2-7B Model for Dialogue Summarization
Jan 31, 2024
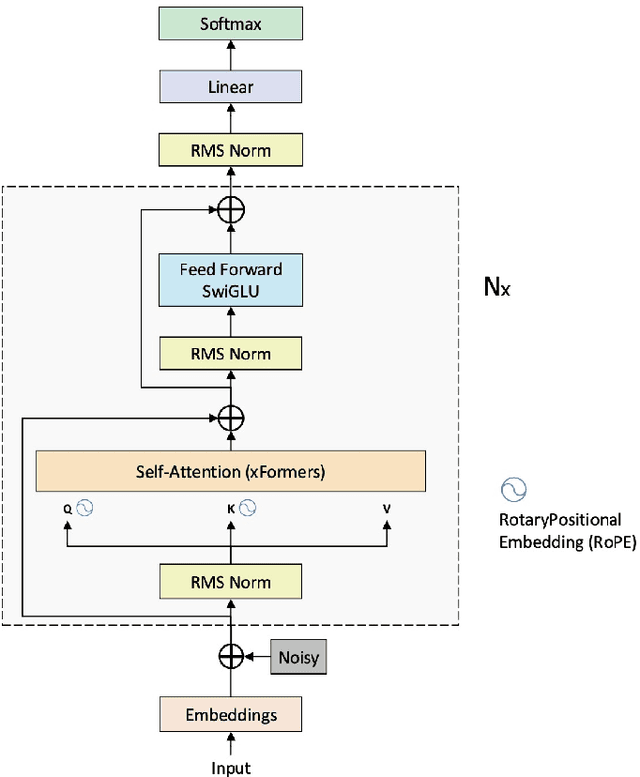
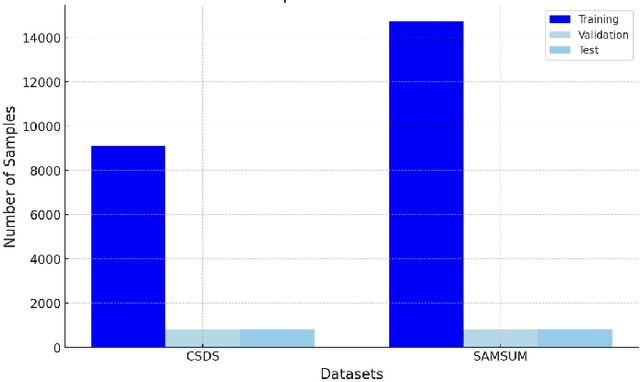
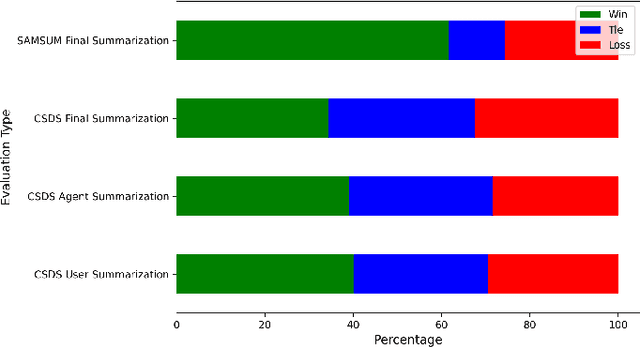
Large language models (LLMs) like Llama, Baichuan and Bloom models show remarkable ability with instruction fine-tuning in many natural language tasks. Nevertheless, for the dialogue summarization task, which aims to generate summaries for different roles in dialogue, most of the state-of-the-art methods conduct on small models (e.g Bart and Bert). Existing methods try to add task specified optimization on small models like adding global-local centrality score to models. In this paper, we propose an instruction fine-tuning model: Baichuan2-Sum, for role-oriented diaglouge summarization. By setting different instructions for different roles, the model can learn from the dialogue interactions and output the expected summaries. Furthermore, we applied NEFTune technique to add suitable noise during training to improve the results. The experiments demonstrate that the proposed model achieves the new state-of-the-art results on two public dialogue summarization datasets: CSDS and SAMSUM. We release our model and related codes to facilitate future studies on dialogue summarization task.
UniInst: Unique Representation for End-to-End Instance Segmentation
May 26, 2022

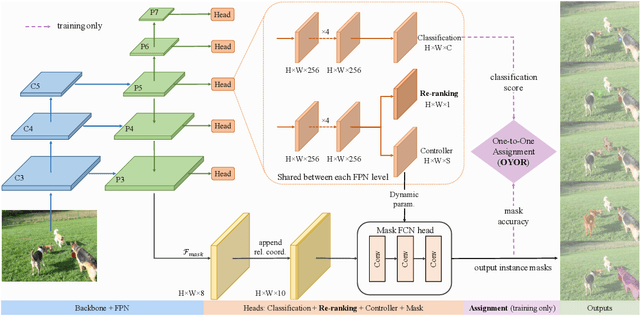

Existing instance segmentation methods have achieved impressive performance but still suffer from a common dilemma: redundant representations (e.g., multiple boxes, grids, and anchor points) are inferred for one instance, which leads to multiple duplicated predictions. Thus, mainstream methods usually rely on a hand-designed non-maximum suppression (NMS) post-processing step to select the optimal prediction result, which hinders end-to-end training. To address this issue, we propose a box-free and NMS-free end-to-end instance segmentation framework, termed UniInst, that yields only one unique representation for each instance. Specifically, we design an instance-aware one-to-one assignment scheme, namely Only Yield One Representation (OYOR), which dynamically assigns one unique representation to each instance according to the matching quality between predictions and ground truths. Then, a novel prediction re-ranking strategy is elegantly integrated into the framework to address the misalignment between the classification score and the mask quality, enabling the learned representation to be more discriminative. With these techniques, our UniInst, the first FCN-based end-to-end instance segmentation framework, achieves competitive performance, e.g., 39.0 mask AP using ResNet-50-FPN and 40.2 mask AP using ResNet-101-FPN, against mainstream methods on COCO test-dev. Moreover, the proposed instance-aware method is robust to occlusion scenes, outperforming common baselines by remarkable mask AP on the heavily-occluded OCHuman benchmark. Our codes will be available upon publication.