 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffST: Spatiotemporal-Aware Diffusion for Real-World Space-Time Video Super-Resolution
May 13, 2026Diffusion-based models have shown strong performance in video super-resolution (VSR) and video frame interpolation (VFI). However, their role in the coupled space-time video super-resolution (STVSR) setting remains limited. Existing diffusion-based STVSR approaches suffer from two issues: (1) low inference efficiency and (2) insufficient utilization of spatiotemporal information. These limitations impede deployment. To address these issues, we introduce DiffST, an efficient spatiotemporal-aware video diffusion framework for real-world STVSR. To improve efficiency, we adapt a pre-trained diffusion model for one-step sampling and process the entire video directly rather than operating on individual frames. Furthermore, to enhance spatiotemporal information utilization, we introduce cross-frame context aggregation (CFCA) and video representation guidance (VRG). The CFCA module aggregates information across multiple keyframes to produce intermediate frames. The VRG module extracts video-level global features to guide the diffusion process. Extensive experiments show that DiffST obtains leading results on real-world STVSR tasks. It also maintains high inference efficiency, running about 17$\times$ faster than previous diffusion-based STVSR methods. Code is available at: https://github.com/zhengchen1999/DiffST.
PRISM: Rethinking Scattered Atmosphere Reconstruction as a Unified Understanding and Generation Model for Real-world Dehazing
Apr 08, 2026Real-world image dehazing (RID) aims to remove haze induced degradation from real scenes. This task remains challenging due to non-uniform haze distribution, spatially varying illumination from multiple light sources, and the scarcity of paired real hazy-clean data. In PRISM, we propose Proximal Scattered Atmosphere Reconstruction (PSAR), a physically structured framework that jointly reconstructs the clear scene and scattering variables under the atmospheric scattering model, thereby improving reliability in complex regions and mixed-light conditions. To bridge the synthetic-to-real gap, we design an online non-uniform haze synthesis pipeline and a Selective Self-distillation Adaptation scheme for unpaired real-world scenarios, which enables the model to selectively learn from high-quality perceptual targets while leveraging its intrinsic scattering understanding to audit residual haze and guide self-refinement. Extensive experiments on real-world benchmarks demonstrate that PRISM achieves state-of-the-art performance on RID tasks.
Beyond Ground-Truth: Leveraging Image Quality Priors for Real-World Image Restoration
Mar 31, 2026Real-world image restoration aims to restore high-quality (HQ) images from degraded low-quality (LQ) inputs captured under uncontrolled conditions. Existing methods typically depend on ground-truth (GT) supervision, assuming that GT provides perfect reference quality. However, GT can still contain images with inconsistent perceptual fidelity, causing models to converge to the average quality level of the training data rather than achieving the highest perceptual quality attainable. To address these problems, we propose a novel framework, termed IQPIR, that introduces an Image Quality Prior (IQP)-extracted from pre-trained No-Reference Image Quality Assessment (NR-IQA) models-to guide the restoration process toward perceptually optimal outputs explicitly. Our approach synergistically integrates IQP with a learned codebook prior through three key mechanisms: (1) a quality-conditioned Transformer, where NR-IQA-derived scores serve as conditioning signals to steer the predicted representation toward maximal perceptual quality. This design provides a plug-and-play enhancement compatible with existing restoration architectures without structural modification; and (2) a dual-branch codebook structure, which disentangles common and HQ-specific features, ensuring a comprehensive representation of both generic structural information and quality-sensitive attributes; and (3) a discrete representation-based quality optimization strategy, which mitigates over-optimization effects commonly observed in continuous latent spaces. Extensive experiments on real-world image restoration demonstrate that our method not only surpasses cutting-edge methods but also serves as a generalizable quality-guided enhancement strategy for existing methods. The code is available.
Photon: Speedup Volume Understanding with Efficient Multimodal Large Language Models
Mar 26, 2026Multimodal large language models are promising for clinical visual question answering tasks, but scaling to 3D imaging is hindered by high computational costs. Prior methods often rely on 2D slices or fixed-length token compression, disrupting volumetric continuity and obscuring subtle findings. We present Photon, a framework that represents 3D medical volumes with token sequences of variable length. Photon introduces instruction-conditioned token scheduling and surrogate gradient propagation to adaptively reduce tokens during both training and inference, which lowers computational cost while mitigating the attention dilution caused by redundant tokens. It incorporates a custom backpropagation rule with gradient restoration to enable differentiable optimization despite discrete token drop. To stabilize token compression and ensure reliable use of visual evidence, Photon further applies regularization objectives that mitigate language-only bias and improve reliability. Experiments on diverse medical visual question answering tasks show that Photon achieves state-of-the-art accuracy while reducing resource usage and accelerating both training and inference.
QualiTeacher: Quality-Conditioned Pseudo-Labeling for Real-World Image Restoration
Mar 09, 2026Real-world image restoration (RWIR) is a highly challenging task due to the absence of clean ground-truth images. Many recent methods resort to pseudo-label (PL) supervision, often within a Mean-Teacher (MT) framework. However, these methods face a critical paradox: unconditionally trusting the often imperfect, low-quality PLs forces the student model to learn undesirable artifacts, while discarding them severely limits data diversity and impairs model generalization. In this paper, we propose QualiTeacher, a novel framework that transforms pseudo-label quality from a noisy liability into a conditional supervisory signal. Instead of filtering, QualiTeacher explicitly conditions the student model on the quality of the PLs, estimated by an ensemble of complementary non-reference image quality assessment (NR-IQA) models spanning low-level distortion and semantic-level assessment. This strategy teaches the student network to learn a quality-graded restoration manifold, enabling it to understand what constitutes different quality levels. Consequently, it can not only avoid mimicking artifacts from low-quality labels but also extrapolate to generate results of higher quality than the teacher itself. To ensure the robustness and accuracy of this quality-driven learning, we further enhance the process with a multi-augmentation scheme to diversify the PL quality spectrum, a score-based preference optimization strategy inspired by Direct Preference Optimization (DPO) to enforce a monotonically ordered quality separation, and a cropped consistency loss to prevent adversarial over-optimization (reward hacking) of the IQA models. Experiments on standard RWIR benchmarks demonstrate that QualiTeacher can serve as a plug-and-play strategy to improve the quality of the existing pseudo-labeling framework, establishing a new paradigm for learning from imperfect supervision. Code will be released.
PRIMA: Pre-training with Risk-integrated Image-Metadata Alignment for Medical Diagnosis via LLM
Feb 26, 2026Medical diagnosis requires the effective synthesis of visual manifestations and clinical metadata. However, existing methods often treat metadata as isolated tags, failing to exploit the rich semantic knowledge embedded in clinical descriptions. We propose PRIMA (Pre-training with Risk-integrated Image-Metadata Alignment), a framework that integrates domain-specific knowledge into multi-modal representation learning. We first curate an expert corpus of risk-disease correlations via Retrieval-Augmented Generation (RAG) to refine Clinical ModernBERT, embedding diagnostic priors into the text encoder. To bridge the modality gap, we introduce a dual-encoder pre-training strategy utilizing DINOv3 and our refined BERT, optimized by a suite of four complementary loss functions. These losses are designed to capture multi-granular semantic alignment and handle the ambiguity of clinical correlations through soft labels. Finally, we leverage Qwen-3 to fuse these aligned features for precise disease classification. Extensive experiments demonstrate that PRIMA effectively harmonizes pixel-level features with abstract clinical expertise, significantly outperforming other state-of-the-art methods. Notably, our framework achieves superior robustness without the need for massive data collection or exhaustive computational resources. Our code will be made public upon acceptance.
Refining Context-Entangled Content Segmentation via Curriculum Selection and Anti-Curriculum Promotion
Feb 01, 2026Biological learning proceeds from easy to difficult tasks, gradually reinforcing perception and robustness. Inspired by this principle, we address Context-Entangled Content Segmentation (CECS), a challenging setting where objects share intrinsic visual patterns with their surroundings, as in camouflaged object detection. Conventional segmentation networks predominantly rely on architectural enhancements but often ignore the learning dynamics that govern robustness under entangled data distributions. We introduce CurriSeg, a dual-phase learning framework that unifies curriculum and anti-curriculum principles to improve representation reliability. In the Curriculum Selection phase, CurriSeg dynamically selects training data based on the temporal statistics of sample losses, distinguishing hard-but-informative samples from noisy or ambiguous ones, thus enabling stable capability enhancement. In the Anti-Curriculum Promotion phase, we design Spectral-Blindness Fine-Tuning, which suppresses high-frequency components to enforce dependence on low-frequency structural and contextual cues and thus strengthens generalization. Extensive experiments demonstrate that CurriSeg achieves consistent improvements across diverse CECS benchmarks without adding parameters or increasing total training time, offering a principled view of how progression and challenge interplay to foster robust and context-aware segmentation. Code will be released.
Reversible Unfolding Network for Concealed Visual Perception with Generative Refinement
Aug 20, 2025Existing methods for concealed visual perception (CVP) often leverage reversible strategies to decrease uncertainty, yet these are typically confined to the mask domain, leaving the potential of the RGB domain underexplored. To address this, we propose a reversible unfolding network with generative refinement, termed RUN++. Specifically, RUN++ first formulates the CVP task as a mathematical optimization problem and unfolds the iterative solution into a multi-stage deep network. This approach provides a principled way to apply reversible modeling across both mask and RGB domains while leveraging a diffusion model to resolve the resulting uncertainty. Each stage of the network integrates three purpose-driven modules: a Concealed Object Region Extraction (CORE) module applies reversible modeling to the mask domain to identify core object regions; a Context-Aware Region Enhancement (CARE) module extends this principle to the RGB domain to foster better foreground-background separation; and a Finetuning Iteration via Noise-based Enhancement (FINE) module provides a final refinement. The FINE module introduces a targeted Bernoulli diffusion model that refines only the uncertain regions of the segmentation mask, harnessing the generative power of diffusion for fine-detail restoration without the prohibitive computational cost of a full-image process. This unique synergy, where the unfolding network provides a strong uncertainty prior for the diffusion model, allows RUN++ to efficiently direct its focus toward ambiguous areas, significantly mitigating false positives and negatives. Furthermore, we introduce a new paradigm for building robust CVP systems that remain effective under real-world degradations and extend this concept into a broader bi-level optimization framework.
Uncertainty-Masked Bernoulli Diffusion for Camouflaged Object Detection Refinement
Jun 12, 2025

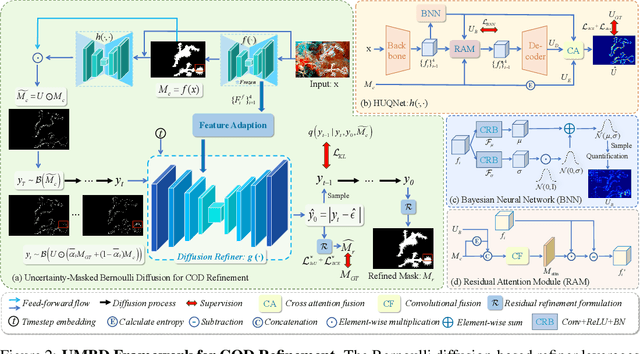

Camouflaged Object Detection (COD) presents inherent challenges due to the subtle visual differences between targets and their backgrounds. While existing methods have made notable progress, there remains significant potential for post-processing refinement that has yet to be fully explored. To address this limitation, we propose the Uncertainty-Masked Bernoulli Diffusion (UMBD) model, the first generative refinement framework specifically designed for COD. UMBD introduces an uncertainty-guided masking mechanism that selectively applies Bernoulli diffusion to residual regions with poor segmentation quality, enabling targeted refinement while preserving correctly segmented areas. To support this process, we design the Hybrid Uncertainty Quantification Network (HUQNet), which employs a multi-branch architecture and fuses uncertainty from multiple sources to improve estimation accuracy. This enables adaptive guidance during the generative sampling process. The proposed UMBD framework can be seamlessly integrated with a wide range of existing Encoder-Decoder-based COD models, combining their discriminative capabilities with the generative advantages of diffusion-based refinement. Extensive experiments across multiple COD benchmarks demonstrate consistent performance improvements, achieving average gains of 5.5% in MAE and 3.2% in weighted F-measure with only modest computational overhead. Code will be released.
Segment Concealed Objects with Incomplete Supervision
Jun 10, 2025Incompletely-Supervised Concealed Object Segmentation (ISCOS) involves segmenting objects that seamlessly blend into their surrounding environments, utilizing incompletely annotated data, such as weak and semi-annotations, for model training. This task remains highly challenging due to (1) the limited supervision provided by the incompletely annotated training data, and (2) the difficulty of distinguishing concealed objects from the background, which arises from the intrinsic similarities in concealed scenarios. In this paper, we introduce the first unified method for ISCOS to address these challenges. To tackle the issue of incomplete supervision, we propose a unified mean-teacher framework, SEE, that leverages the vision foundation model, ``\emph{Segment Anything Model (SAM)}'', to generate pseudo-labels using coarse masks produced by the teacher model as prompts. To mitigate the effect of low-quality segmentation masks, we introduce a series of strategies for pseudo-label generation, storage, and supervision. These strategies aim to produce informative pseudo-labels, store the best pseudo-labels generated, and select the most reliable components to guide the student model, thereby ensuring robust network training. Additionally, to tackle the issue of intrinsic similarity, we design a hybrid-granularity feature grouping module that groups features at different granularities and aggregates these results. By clustering similar features, this module promotes segmentation coherence, facilitating more complete segmentation for both single-object and multiple-object images. We validate the effectiveness of our approach across multiple ISCOS tasks, and experimental results demonstrate that our method achieves state-of-the-art performance. Furthermore, SEE can serve as a plug-and-play solution, enhancing the performance of existing models.
* IEEE TPAMI