 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-Language-Action Model for Adaptive Ultrasound-Guided Needle Insertion and Needle Tracking
Apr 22, 2026Ultrasound (US)-guided needle insertion is a critical yet challenging procedure due to dynamic imaging conditions and difficulties in needle visualization. Many methods have been proposed for automated needle insertion, but they often rely on hand-crafted pipelines with modular controllers, whose performance degrades in challenging cases. In this paper, a Vision-Language-Action (VLA) model is proposed for adaptive and automated US-guided needle insertion and tracking on a robotic ultrasound (RUS) system. This framework provides a unified approach to needle tracking and needle insertion control, enabling real-time, dynamically adaptive adjustment of insertion based on the obtained needle position and environment awareness. To achieve real-time and end-to-end tracking, a Cross-Depth Fusion (CDF) tracking head is proposed, integrating shallow positional and deep semantic features from the large-scale vision backbone. To adapt the pretrained vision backbone for tracking tasks, a Tracking-Conditioning (TraCon) register is introduced for parameter-efficient feature conditioning. After needle tracking, an uncertainty-aware control policy and an asynchronous VLA pipeline are presented for adaptive needle insertion control, ensuring timely decision-making for improved safety and outcomes. Extensive experiments on both needle tracking and insertion show that our method consistently outperforms state-of-the-art trackers and manual operation, achieving higher tracking accuracy, improved insertion success rates, and reduced procedure time, highlighting promising directions for RUS-based intelligent intervention.
MedVR: Annotation-Free Medical Visual Reasoning via Agentic Reinforcement Learning
Apr 09, 2026Medical Vision-Language Models (VLMs) hold immense promise for complex clinical tasks, but their reasoning capabilities are often constrained by text-only paradigms that fail to ground inferences in visual evidence. This limitation not only curtails performance on tasks requiring fine-grained visual analysis but also introduces risks of visual hallucination in safety-critical applications. Thus, we introduce MedVR, a novel reinforcement learning framework that enables annotation-free visual reasoning for medical VLMs. Its core innovation lies in two synergistic mechanisms: Entropy-guided Visual Regrounding (EVR) uses model uncertainty to direct exploration, while Consensus-based Credit Assignment (CCA) distills pseudo-supervision from rollout agreement. Without any human annotations for intermediate steps, MedVR achieves state-of-the-art performance on diverse public medical VQA benchmarks, significantly outperforming existing models. By learning to reason directly with visual evidence, MedVR promotes the robustness and transparency essential for accelerating the clinical deployment of medical AI.
PRISM: Rethinking Scattered Atmosphere Reconstruction as a Unified Understanding and Generation Model for Real-world Dehazing
Apr 08, 2026Real-world image dehazing (RID) aims to remove haze induced degradation from real scenes. This task remains challenging due to non-uniform haze distribution, spatially varying illumination from multiple light sources, and the scarcity of paired real hazy-clean data. In PRISM, we propose Proximal Scattered Atmosphere Reconstruction (PSAR), a physically structured framework that jointly reconstructs the clear scene and scattering variables under the atmospheric scattering model, thereby improving reliability in complex regions and mixed-light conditions. To bridge the synthetic-to-real gap, we design an online non-uniform haze synthesis pipeline and a Selective Self-distillation Adaptation scheme for unpaired real-world scenarios, which enables the model to selectively learn from high-quality perceptual targets while leveraging its intrinsic scattering understanding to audit residual haze and guide self-refinement. Extensive experiments on real-world benchmarks demonstrate that PRISM achieves state-of-the-art performance on RID tasks.
Beyond Ground-Truth: Leveraging Image Quality Priors for Real-World Image Restoration
Mar 31, 2026Real-world image restoration aims to restore high-quality (HQ) images from degraded low-quality (LQ) inputs captured under uncontrolled conditions. Existing methods typically depend on ground-truth (GT) supervision, assuming that GT provides perfect reference quality. However, GT can still contain images with inconsistent perceptual fidelity, causing models to converge to the average quality level of the training data rather than achieving the highest perceptual quality attainable. To address these problems, we propose a novel framework, termed IQPIR, that introduces an Image Quality Prior (IQP)-extracted from pre-trained No-Reference Image Quality Assessment (NR-IQA) models-to guide the restoration process toward perceptually optimal outputs explicitly. Our approach synergistically integrates IQP with a learned codebook prior through three key mechanisms: (1) a quality-conditioned Transformer, where NR-IQA-derived scores serve as conditioning signals to steer the predicted representation toward maximal perceptual quality. This design provides a plug-and-play enhancement compatible with existing restoration architectures without structural modification; and (2) a dual-branch codebook structure, which disentangles common and HQ-specific features, ensuring a comprehensive representation of both generic structural information and quality-sensitive attributes; and (3) a discrete representation-based quality optimization strategy, which mitigates over-optimization effects commonly observed in continuous latent spaces. Extensive experiments on real-world image restoration demonstrate that our method not only surpasses cutting-edge methods but also serves as a generalizable quality-guided enhancement strategy for existing methods. The code is available.
Photon: Speedup Volume Understanding with Efficient Multimodal Large Language Models
Mar 26, 2026Multimodal large language models are promising for clinical visual question answering tasks, but scaling to 3D imaging is hindered by high computational costs. Prior methods often rely on 2D slices or fixed-length token compression, disrupting volumetric continuity and obscuring subtle findings. We present Photon, a framework that represents 3D medical volumes with token sequences of variable length. Photon introduces instruction-conditioned token scheduling and surrogate gradient propagation to adaptively reduce tokens during both training and inference, which lowers computational cost while mitigating the attention dilution caused by redundant tokens. It incorporates a custom backpropagation rule with gradient restoration to enable differentiable optimization despite discrete token drop. To stabilize token compression and ensure reliable use of visual evidence, Photon further applies regularization objectives that mitigate language-only bias and improve reliability. Experiments on diverse medical visual question answering tasks show that Photon achieves state-of-the-art accuracy while reducing resource usage and accelerating both training and inference.
Taming Preference Mode Collapse via Directional Decoupling Alignment in Diffusion Reinforcement Learning
Dec 30, 2025Recent studies have demonstrated significant progress in aligning text-to-image diffusion models with human preference via Reinforcement Learning from Human Feedback. However, while existing methods achieve high scores on automated reward metrics, they often lead to Preference Mode Collapse (PMC)-a specific form of reward hacking where models converge on narrow, high-scoring outputs (e.g., images with monolithic styles or pervasive overexposure), severely degrading generative diversity. In this work, we introduce and quantify this phenomenon, proposing DivGenBench, a novel benchmark designed to measure the extent of PMC. We posit that this collapse is driven by over-optimization along the reward model's inherent biases. Building on this analysis, we propose Directional Decoupling Alignment (D$^2$-Align), a novel framework that mitigates PMC by directionally correcting the reward signal. Specifically, our method first learns a directional correction within the reward model's embedding space while keeping the model frozen. This correction is then applied to the reward signal during the optimization process, preventing the model from collapsing into specific modes and thereby maintaining diversity. Our comprehensive evaluation, combining qualitative analysis with quantitative metrics for both quality and diversity, reveals that D$^2$-Align achieves superior alignment with human preference.
Reversible Unfolding Network for Concealed Visual Perception with Generative Refinement
Aug 20, 2025Existing methods for concealed visual perception (CVP) often leverage reversible strategies to decrease uncertainty, yet these are typically confined to the mask domain, leaving the potential of the RGB domain underexplored. To address this, we propose a reversible unfolding network with generative refinement, termed RUN++. Specifically, RUN++ first formulates the CVP task as a mathematical optimization problem and unfolds the iterative solution into a multi-stage deep network. This approach provides a principled way to apply reversible modeling across both mask and RGB domains while leveraging a diffusion model to resolve the resulting uncertainty. Each stage of the network integrates three purpose-driven modules: a Concealed Object Region Extraction (CORE) module applies reversible modeling to the mask domain to identify core object regions; a Context-Aware Region Enhancement (CARE) module extends this principle to the RGB domain to foster better foreground-background separation; and a Finetuning Iteration via Noise-based Enhancement (FINE) module provides a final refinement. The FINE module introduces a targeted Bernoulli diffusion model that refines only the uncertain regions of the segmentation mask, harnessing the generative power of diffusion for fine-detail restoration without the prohibitive computational cost of a full-image process. This unique synergy, where the unfolding network provides a strong uncertainty prior for the diffusion model, allows RUN++ to efficiently direct its focus toward ambiguous areas, significantly mitigating false positives and negatives. Furthermore, we introduce a new paradigm for building robust CVP systems that remain effective under real-world degradations and extend this concept into a broader bi-level optimization framework.
Exploring Fourier Prior and Event Collaboration for Low-Light Image Enhancement
Aug 01, 2025The event camera, benefiting from its high dynamic range and low latency, provides performance gain for low-light image enhancement. Unlike frame-based cameras, it records intensity changes with extremely high temporal resolution, capturing sufficient structure information. Currently, existing event-based methods feed a frame and events directly into a single model without fully exploiting modality-specific advantages, which limits their performance. Therefore, by analyzing the role of each sensing modality, the enhancement pipeline is decoupled into two stages: visibility restoration and structure refinement. In the first stage, we design a visibility restoration network with amplitude-phase entanglement by rethinking the relationship between amplitude and phase components in Fourier space. In the second stage, a fusion strategy with dynamic alignment is proposed to mitigate the spatial mismatch caused by the temporal resolution discrepancy between two sensing modalities, aiming to refine the structure information of the image enhanced by the visibility restoration network. In addition, we utilize spatial-frequency interpolation to simulate negative samples with diverse illumination, noise and artifact degradations, thereby developing a contrastive loss that encourages the model to learn discriminative representations. Experiments demonstrate that the proposed method outperforms state-of-the-art models.
Uncertainty-Masked Bernoulli Diffusion for Camouflaged Object Detection Refinement
Jun 12, 2025

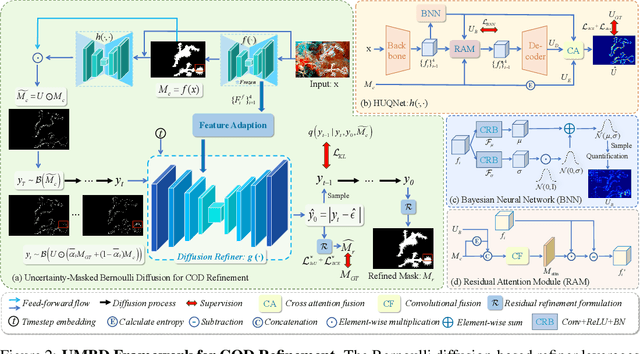

Camouflaged Object Detection (COD) presents inherent challenges due to the subtle visual differences between targets and their backgrounds. While existing methods have made notable progress, there remains significant potential for post-processing refinement that has yet to be fully explored. To address this limitation, we propose the Uncertainty-Masked Bernoulli Diffusion (UMBD) model, the first generative refinement framework specifically designed for COD. UMBD introduces an uncertainty-guided masking mechanism that selectively applies Bernoulli diffusion to residual regions with poor segmentation quality, enabling targeted refinement while preserving correctly segmented areas. To support this process, we design the Hybrid Uncertainty Quantification Network (HUQNet), which employs a multi-branch architecture and fuses uncertainty from multiple sources to improve estimation accuracy. This enables adaptive guidance during the generative sampling process. The proposed UMBD framework can be seamlessly integrated with a wide range of existing Encoder-Decoder-based COD models, combining their discriminative capabilities with the generative advantages of diffusion-based refinement. Extensive experiments across multiple COD benchmarks demonstrate consistent performance improvements, achieving average gains of 5.5% in MAE and 3.2% in weighted F-measure with only modest computational overhead. Code will be released.
Segment Concealed Objects with Incomplete Supervision
Jun 10, 2025Incompletely-Supervised Concealed Object Segmentation (ISCOS) involves segmenting objects that seamlessly blend into their surrounding environments, utilizing incompletely annotated data, such as weak and semi-annotations, for model training. This task remains highly challenging due to (1) the limited supervision provided by the incompletely annotated training data, and (2) the difficulty of distinguishing concealed objects from the background, which arises from the intrinsic similarities in concealed scenarios. In this paper, we introduce the first unified method for ISCOS to address these challenges. To tackle the issue of incomplete supervision, we propose a unified mean-teacher framework, SEE, that leverages the vision foundation model, ``\emph{Segment Anything Model (SAM)}'', to generate pseudo-labels using coarse masks produced by the teacher model as prompts. To mitigate the effect of low-quality segmentation masks, we introduce a series of strategies for pseudo-label generation, storage, and supervision. These strategies aim to produce informative pseudo-labels, store the best pseudo-labels generated, and select the most reliable components to guide the student model, thereby ensuring robust network training. Additionally, to tackle the issue of intrinsic similarity, we design a hybrid-granularity feature grouping module that groups features at different granularities and aggregates these results. By clustering similar features, this module promotes segmentation coherence, facilitating more complete segmentation for both single-object and multiple-object images. We validate the effectiveness of our approach across multiple ISCOS tasks, and experimental results demonstrate that our method achieves state-of-the-art performance. Furthermore, SEE can serve as a plug-and-play solution, enhancing the performance of existing models.
* IEEE TPAMI