 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZooming from Context to Cue: Hierarchical Preference Optimization for Multi-Image MLLMs
May 28, 2025Multi-modal Large Language Models (MLLMs) excel at single-image tasks but struggle with multi-image understanding due to cross-modal misalignment, leading to hallucinations (context omission, conflation, and misinterpretation). Existing methods using Direct Preference Optimization (DPO) constrain optimization to a solitary image reference within the input sequence, neglecting holistic context modeling. We propose Context-to-Cue Direct Preference Optimization (CcDPO), a multi-level preference optimization framework that enhances per-image perception in multi-image settings by zooming into visual clues -- from sequential context to local details. It features: (i) Context-Level Optimization : Re-evaluates cognitive biases underlying MLLMs' multi-image context comprehension and integrates a spectrum of low-cost global sequence preferences for bias mitigation. (ii) Needle-Level Optimization : Directs attention to fine-grained visual details through region-targeted visual prompts and multimodal preference supervision. To support scalable optimization, we also construct MultiScope-42k, an automatically generated dataset with high-quality multi-level preference pairs. Experiments show that CcDPO significantly reduces hallucinations and yields consistent performance gains across general single- and multi-image tasks.
Towards Accurate and Interpretable Neuroblastoma Diagnosis via Contrastive Multi-scale Pathological Image Analysis
Apr 18, 2025



Neuroblastoma, adrenal-derived, is among the most common pediatric solid malignancies, characterized by significant clinical heterogeneity. Timely and accurate pathological diagnosis from hematoxylin and eosin-stained whole slide images is critical for patient prognosis. However, current diagnostic practices primarily rely on subjective manual examination by pathologists, leading to inconsistent accuracy. Existing automated whole slide image classification methods encounter challenges such as poor interpretability, limited feature extraction capabilities, and high computational costs, restricting their practical clinical deployment. To overcome these limitations, we propose CMSwinKAN, a contrastive-learning-based multi-scale feature fusion model tailored for pathological image classification, which enhances the Swin Transformer architecture by integrating a Kernel Activation Network within its multilayer perceptron and classification head modules, significantly improving both interpretability and accuracy. By fusing multi-scale features and leveraging contrastive learning strategies, CMSwinKAN mimics clinicians' comprehensive approach, effectively capturing global and local tissue characteristics. Additionally, we introduce a heuristic soft voting mechanism guided by clinical insights to seamlessly bridge patch-level predictions to whole slide image-level classifications. We validate CMSwinKAN on the PpNTs dataset, which was collaboratively established with our partner hospital and the publicly accessible BreakHis dataset. Results demonstrate that CMSwinKAN performs better than existing state-of-the-art pathology-specific models pre-trained on large datasets. Our source code is available at https://github.com/JSLiam94/CMSwinKAN.
Feature Denoising Diffusion Model for Blind Image Quality Assessment
Jan 22, 2024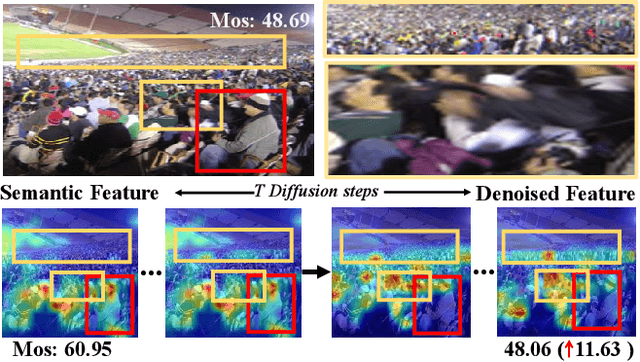
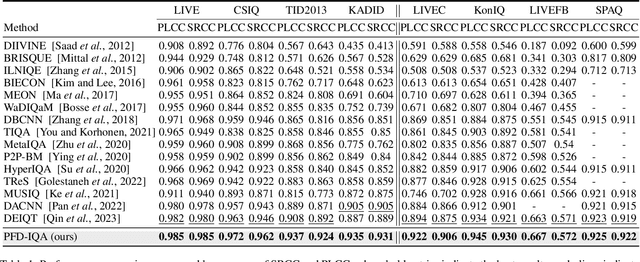
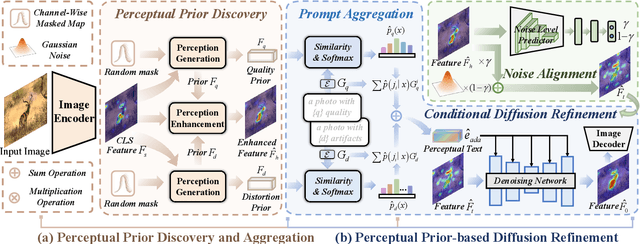
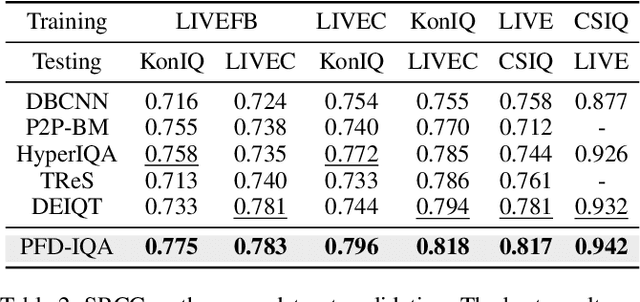
Blind Image Quality Assessment (BIQA) aims to evaluate image quality in line with human perception, without reference benchmarks. Currently, deep learning BIQA methods typically depend on using features from high-level tasks for transfer learning. However, the inherent differences between BIQA and these high-level tasks inevitably introduce noise into the quality-aware features. In this paper, we take an initial step towards exploring the diffusion model for feature denoising in BIQA, namely Perceptual Feature Diffusion for IQA (PFD-IQA), which aims to remove noise from quality-aware features. Specifically, (i) We propose a {Perceptual Prior Discovery and Aggregation module to establish two auxiliary tasks to discover potential low-level features in images that are used to aggregate perceptual text conditions for the diffusion model. (ii) We propose a Perceptual Prior-based Feature Refinement strategy, which matches noisy features to predefined denoising trajectories and then performs exact feature denoising based on text conditions. Extensive experiments on eight standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods, i.e., achieving the PLCC values of 0.935 ( vs. 0.905 in KADID) and 0.922 ( vs. 0.894 in LIVEC).
Adaptive Feature Selection for No-Reference Image Quality Assessment using Contrastive Mitigating Semantic Noise Sensitivity
Dec 11, 2023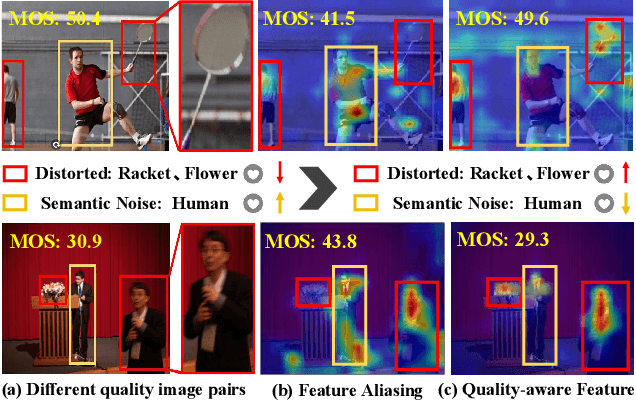
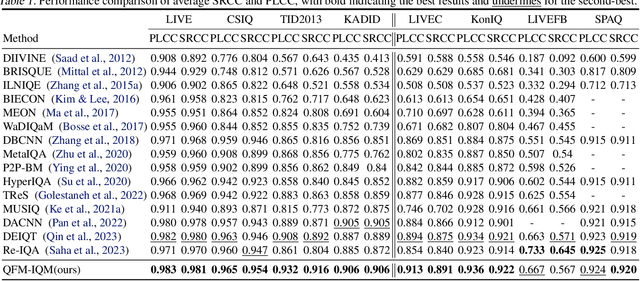
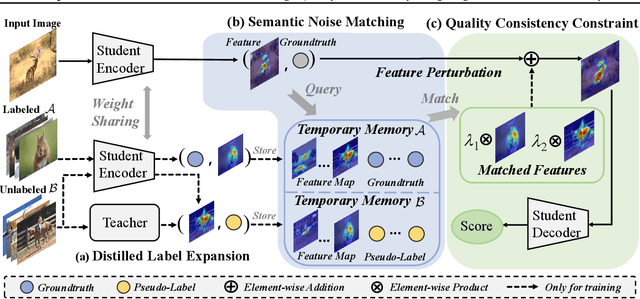
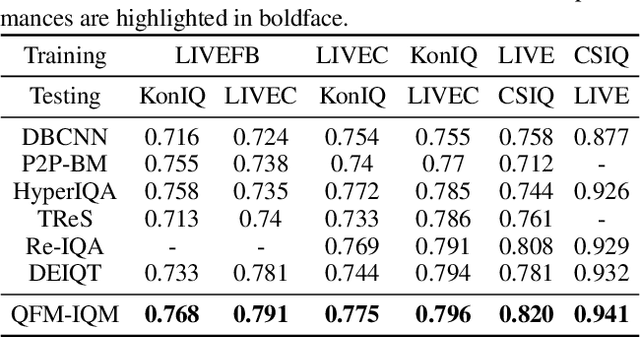
The current state-of-the-art No-Reference Image Quality Assessment (NR-IQA) methods typically use feature extraction in upstream backbone networks, which assumes that all extracted features are relevant. However, we argue that not all features are beneficial, and some may even be harmful, necessitating careful selection. Empirically, we find that many image pairs with small feature spatial distances can have vastly different quality scores. To address this issue, we propose a Quality-Aware Feature Matching IQA metric(QFM-IQM) that employs contrastive learning to remove harmful features from the upstream task. Specifically, our approach enhances the semantic noise distinguish capabilities of neural networks by comparing image pairs with similar semantic features but varying quality scores and adaptively adjusting the upstream task's features by introducing disturbance. Furthermore, we utilize a distillation framework to expand the dataset and improve the model's generalization ability. Our approach achieves superior performance to the state-of-the-art NR-IQA methods on 8 standard NR-IQA datasets, achieving PLCC values of 0.932 (vs. 0.908 in TID2013) and 0.913 (vs. 0.894 in LIVEC).
Less is More: Learning Reference Knowledge Using No-Reference Image Quality Assessment
Dec 01, 2023Image Quality Assessment (IQA) with reference images have achieved great success by imitating the human vision system, in which the image quality is effectively assessed by comparing the query image with its pristine reference image. However, for the images in the wild, it is quite difficult to access accurate reference images. We argue that it is possible to learn reference knowledge under the No-Reference Image Quality Assessment (NR-IQA) setting, which is effective and efficient empirically. Concretely, by innovatively introducing a novel feature distillation method in IQA, we propose a new framework to learn comparative knowledge from non-aligned reference images. And then, to achieve fast convergence and avoid overfitting, we further propose an inductive bias regularization. Such a framework not only solves the congenital defects of NR-IQA but also improves the feature extraction framework, enabling it to express more abundant quality information. Surprisingly, our method utilizes less input while obtaining a more significant improvement compared to the teacher models. Extensive experiments on eight standard NR-IQA datasets demonstrate the superior performance to the state-of-the-art NR-IQA methods, i.e., achieving the PLCC values of 0.917 (vs. 0.884 in LIVEC) and 0.686 (vs. 0.661 in LIVEFB).