 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditHF-1M: A Million-Scale Rich Human Preference Feedback for Image Editing
Mar 16, 2026Recent text-guided image editing (TIE) models have achieved remarkable progress, while many edited images still suffer from issues such as artifacts, unexpected editings, unaesthetic contents. Although some benchmarks and methods have been proposed for evaluating edited images, scalable evaluation models are still lacking, which limits the development of human feedback reward models for image editing. To address the challenges, we first introduce \textbf{EditHF-1M}, a million-scale image editing dataset with over 29M human preference pairs and 148K human mean opinion ratings, both evaluated from three dimensions, \textit{i.e.}, visual quality, instruction alignment, and attribute preservation. Based on EditHF-1M, we propose \textbf{EditHF}, a multimodal large language model (MLLM) based evaluation model, to provide human-aligned feedback from image editing. Finally, we introduce \textbf{EditHF-Reward}, which utilizes EditHF as the reward signal to optimize the text-guided image editing models through reinforcement learning. Extensive experiments show that EditHF achieves superior alignment with human preferences and demonstrates strong generalization on other datasets. Furthermore, we fine-tune the Qwen-Image-Edit using EditHF-Reward, achieving significant performance improvements, which demonstrates the ability of EditHF to serve as a reward model to scale-up the image editing. Both the dataset and code will be released in our GitHub repository: https://github.com/IntMeGroup/EditHF.
Beyond Scaling: Assessing Strategic Reasoning and Rapid Decision-Making Capability of LLMs in Zero-sum Environments
Mar 10, 2026Large Language Models (LLMs) have achieved strong performance on static reasoning benchmarks, yet their effectiveness as interactive agents operating in adversarial, time-sensitive environments remains poorly understood. Existing evaluations largely treat reasoning as a single-shot capability, overlooking the challenges of opponent-aware decision-making, temporal constraints, and execution under pressure. This paper introduces Strategic Tactical Agent Reasoning (STAR) Benchmark, a multi-agent evaluation framework that assesses LLMs through 1v1 zero-sum competitive interactions, framing reasoning as an iterative, adaptive decision-making process. STAR supports both turn-based and real-time settings, enabling controlled analysis of long-horizon strategic planning and fast-paced tactical execution within a unified environment. Built on a modular architecture with a standardized API and fully implemented execution engine, STAR facilitates reproducible evaluation and flexible task customization. To move beyond binary win-loss outcomes, we introduce a Strategic Evaluation Suite that assesses not only competitive success but also the quality of strategic behavior, such as execution efficiency and outcome stability. Extensive pairwise evaluations reveal a pronounced strategy-execution gap: while reasoning-intensive models dominate turn-based settings, their inference latency often leads to inferior performance in real-time scenarios, where faster instruction-tuned models prevail. These results show that strategic intelligence in interactive environments depends not only on reasoning depth, but also on the ability to translate plans into timely actions, positioning STAR as a principled benchmark for studying this trade-off in competitive, dynamic settings.
Multi-Modal Prompt Learning on Blind Image Quality Assessment
Apr 23, 2024



Image Quality Assessment (IQA) models benefit significantly from semantic information, which allows them to treat different types of objects distinctly. Currently, leveraging semantic information to enhance IQA is a crucial research direction. Traditional methods, hindered by a lack of sufficiently annotated data, have employed the CLIP image-text pretraining model as their backbone to gain semantic awareness. However, the generalist nature of these pre-trained Vision-Language (VL) models often renders them suboptimal for IQA-specific tasks. Recent approaches have attempted to address this mismatch using prompt technology, but these solutions have shortcomings. Existing prompt-based VL models overly focus on incremental semantic information from text, neglecting the rich insights available from visual data analysis. This imbalance limits their performance improvements in IQA tasks. This paper introduces an innovative multi-modal prompt-based methodology for IQA. Our approach employs carefully crafted prompts that synergistically mine incremental semantic information from both visual and linguistic data. Specifically, in the visual branch, we introduce a multi-layer prompt structure to enhance the VL model's adaptability. In the text branch, we deploy a dual-prompt scheme that steers the model to recognize and differentiate between scene category and distortion type, thereby refining the model's capacity to assess image quality. Our experimental findings underscore the effectiveness of our method over existing Blind Image Quality Assessment (BIQA) approaches. Notably, it demonstrates competitive performance across various datasets. Our method achieves Spearman Rank Correlation Coefficient (SRCC) values of 0.961(surpassing 0.946 in CSIQ) and 0.941 (exceeding 0.930 in KADID), illustrating its robustness and accuracy in diverse contexts.
Feature Denoising Diffusion Model for Blind Image Quality Assessment
Jan 22, 2024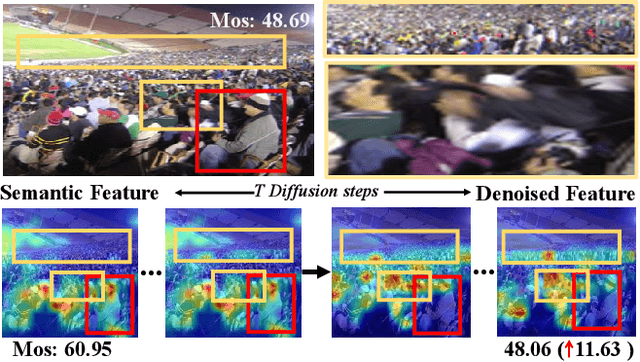
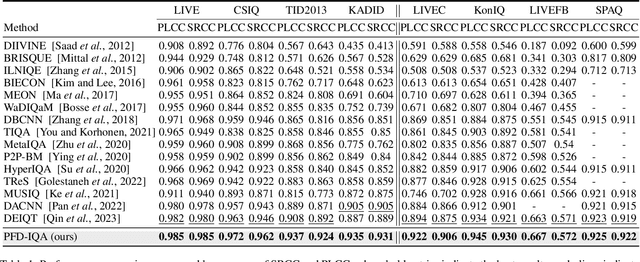
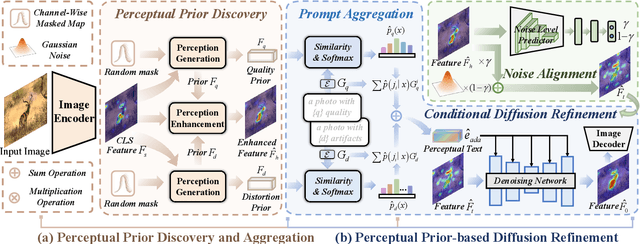
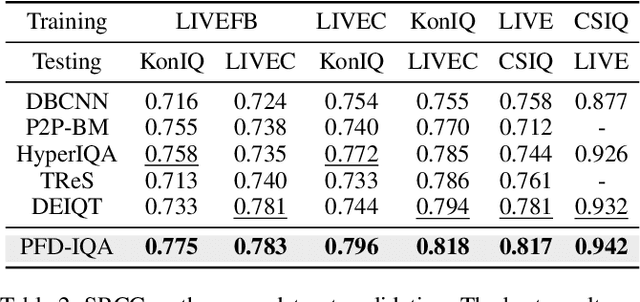
Blind Image Quality Assessment (BIQA) aims to evaluate image quality in line with human perception, without reference benchmarks. Currently, deep learning BIQA methods typically depend on using features from high-level tasks for transfer learning. However, the inherent differences between BIQA and these high-level tasks inevitably introduce noise into the quality-aware features. In this paper, we take an initial step towards exploring the diffusion model for feature denoising in BIQA, namely Perceptual Feature Diffusion for IQA (PFD-IQA), which aims to remove noise from quality-aware features. Specifically, (i) We propose a {Perceptual Prior Discovery and Aggregation module to establish two auxiliary tasks to discover potential low-level features in images that are used to aggregate perceptual text conditions for the diffusion model. (ii) We propose a Perceptual Prior-based Feature Refinement strategy, which matches noisy features to predefined denoising trajectories and then performs exact feature denoising based on text conditions. Extensive experiments on eight standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods, i.e., achieving the PLCC values of 0.935 ( vs. 0.905 in KADID) and 0.922 ( vs. 0.894 in LIVEC).
Concealed Object Segmentation with Hierarchical Coherence Modeling
Jan 22, 2024



Concealed object segmentation (COS) is a challenging task that involves localizing and segmenting those concealed objects that are visually blended with their surrounding environments. Despite achieving remarkable success, existing COS segmenters still struggle to achieve complete segmentation results in extremely concealed scenarios. In this paper, we propose a Hierarchical Coherence Modeling (HCM) segmenter for COS, aiming to address this incomplete segmentation limitation. In specific, HCM promotes feature coherence by leveraging the intra-stage coherence and cross-stage coherence modules, exploring feature correlations at both the single-stage and contextual levels. Additionally, we introduce the reversible re-calibration decoder to detect previously undetected parts in low-confidence regions, resulting in further enhancing segmentation performance. Extensive experiments conducted on three COS tasks, including camouflaged object detection, polyp image segmentation, and transparent object detection, demonstrate the promising results achieved by the proposed HCM segmenter.
Adaptive Feature Selection for No-Reference Image Quality Assessment using Contrastive Mitigating Semantic Noise Sensitivity
Dec 11, 2023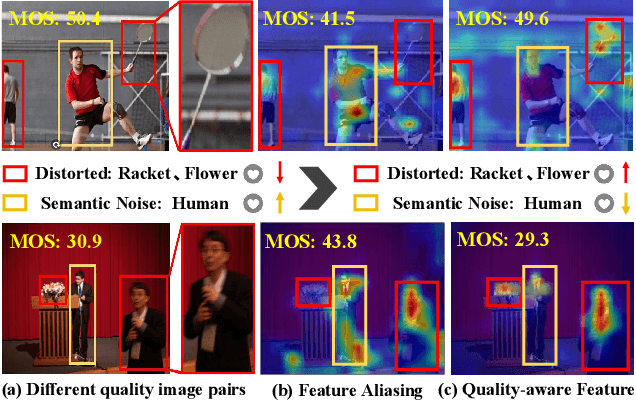
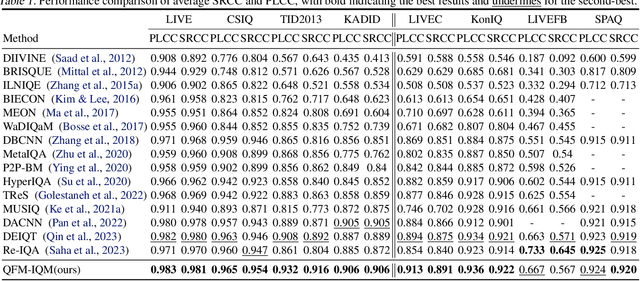
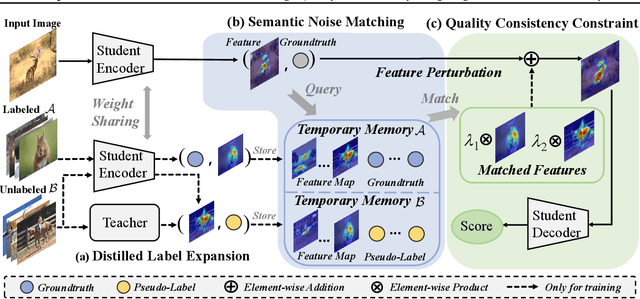
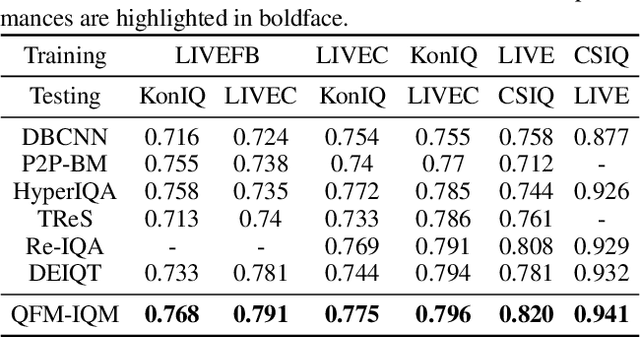
The current state-of-the-art No-Reference Image Quality Assessment (NR-IQA) methods typically use feature extraction in upstream backbone networks, which assumes that all extracted features are relevant. However, we argue that not all features are beneficial, and some may even be harmful, necessitating careful selection. Empirically, we find that many image pairs with small feature spatial distances can have vastly different quality scores. To address this issue, we propose a Quality-Aware Feature Matching IQA metric(QFM-IQM) that employs contrastive learning to remove harmful features from the upstream task. Specifically, our approach enhances the semantic noise distinguish capabilities of neural networks by comparing image pairs with similar semantic features but varying quality scores and adaptively adjusting the upstream task's features by introducing disturbance. Furthermore, we utilize a distillation framework to expand the dataset and improve the model's generalization ability. Our approach achieves superior performance to the state-of-the-art NR-IQA methods on 8 standard NR-IQA datasets, achieving PLCC values of 0.932 (vs. 0.908 in TID2013) and 0.913 (vs. 0.894 in LIVEC).
Less is More: Learning Reference Knowledge Using No-Reference Image Quality Assessment
Dec 01, 2023Image Quality Assessment (IQA) with reference images have achieved great success by imitating the human vision system, in which the image quality is effectively assessed by comparing the query image with its pristine reference image. However, for the images in the wild, it is quite difficult to access accurate reference images. We argue that it is possible to learn reference knowledge under the No-Reference Image Quality Assessment (NR-IQA) setting, which is effective and efficient empirically. Concretely, by innovatively introducing a novel feature distillation method in IQA, we propose a new framework to learn comparative knowledge from non-aligned reference images. And then, to achieve fast convergence and avoid overfitting, we further propose an inductive bias regularization. Such a framework not only solves the congenital defects of NR-IQA but also improves the feature extraction framework, enabling it to express more abundant quality information. Surprisingly, our method utilizes less input while obtaining a more significant improvement compared to the teacher models. Extensive experiments on eight standard NR-IQA datasets demonstrate the superior performance to the state-of-the-art NR-IQA methods, i.e., achieving the PLCC values of 0.917 (vs. 0.884 in LIVEC) and 0.686 (vs. 0.661 in LIVEFB).
RAUNE-Net: A Residual and Attention-Driven Underwater Image Enhancement Method
Nov 01, 2023
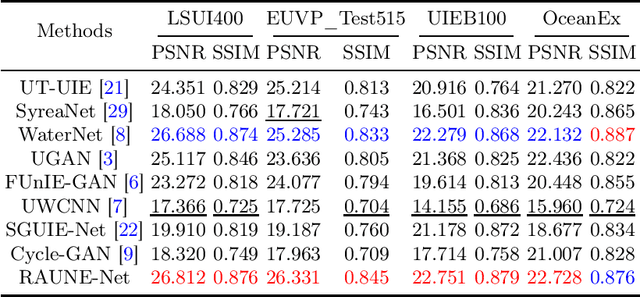


Underwater image enhancement (UIE) poses challenges due to distinctive properties of the underwater environment, including low contrast, high turbidity, visual blurriness, and color distortion. In recent years, the application of deep learning has quietly revolutionized various areas of scientific research, including UIE. However, existing deep learning-based UIE methods generally suffer from issues of weak robustness and limited adaptability. In this paper, inspired by residual and attention mechanisms, we propose a more reliable and reasonable UIE network called RAUNE-Net by employing residual learning of high-level features at the network's bottle-neck and two aspects of attention manipulations in the down-sampling procedure. Furthermore, we collect and create two datasets specifically designed for evaluating UIE methods, which contains different types of underwater distortions and degradations. The experimental validation demonstrates that our method obtains promising objective performance and consistent visual results across various real-world underwater images compared to other eight UIE methods. Our example code and datasets are publicly available at https://github.com/fansuregrin/RAUNE-Net.
AquaSAM: Underwater Image Foreground Segmentation
Aug 08, 2023

The Segment Anything Model (SAM) has revolutionized natural image segmentation, nevertheless, its performance on underwater images is still restricted. This work presents AquaSAM, the first attempt to extend the success of SAM on underwater images with the purpose of creating a versatile method for the segmentation of various underwater targets. To achieve this, we begin by classifying and extracting various labels automatically in SUIM dataset. Subsequently, we develop a straightforward fine-tuning method to adapt SAM to general foreground underwater image segmentation. Through extensive experiments involving eight segmentation tasks like human divers, we demonstrate that AquaSAM outperforms the default SAM model especially at hard tasks like coral reefs. AquaSAM achieves an average Dice Similarity Coefficient (DSC) of 7.13 (%) improvement and an average of 8.27 (%) on mIoU improvement in underwater segmentation tasks.
Data-Efficient Image Quality Assessment with Attention-Panel Decoder
Apr 11, 2023
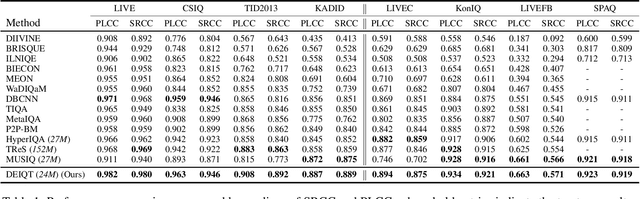


Blind Image Quality Assessment (BIQA) is a fundamental task in computer vision, which however remains unresolved due to the complex distortion conditions and diversified image contents. To confront this challenge, we in this paper propose a novel BIQA pipeline based on the Transformer architecture, which achieves an efficient quality-aware feature representation with much fewer data. More specifically, we consider the traditional fine-tuning in BIQA as an interpretation of the pre-trained model. In this way, we further introduce a Transformer decoder to refine the perceptual information of the CLS token from different perspectives. This enables our model to establish the quality-aware feature manifold efficiently while attaining a strong generalization capability. Meanwhile, inspired by the subjective evaluation behaviors of human, we introduce a novel attention panel mechanism, which improves the model performance and reduces the prediction uncertainty simultaneously. The proposed BIQA method maintains a lightweight design with only one layer of the decoder, yet extensive experiments on eight standard BIQA datasets (both synthetic and authentic) demonstrate its superior performance to the state-of-the-art BIQA methods, i.e., achieving the SRCC values of 0.875 (vs. 0.859 in LIVEC) and 0.980 (vs. 0.969 in LIVE).