 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Masked Bernoulli Diffusion for Camouflaged Object Detection Refinement
Jun 12, 2025

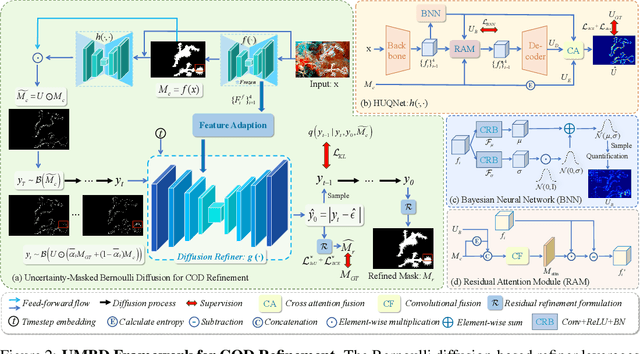

Camouflaged Object Detection (COD) presents inherent challenges due to the subtle visual differences between targets and their backgrounds. While existing methods have made notable progress, there remains significant potential for post-processing refinement that has yet to be fully explored. To address this limitation, we propose the Uncertainty-Masked Bernoulli Diffusion (UMBD) model, the first generative refinement framework specifically designed for COD. UMBD introduces an uncertainty-guided masking mechanism that selectively applies Bernoulli diffusion to residual regions with poor segmentation quality, enabling targeted refinement while preserving correctly segmented areas. To support this process, we design the Hybrid Uncertainty Quantification Network (HUQNet), which employs a multi-branch architecture and fuses uncertainty from multiple sources to improve estimation accuracy. This enables adaptive guidance during the generative sampling process. The proposed UMBD framework can be seamlessly integrated with a wide range of existing Encoder-Decoder-based COD models, combining their discriminative capabilities with the generative advantages of diffusion-based refinement. Extensive experiments across multiple COD benchmarks demonstrate consistent performance improvements, achieving average gains of 5.5% in MAE and 3.2% in weighted F-measure with only modest computational overhead. Code will be released.
Integrating Extra Modality Helps Segmentor Find Camouflaged Objects Well
Feb 20, 2025Camouflaged Object Segmentation (COS) remains a challenging problem due to the subtle visual differences between camouflaged objects and backgrounds. Owing to the exceedingly limited visual cues available from visible spectrum, previous RGB single-modality approaches often struggle to achieve satisfactory results, prompting the exploration of multimodal data to enhance detection accuracy. In this work, we present UniCOS, a novel framework that effectively leverages diverse data modalities to improve segmentation performance. UniCOS comprises two key components: a multimodal segmentor, UniSEG, and a cross-modal knowledge learning module, UniLearner. UniSEG employs a state space fusion mechanism to integrate cross-modal features within a unified state space, enhancing contextual understanding and improving robustness to integration of heterogeneous data. Additionally, it includes a fusion-feedback mechanism that facilitate feature extraction. UniLearner exploits multimodal data unrelated to the COS task to improve the segmentation ability of the COS models by generating pseudo-modal content and cross-modal semantic associations. Extensive experiments demonstrate that UniSEG outperforms existing Multimodal COS (MCOS) segmentors, regardless of whether real or pseudo-multimodal COS data is available. Moreover, in scenarios where multimodal COS data is unavailable but multimodal non-COS data is accessible, UniLearner effectively exploits these data to enhance segmentation performance. Our code will be made publicly available on \href{https://github.com/cnyvfang/UniCOS}{GitHub}.
A Survey of Camouflaged Object Detection and Beyond
Aug 26, 2024Camouflaged Object Detection (COD) refers to the task of identifying and segmenting objects that blend seamlessly into their surroundings, posing a significant challenge for computer vision systems. In recent years, COD has garnered widespread attention due to its potential applications in surveillance, wildlife conservation, autonomous systems, and more. While several surveys on COD exist, they often have limitations in terms of the number and scope of papers covered, particularly regarding the rapid advancements made in the field since mid-2023. To address this void, we present the most comprehensive review of COD to date, encompassing both theoretical frameworks and practical contributions to the field. This paper explores various COD methods across four domains, including both image-level and video-level solutions, from the perspectives of traditional and deep learning approaches. We thoroughly investigate the correlations between COD and other camouflaged scenario methods, thereby laying the theoretical foundation for subsequent analyses. Beyond object-level detection, we also summarize extended methods for instance-level tasks, including camouflaged instance segmentation, counting, and ranking. Additionally, we provide an overview of commonly used benchmarks and evaluation metrics in COD tasks, conducting a comprehensive evaluation of deep learning-based techniques in both image and video domains, considering both qualitative and quantitative performance. Finally, we discuss the limitations of current COD models and propose 9 promising directions for future research, focusing on addressing inherent challenges and exploring novel, meaningful technologies. For those interested, a curated list of COD-related techniques, datasets, and additional resources can be found at https://github.com/ChunmingHe/awesome-concealed-object-segmentation
Diffusion Models in Low-Level Vision: A Survey
Jun 17, 2024


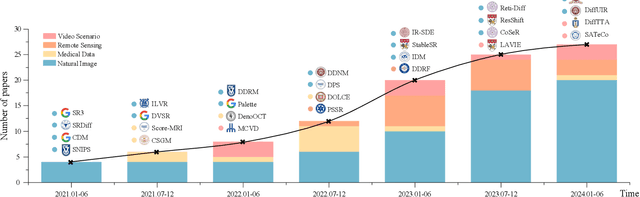
Deep generative models have garnered significant attention in low-level vision tasks due to their generative capabilities. Among them, diffusion model-based solutions, characterized by a forward diffusion process and a reverse denoising process, have emerged as widely acclaimed for their ability to produce samples of superior quality and diversity. This ensures the generation of visually compelling results with intricate texture information. Despite their remarkable success, a noticeable gap exists in a comprehensive survey that amalgamates these pioneering diffusion model-based works and organizes the corresponding threads. This paper proposes the comprehensive review of diffusion model-based techniques. We present three generic diffusion modeling frameworks and explore their correlations with other deep generative models, establishing the theoretical foundation. Following this, we introduce a multi-perspective categorization of diffusion models, considering both the underlying framework and the target task. Additionally, we summarize extended diffusion models applied in other tasks, including medical, remote sensing, and video scenarios. Moreover, we provide an overview of commonly used benchmarks and evaluation metrics. We conduct a thorough evaluation, encompassing both performance and efficiency, of diffusion model-based techniques in three prominent tasks. Finally, we elucidate the limitations of current diffusion models and propose seven intriguing directions for future research. This comprehensive examination aims to facilitate a profound understanding of the landscape surrounding denoising diffusion models in the context of low-level vision tasks. A curated list of diffusion model-based techniques in over 20 low-level vision tasks can be found at https://github.com/ChunmingHe/awesome-diffusion-models-in-low-level-vision.