 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Preference Mode Collapse via Directional Decoupling Alignment in Diffusion Reinforcement Learning
Dec 30, 2025Recent studies have demonstrated significant progress in aligning text-to-image diffusion models with human preference via Reinforcement Learning from Human Feedback. However, while existing methods achieve high scores on automated reward metrics, they often lead to Preference Mode Collapse (PMC)-a specific form of reward hacking where models converge on narrow, high-scoring outputs (e.g., images with monolithic styles or pervasive overexposure), severely degrading generative diversity. In this work, we introduce and quantify this phenomenon, proposing DivGenBench, a novel benchmark designed to measure the extent of PMC. We posit that this collapse is driven by over-optimization along the reward model's inherent biases. Building on this analysis, we propose Directional Decoupling Alignment (D$^2$-Align), a novel framework that mitigates PMC by directionally correcting the reward signal. Specifically, our method first learns a directional correction within the reward model's embedding space while keeping the model frozen. This correction is then applied to the reward signal during the optimization process, preventing the model from collapsing into specific modes and thereby maintaining diversity. Our comprehensive evaluation, combining qualitative analysis with quantitative metrics for both quality and diversity, reveals that D$^2$-Align achieves superior alignment with human preference.
Uncertainty-Masked Bernoulli Diffusion for Camouflaged Object Detection Refinement
Jun 12, 2025

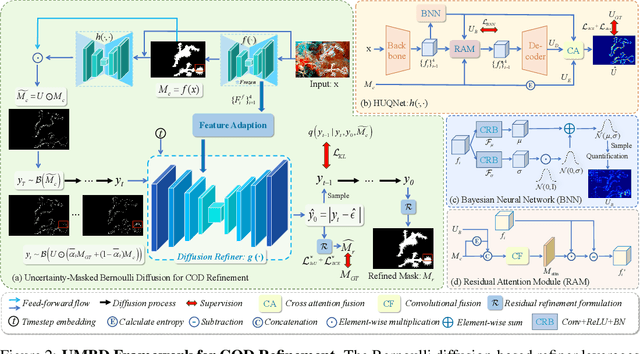

Camouflaged Object Detection (COD) presents inherent challenges due to the subtle visual differences between targets and their backgrounds. While existing methods have made notable progress, there remains significant potential for post-processing refinement that has yet to be fully explored. To address this limitation, we propose the Uncertainty-Masked Bernoulli Diffusion (UMBD) model, the first generative refinement framework specifically designed for COD. UMBD introduces an uncertainty-guided masking mechanism that selectively applies Bernoulli diffusion to residual regions with poor segmentation quality, enabling targeted refinement while preserving correctly segmented areas. To support this process, we design the Hybrid Uncertainty Quantification Network (HUQNet), which employs a multi-branch architecture and fuses uncertainty from multiple sources to improve estimation accuracy. This enables adaptive guidance during the generative sampling process. The proposed UMBD framework can be seamlessly integrated with a wide range of existing Encoder-Decoder-based COD models, combining their discriminative capabilities with the generative advantages of diffusion-based refinement. Extensive experiments across multiple COD benchmarks demonstrate consistent performance improvements, achieving average gains of 5.5% in MAE and 3.2% in weighted F-measure with only modest computational overhead. Code will be released.
A Survey of Camouflaged Object Detection and Beyond
Aug 26, 2024Camouflaged Object Detection (COD) refers to the task of identifying and segmenting objects that blend seamlessly into their surroundings, posing a significant challenge for computer vision systems. In recent years, COD has garnered widespread attention due to its potential applications in surveillance, wildlife conservation, autonomous systems, and more. While several surveys on COD exist, they often have limitations in terms of the number and scope of papers covered, particularly regarding the rapid advancements made in the field since mid-2023. To address this void, we present the most comprehensive review of COD to date, encompassing both theoretical frameworks and practical contributions to the field. This paper explores various COD methods across four domains, including both image-level and video-level solutions, from the perspectives of traditional and deep learning approaches. We thoroughly investigate the correlations between COD and other camouflaged scenario methods, thereby laying the theoretical foundation for subsequent analyses. Beyond object-level detection, we also summarize extended methods for instance-level tasks, including camouflaged instance segmentation, counting, and ranking. Additionally, we provide an overview of commonly used benchmarks and evaluation metrics in COD tasks, conducting a comprehensive evaluation of deep learning-based techniques in both image and video domains, considering both qualitative and quantitative performance. Finally, we discuss the limitations of current COD models and propose 9 promising directions for future research, focusing on addressing inherent challenges and exploring novel, meaningful technologies. For those interested, a curated list of COD-related techniques, datasets, and additional resources can be found at https://github.com/ChunmingHe/awesome-concealed-object-segmentation
TOD3Cap: Towards 3D Dense Captioning in Outdoor Scenes
Mar 28, 2024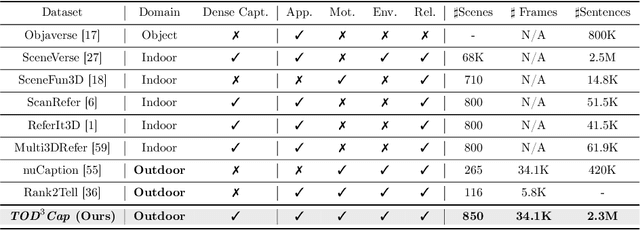
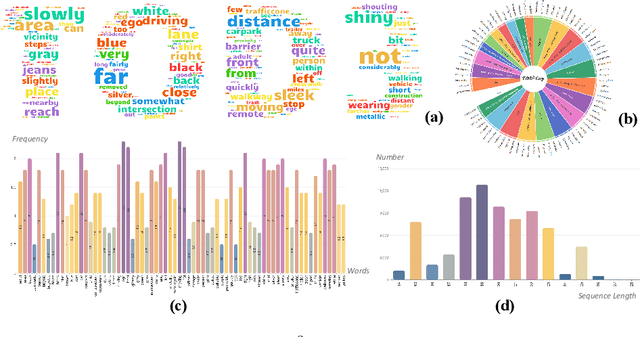

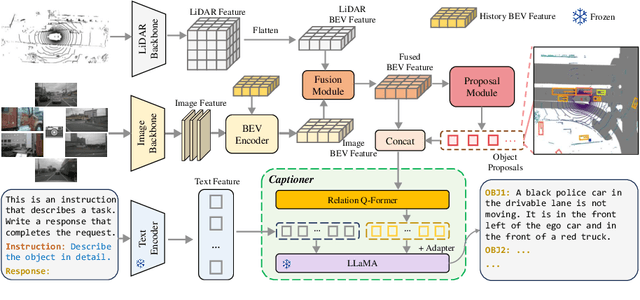
3D dense captioning stands as a cornerstone in achieving a comprehensive understanding of 3D scenes through natural language. It has recently witnessed remarkable achievements, particularly in indoor settings. However, the exploration of 3D dense captioning in outdoor scenes is hindered by two major challenges: 1) the \textbf{domain gap} between indoor and outdoor scenes, such as dynamics and sparse visual inputs, makes it difficult to directly adapt existing indoor methods; 2) the \textbf{lack of data} with comprehensive box-caption pair annotations specifically tailored for outdoor scenes. To this end, we introduce the new task of outdoor 3D dense captioning. As input, we assume a LiDAR point cloud and a set of RGB images captured by the panoramic camera rig. The expected output is a set of object boxes with captions. To tackle this task, we propose the TOD3Cap network, which leverages the BEV representation to generate object box proposals and integrates Relation Q-Former with LLaMA-Adapter to generate rich captions for these objects. We also introduce the TOD3Cap dataset, the largest one to our knowledge for 3D dense captioning in outdoor scenes, which contains 2.3M descriptions of 64.3K outdoor objects from 850 scenes. Notably, our TOD3Cap network can effectively localize and caption 3D objects in outdoor scenes, which outperforms baseline methods by a significant margin (+9.6 CiDEr@0.5IoU). Code, data, and models are publicly available at https://github.com/jxbbb/TOD3Cap.