 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Prompt Learning on Blind Image Quality Assessment
Apr 23, 2024



Image Quality Assessment (IQA) models benefit significantly from semantic information, which allows them to treat different types of objects distinctly. Currently, leveraging semantic information to enhance IQA is a crucial research direction. Traditional methods, hindered by a lack of sufficiently annotated data, have employed the CLIP image-text pretraining model as their backbone to gain semantic awareness. However, the generalist nature of these pre-trained Vision-Language (VL) models often renders them suboptimal for IQA-specific tasks. Recent approaches have attempted to address this mismatch using prompt technology, but these solutions have shortcomings. Existing prompt-based VL models overly focus on incremental semantic information from text, neglecting the rich insights available from visual data analysis. This imbalance limits their performance improvements in IQA tasks. This paper introduces an innovative multi-modal prompt-based methodology for IQA. Our approach employs carefully crafted prompts that synergistically mine incremental semantic information from both visual and linguistic data. Specifically, in the visual branch, we introduce a multi-layer prompt structure to enhance the VL model's adaptability. In the text branch, we deploy a dual-prompt scheme that steers the model to recognize and differentiate between scene category and distortion type, thereby refining the model's capacity to assess image quality. Our experimental findings underscore the effectiveness of our method over existing Blind Image Quality Assessment (BIQA) approaches. Notably, it demonstrates competitive performance across various datasets. Our method achieves Spearman Rank Correlation Coefficient (SRCC) values of 0.961(surpassing 0.946 in CSIQ) and 0.941 (exceeding 0.930 in KADID), illustrating its robustness and accuracy in diverse contexts.
Sinkhorn Distance Minimization for Knowledge Distillation
Feb 27, 2024Knowledge distillation (KD) has been widely adopted to compress large language models (LLMs). Existing KD methods investigate various divergence measures including the Kullback-Leibler (KL), reverse Kullback-Leibler (RKL), and Jensen-Shannon (JS) divergences. However, due to limitations inherent in their assumptions and definitions, these measures fail to deliver effective supervision when few distribution overlap exists between the teacher and the student. In this paper, we show that the aforementioned KL, RKL, and JS divergences respectively suffer from issues of mode-averaging, mode-collapsing, and mode-underestimation, which deteriorates logits-based KD for diverse NLP tasks. We propose the Sinkhorn Knowledge Distillation (SinKD) that exploits the Sinkhorn distance to ensure a nuanced and precise assessment of the disparity between teacher and student distributions. Besides, profit by properties of the Sinkhorn metric, we can get rid of sample-wise KD that restricts the perception of divergence in each teacher-student sample pair. Instead, we propose a batch-wise reformulation to capture geometric intricacies of distributions across samples in the high-dimensional space. Comprehensive evaluation on GLUE and SuperGLUE, in terms of comparability, validity, and generalizability, highlights our superiority over state-of-the-art methods on all kinds of LLMs with encoder-only, encoder-decoder, and decoder-only architectures.
MMICT: Boosting Multi-Modal Fine-Tuning with In-Context Examples
Dec 12, 2023


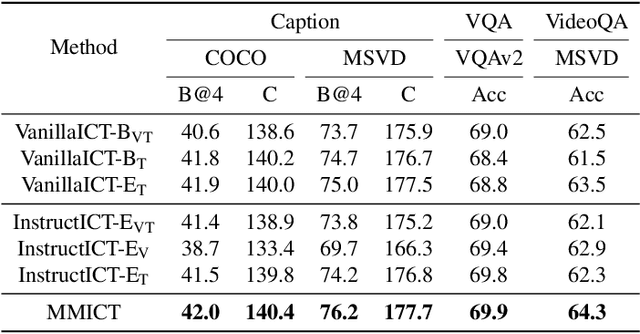
Although In-Context Learning (ICL) brings remarkable performance gains to Large Language Models (LLMs), the improvements remain lower than fine-tuning on downstream tasks. This paper introduces Multi-Modal In-Context Tuning (MMICT), a novel multi-modal fine-tuning paradigm that boosts multi-modal fine-tuning by fully leveraging the promising ICL capability of multi-modal LLMs (MM-LLMs). We propose the Multi-Modal Hub (M-Hub), a unified module that captures various multi-modal features according to different inputs and objectives. Based on M-Hub, MMICT enables MM-LLMs to learn from in-context visual-guided textual features and subsequently generate outputs conditioned on the textual-guided visual features. Moreover, leveraging the flexibility of M-Hub, we design a variety of in-context demonstrations. Extensive experiments on a diverse range of downstream multi-modal tasks demonstrate that MMICT significantly outperforms traditional fine-tuning strategy and the vanilla ICT method that directly takes the concatenation of all information from different modalities as input.
Less is More: Learning Reference Knowledge Using No-Reference Image Quality Assessment
Dec 01, 2023Image Quality Assessment (IQA) with reference images have achieved great success by imitating the human vision system, in which the image quality is effectively assessed by comparing the query image with its pristine reference image. However, for the images in the wild, it is quite difficult to access accurate reference images. We argue that it is possible to learn reference knowledge under the No-Reference Image Quality Assessment (NR-IQA) setting, which is effective and efficient empirically. Concretely, by innovatively introducing a novel feature distillation method in IQA, we propose a new framework to learn comparative knowledge from non-aligned reference images. And then, to achieve fast convergence and avoid overfitting, we further propose an inductive bias regularization. Such a framework not only solves the congenital defects of NR-IQA but also improves the feature extraction framework, enabling it to express more abundant quality information. Surprisingly, our method utilizes less input while obtaining a more significant improvement compared to the teacher models. Extensive experiments on eight standard NR-IQA datasets demonstrate the superior performance to the state-of-the-art NR-IQA methods, i.e., achieving the PLCC values of 0.917 (vs. 0.884 in LIVEC) and 0.686 (vs. 0.661 in LIVEFB).
Towards Robust Text Retrieval with Progressive Learning
Nov 20, 2023



Retrieval augmentation has become an effective solution to empower large language models (LLMs) with external and verified knowledge sources from the database, which overcomes the limitations and hallucinations of LLMs in handling up-to-date and domain-specific information. However, existing embedding models for text retrieval usually have three non-negligible limitations. First, the number and diversity of samples in a batch are too restricted to supervise the modeling of textual nuances at scale. Second, the high proportional noise are detrimental to the semantic correctness and consistency of embeddings. Third, the equal treatment to easy and difficult samples would cause sub-optimum convergence of embeddings with poorer generalization. In this paper, we propose the PEG, a progressively learned embeddings for robust text retrieval. Specifically, we increase the training in-batch negative samples to 80,000, and for each query, we extracted five hard negatives. Concurrently, we incorporated a progressive learning mechanism, enabling the model to dynamically modulate its attention to the samples throughout the entire training process. Additionally, PEG is trained on more than 100 million data, encompassing a wide range of domains (e.g., finance, medicine, and tourism) and covering various tasks (e.g., question-answering, machine reading comprehension, and similarity matching). Extensive experiments conducted on C-MTEB and DuReader demonstrate that PEG surpasses state-of-the-art embeddings in retrieving true positives, highlighting its significant potential for applications in LLMs. Our model is publicly available at https://huggingface.co/TownsWu/PEG.
Multi-dataset Training of Transformers for Robust Action Recognition
Oct 12, 2022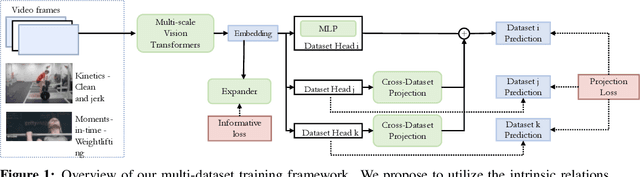
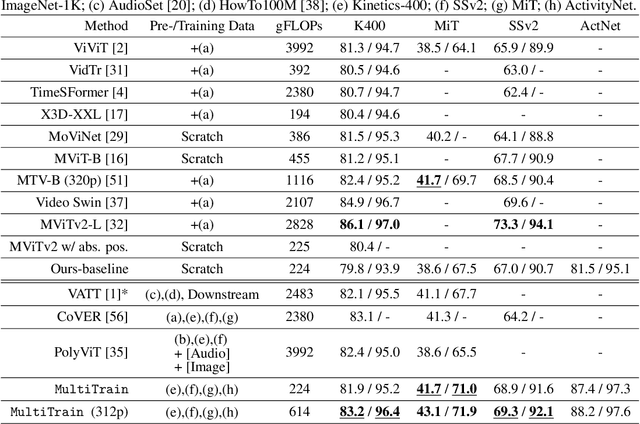
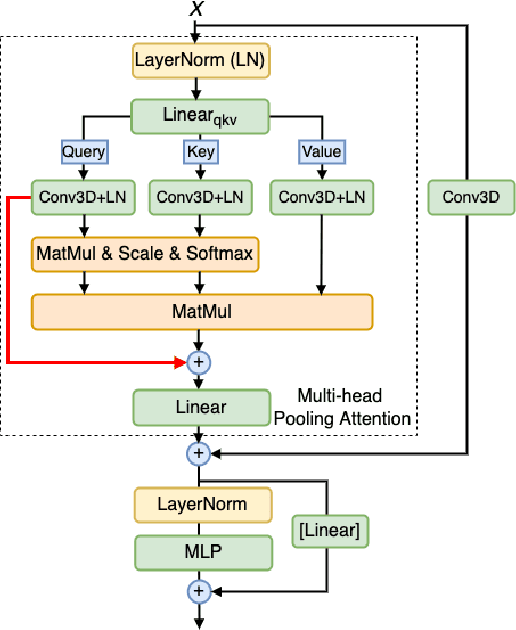

We study the task of robust feature representations, aiming to generalize well on multiple datasets for action recognition. We build our method on Transformers for its efficacy. Although we have witnessed great progress for video action recognition in the past decade, it remains challenging yet valuable how to train a single model that can perform well across multiple datasets. Here, we propose a novel multi-dataset training paradigm, MultiTrain, with the design of two new loss terms, namely informative loss and projection loss, aiming to learn robust representations for action recognition. In particular, the informative loss maximizes the expressiveness of the feature embedding while the projection loss for each dataset mines the intrinsic relations between classes across datasets. We verify the effectiveness of our method on five challenging datasets, Kinetics-400, Kinetics-700, Moments-in-Time, Activitynet and Something-something-v2 datasets. Extensive experimental results show that our method can consistently improve state-of-the-art performance. Code and models are released.
One for More: Selecting Generalizable Samples for Generalizable ReID Model
Dec 11, 2020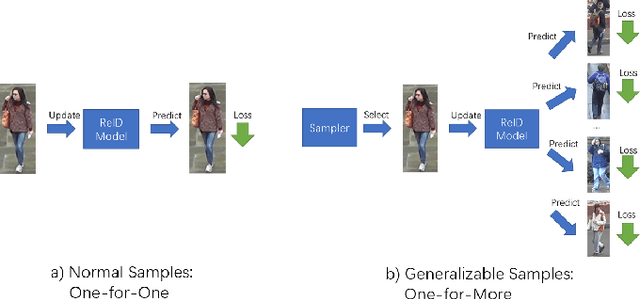
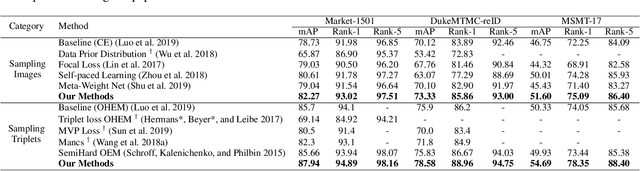
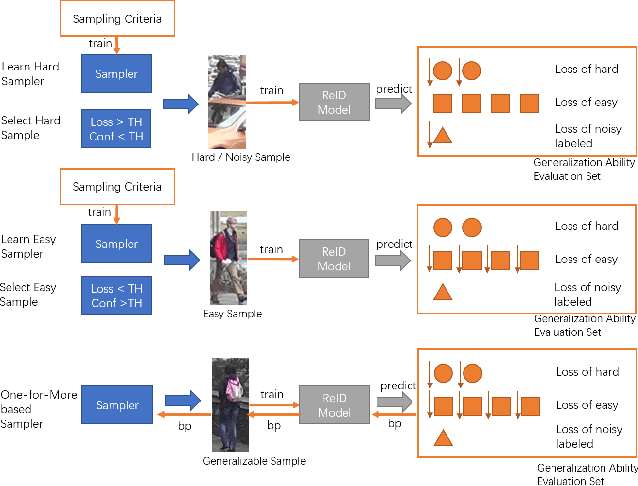
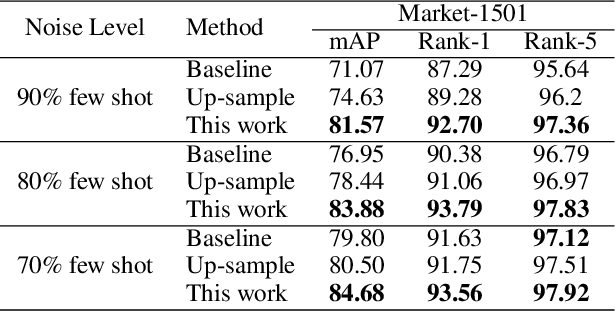
Current training objectives of existing person Re-IDentification (ReID) models only ensure that the loss of the model decreases on selected training batch, with no regards to the performance on samples outside the batch. It will inevitably cause the model to over-fit the data in the dominant position (e.g., head data in imbalanced class, easy samples or noisy samples). %We call the sample that updates the model towards generalizing on more data a generalizable sample. The latest resampling methods address the issue by designing specific criterion to select specific samples that trains the model generalize more on certain type of data (e.g., hard samples, tail data), which is not adaptive to the inconsistent real world ReID data distributions. Therefore, instead of simply presuming on what samples are generalizable, this paper proposes a one-for-more training objective that directly takes the generalization ability of selected samples as a loss function and learn a sampler to automatically select generalizable samples. More importantly, our proposed one-for-more based sampler can be seamlessly integrated into the ReID training framework which is able to simultaneously train ReID models and the sampler in an end-to-end fashion. The experimental results show that our method can effectively improve the ReID model training and boost the performance of ReID models.
Real-time Multi-target Path Prediction and Planning for Autonomous Driving aided by FCN
Sep 17, 2019
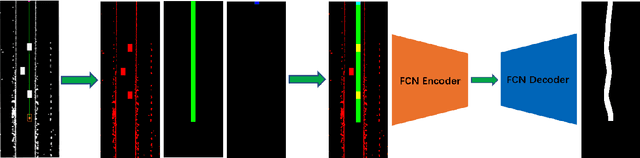
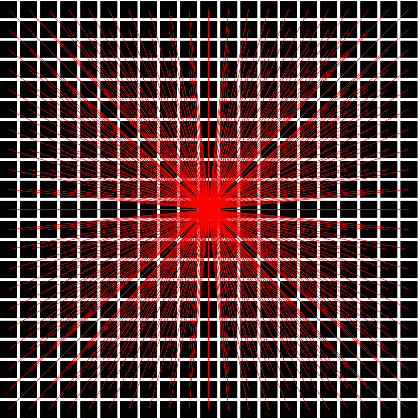
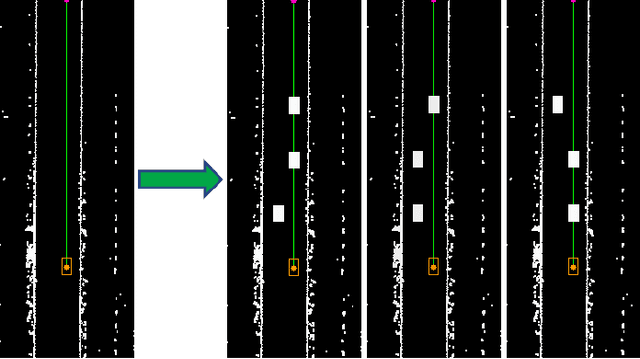
Real-time multi-target path planning is a key issue in the field of autonomous driving. Although multiple paths can be generated in real-time with polynomial curves, the generated paths are not flexible enough to deal with complex road scenes such as S-shaped road and unstructured scenes such as parking lots. Search and sampling-based methods, such as A* and RRT and their derived methods, are flexible in generating paths for these complex road environments. However, the existing algorithms require significant time to plan to multiple targets, which greatly limits their application in autonomous driving. In this paper, a real-time path planning method for multi-targets is proposed. We train a fully convolutional neural network (FCN) to predict a path region for the target at first. By taking the predicted path region as soft constraints, the A* algorithm is then applied to search the exact path to the target. Experiments show that FCN can make multiple predictions in a very short time (50 times in 40ms), and the predicted path region effectively restrict the searching space for the following A* search. Therefore, the A* can search much faster so that the multi-target path planning can be achieved in real-time (3 targets in less than 100ms).
TiEV: The Tongji Intelligent Electric Vehicle in the Intelligent Vehicle Future Challenge of China
May 07, 2018
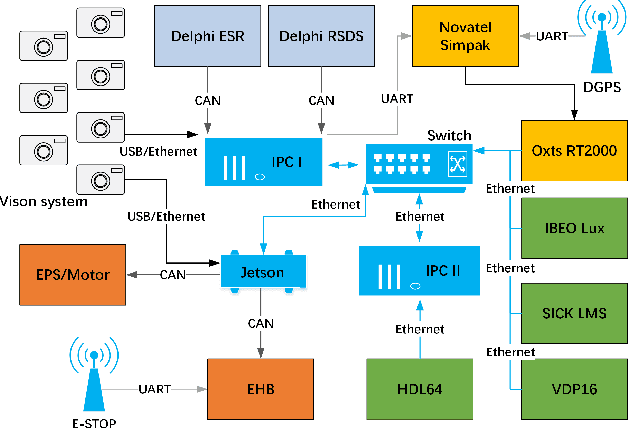
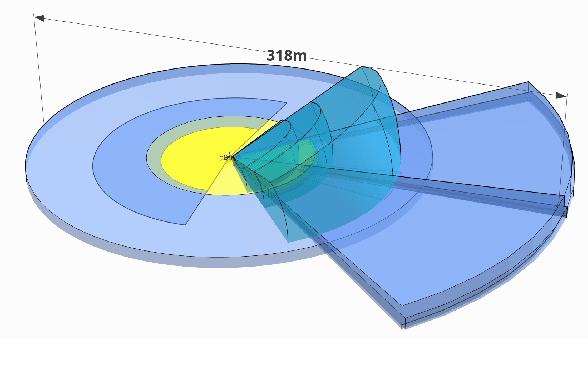
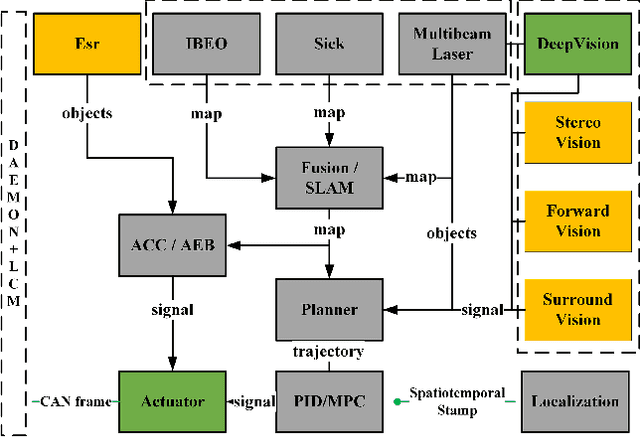
TiEV is an autonomous driving platform implemented by Tongji University of China. The vehicle is drive-by-wire and is fully powered by electricity. We devised the software system of TiEV from scratch, which is capable of driving the vehicle autonomously in urban paths as well as on fast express roads. We describe our whole system, especially novel modules of probabilistic perception fusion, incremental mapping, the 1st and the 2nd planning and the overall safety concern. TiEV finished 2016 and 2017 Intelligent Vehicle Future Challenge of China held at Changshu. We show our experiences on the development of autonomous vehicles and future trends.