 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Context-Entangled Content Segmentation via Curriculum Selection and Anti-Curriculum Promotion
Feb 01, 2026Biological learning proceeds from easy to difficult tasks, gradually reinforcing perception and robustness. Inspired by this principle, we address Context-Entangled Content Segmentation (CECS), a challenging setting where objects share intrinsic visual patterns with their surroundings, as in camouflaged object detection. Conventional segmentation networks predominantly rely on architectural enhancements but often ignore the learning dynamics that govern robustness under entangled data distributions. We introduce CurriSeg, a dual-phase learning framework that unifies curriculum and anti-curriculum principles to improve representation reliability. In the Curriculum Selection phase, CurriSeg dynamically selects training data based on the temporal statistics of sample losses, distinguishing hard-but-informative samples from noisy or ambiguous ones, thus enabling stable capability enhancement. In the Anti-Curriculum Promotion phase, we design Spectral-Blindness Fine-Tuning, which suppresses high-frequency components to enforce dependence on low-frequency structural and contextual cues and thus strengthens generalization. Extensive experiments demonstrate that CurriSeg achieves consistent improvements across diverse CECS benchmarks without adding parameters or increasing total training time, offering a principled view of how progression and challenge interplay to foster robust and context-aware segmentation. Code will be released.
Reversible Unfolding Network for Concealed Visual Perception with Generative Refinement
Aug 20, 2025Existing methods for concealed visual perception (CVP) often leverage reversible strategies to decrease uncertainty, yet these are typically confined to the mask domain, leaving the potential of the RGB domain underexplored. To address this, we propose a reversible unfolding network with generative refinement, termed RUN++. Specifically, RUN++ first formulates the CVP task as a mathematical optimization problem and unfolds the iterative solution into a multi-stage deep network. This approach provides a principled way to apply reversible modeling across both mask and RGB domains while leveraging a diffusion model to resolve the resulting uncertainty. Each stage of the network integrates three purpose-driven modules: a Concealed Object Region Extraction (CORE) module applies reversible modeling to the mask domain to identify core object regions; a Context-Aware Region Enhancement (CARE) module extends this principle to the RGB domain to foster better foreground-background separation; and a Finetuning Iteration via Noise-based Enhancement (FINE) module provides a final refinement. The FINE module introduces a targeted Bernoulli diffusion model that refines only the uncertain regions of the segmentation mask, harnessing the generative power of diffusion for fine-detail restoration without the prohibitive computational cost of a full-image process. This unique synergy, where the unfolding network provides a strong uncertainty prior for the diffusion model, allows RUN++ to efficiently direct its focus toward ambiguous areas, significantly mitigating false positives and negatives. Furthermore, we introduce a new paradigm for building robust CVP systems that remain effective under real-world degradations and extend this concept into a broader bi-level optimization framework.
Uncertainty-Masked Bernoulli Diffusion for Camouflaged Object Detection Refinement
Jun 12, 2025

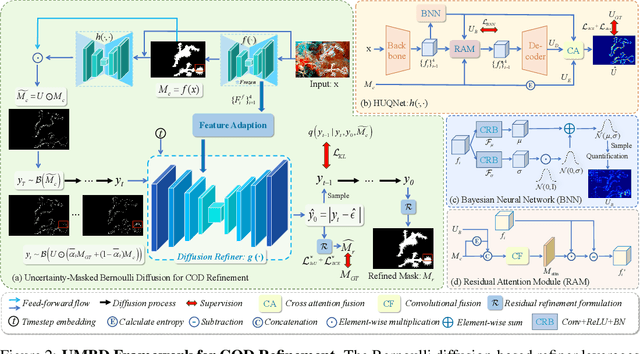

Camouflaged Object Detection (COD) presents inherent challenges due to the subtle visual differences between targets and their backgrounds. While existing methods have made notable progress, there remains significant potential for post-processing refinement that has yet to be fully explored. To address this limitation, we propose the Uncertainty-Masked Bernoulli Diffusion (UMBD) model, the first generative refinement framework specifically designed for COD. UMBD introduces an uncertainty-guided masking mechanism that selectively applies Bernoulli diffusion to residual regions with poor segmentation quality, enabling targeted refinement while preserving correctly segmented areas. To support this process, we design the Hybrid Uncertainty Quantification Network (HUQNet), which employs a multi-branch architecture and fuses uncertainty from multiple sources to improve estimation accuracy. This enables adaptive guidance during the generative sampling process. The proposed UMBD framework can be seamlessly integrated with a wide range of existing Encoder-Decoder-based COD models, combining their discriminative capabilities with the generative advantages of diffusion-based refinement. Extensive experiments across multiple COD benchmarks demonstrate consistent performance improvements, achieving average gains of 5.5% in MAE and 3.2% in weighted F-measure with only modest computational overhead. Code will be released.
UnfoldIR: Rethinking Deep Unfolding Network in Illumination Degradation Image Restoration
May 10, 2025Deep unfolding networks (DUNs) are widely employed in illumination degradation image restoration (IDIR) to merge the interpretability of model-based approaches with the generalization of learning-based methods. However, the performance of DUN-based methods remains considerably inferior to that of state-of-the-art IDIR solvers. Our investigation indicates that this limitation does not stem from structural shortcomings of DUNs but rather from the limited exploration of the unfolding structure, particularly for (1) constructing task-specific restoration models, (2) integrating advanced network architectures, and (3) designing DUN-specific loss functions. To address these issues, we propose a novel DUN-based method, UnfoldIR, for IDIR tasks. UnfoldIR first introduces a new IDIR model with dedicated regularization terms for smoothing illumination and enhancing texture. We unfold the iterative optimized solution of this model into a multistage network, with each stage comprising a reflectance-assisted illumination correction (RAIC) module and an illumination-guided reflectance enhancement (IGRE) module. RAIC employs a visual state space (VSS) to extract non-local features, enforcing illumination smoothness, while IGRE introduces a frequency-aware VSS to globally align similar textures, enabling mildly degraded regions to guide the enhancement of details in more severely degraded areas. This suppresses noise while enhancing details. Furthermore, given the multistage structure, we propose an inter-stage information consistent loss to maintain network stability in the final stages. This loss contributes to structural preservation and sustains the model's performance even in unsupervised settings. Experiments verify our effectiveness across 5 IDIR tasks and 3 downstream problems.
RUN: Reversible Unfolding Network for Concealed Object Segmentation
Jan 30, 2025



Existing concealed object segmentation (COS) methods frequently utilize reversible strategies to address uncertain regions. However, these approaches are typically restricted to the mask domain, leaving the potential of the RGB domain underexplored. To address this, we propose the Reversible Unfolding Network (RUN), which applies reversible strategies across both mask and RGB domains through a theoretically grounded framework, enabling accurate segmentation. RUN first formulates a novel COS model by incorporating an extra residual sparsity constraint to minimize segmentation uncertainties. The iterative optimization steps of the proposed model are then unfolded into a multistage network, with each step corresponding to a stage. Each stage of RUN consists of two reversible modules: the Segmentation-Oriented Foreground Separation (SOFS) module and the Reconstruction-Oriented Background Extraction (ROBE) module. SOFS applies the reversible strategy at the mask level and introduces Reversible State Space to capture non-local information. ROBE extends this to the RGB domain, employing a reconstruction network to address conflicting foreground and background regions identified as distortion-prone areas, which arise from their separate estimation by independent modules. As the stages progress, RUN gradually facilitates reversible modeling of foreground and background in both the mask and RGB domains, directing the network's attention to uncertain regions and mitigating false-positive and false-negative results. Extensive experiments demonstrate the superior performance of RUN and highlight the potential of unfolding-based frameworks for COS and other high-level vision tasks. We will release the code and models.
A Survey of Camouflaged Object Detection and Beyond
Aug 26, 2024Camouflaged Object Detection (COD) refers to the task of identifying and segmenting objects that blend seamlessly into their surroundings, posing a significant challenge for computer vision systems. In recent years, COD has garnered widespread attention due to its potential applications in surveillance, wildlife conservation, autonomous systems, and more. While several surveys on COD exist, they often have limitations in terms of the number and scope of papers covered, particularly regarding the rapid advancements made in the field since mid-2023. To address this void, we present the most comprehensive review of COD to date, encompassing both theoretical frameworks and practical contributions to the field. This paper explores various COD methods across four domains, including both image-level and video-level solutions, from the perspectives of traditional and deep learning approaches. We thoroughly investigate the correlations between COD and other camouflaged scenario methods, thereby laying the theoretical foundation for subsequent analyses. Beyond object-level detection, we also summarize extended methods for instance-level tasks, including camouflaged instance segmentation, counting, and ranking. Additionally, we provide an overview of commonly used benchmarks and evaluation metrics in COD tasks, conducting a comprehensive evaluation of deep learning-based techniques in both image and video domains, considering both qualitative and quantitative performance. Finally, we discuss the limitations of current COD models and propose 9 promising directions for future research, focusing on addressing inherent challenges and exploring novel, meaningful technologies. For those interested, a curated list of COD-related techniques, datasets, and additional resources can be found at https://github.com/ChunmingHe/awesome-concealed-object-segmentation
Diffusion Models in Low-Level Vision: A Survey
Jun 17, 2024


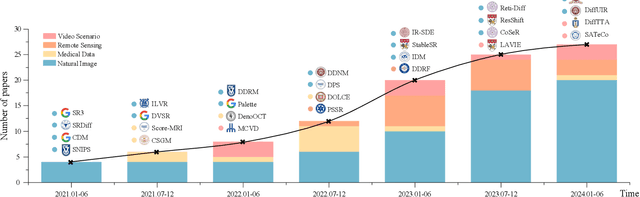
Deep generative models have garnered significant attention in low-level vision tasks due to their generative capabilities. Among them, diffusion model-based solutions, characterized by a forward diffusion process and a reverse denoising process, have emerged as widely acclaimed for their ability to produce samples of superior quality and diversity. This ensures the generation of visually compelling results with intricate texture information. Despite their remarkable success, a noticeable gap exists in a comprehensive survey that amalgamates these pioneering diffusion model-based works and organizes the corresponding threads. This paper proposes the comprehensive review of diffusion model-based techniques. We present three generic diffusion modeling frameworks and explore their correlations with other deep generative models, establishing the theoretical foundation. Following this, we introduce a multi-perspective categorization of diffusion models, considering both the underlying framework and the target task. Additionally, we summarize extended diffusion models applied in other tasks, including medical, remote sensing, and video scenarios. Moreover, we provide an overview of commonly used benchmarks and evaluation metrics. We conduct a thorough evaluation, encompassing both performance and efficiency, of diffusion model-based techniques in three prominent tasks. Finally, we elucidate the limitations of current diffusion models and propose seven intriguing directions for future research. This comprehensive examination aims to facilitate a profound understanding of the landscape surrounding denoising diffusion models in the context of low-level vision tasks. A curated list of diffusion model-based techniques in over 20 low-level vision tasks can be found at https://github.com/ChunmingHe/awesome-diffusion-models-in-low-level-vision.
Real-world Image Dehazing with Coherence-based Label Generator and Cooperative Unfolding Network
Jun 12, 2024Real-world Image Dehazing (RID) aims to alleviate haze-induced degradation in real-world settings. This task remains challenging due to the complexities in accurately modeling real haze distributions and the scarcity of paired real-world data. To address these challenges, we first introduce a cooperative unfolding network that jointly models atmospheric scattering and image scenes, effectively integrating physical knowledge into deep networks to restore haze-contaminated details. Additionally, we propose the first RID-oriented iterative mean-teacher framework, termed the Coherence-based Label Generator, to generate high-quality pseudo labels for network training. Specifically, we provide an optimal label pool to store the best pseudo-labels during network training, leveraging both global and local coherence to select high-quality candidates and assign weights to prioritize haze-free regions. We verify the effectiveness of our method, with experiments demonstrating that it achieves state-of-the-art performance on RID tasks. Code will be available at \url{https://github.com/cnyvfang/CORUN-Colabator}.
Concealed Object Segmentation with Hierarchical Coherence Modeling
Jan 22, 2024



Concealed object segmentation (COS) is a challenging task that involves localizing and segmenting those concealed objects that are visually blended with their surrounding environments. Despite achieving remarkable success, existing COS segmenters still struggle to achieve complete segmentation results in extremely concealed scenarios. In this paper, we propose a Hierarchical Coherence Modeling (HCM) segmenter for COS, aiming to address this incomplete segmentation limitation. In specific, HCM promotes feature coherence by leveraging the intra-stage coherence and cross-stage coherence modules, exploring feature correlations at both the single-stage and contextual levels. Additionally, we introduce the reversible re-calibration decoder to detect previously undetected parts in low-confidence regions, resulting in further enhancing segmentation performance. Extensive experiments conducted on three COS tasks, including camouflaged object detection, polyp image segmentation, and transparent object detection, demonstrate the promising results achieved by the proposed HCM segmenter.
Reti-Diff: Illumination Degradation Image Restoration with Retinex-based Latent Diffusion Model
Nov 20, 2023Illumination degradation image restoration (IDIR) techniques aim to improve the visibility of degraded images and mitigate the adverse effects of deteriorated illumination. Among these algorithms, diffusion model (DM)-based methods have shown promising performance but are often burdened by heavy computational demands and pixel misalignment issues when predicting the image-level distribution. To tackle these problems, we propose to leverage DM within a compact latent space to generate concise guidance priors and introduce a novel solution called Reti-Diff for the IDIR task. Reti-Diff comprises two key components: the Retinex-based latent DM (RLDM) and the Retinex-guided transformer (RGformer). To ensure detailed reconstruction and illumination correction, RLDM is empowered to acquire Retinex knowledge and extract reflectance and illumination priors. These priors are subsequently utilized by RGformer to guide the decomposition of image features into their respective reflectance and illumination components. Following this, RGformer further enhances and consolidates the decomposed features, resulting in the production of refined images with consistent content and robustness to handle complex degradation scenarios. Extensive experiments show that Reti-Diff outperforms existing methods on three IDIR tasks, as well as downstream applications. Code will be available at \url{https://github.com/ChunmingHe/Reti-Diff}.