 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Dataset Condensation for Diffusion Model Training
Jun 04, 2026Dataset condensation aims to construct compact datasets from real data via synthesis or selection. However, existing approaches are ill-suited for diffusion model training: synthetic data generation often yields low-fidelity samples unsuitable for authentic modeling, while real subset selection typically fails to preserve the distributional geometry required by diffusion likelihood objectives. To address this, we propose to reformulate real subset selection as a geometry-aware distribution alignment problem. By incorporating one-sided partial optimal transport, our method selectively aligns a compact subset with the full data distribution while allowing unmatched mass in low-density regions, ensuring the preserved geometric structure necessary for effective diffusion model training. To further ensure distributional fidelity, we complement geometric alignment with lightweight feature-statistics and semantic consistency regularization. An efficient two-stage discrete optimization strategy is proposed to achieve this alignment objective. Extensive experiments across diffusion variants, subset sizes, image resolutions, and training rounds show that our method achieves superior fidelity and distributional coverage in diffusion model training. Codes are available at https://github.com/2018cx/GADC.
Multi-Level Optimal Transport for Universal Cross-Tokenizer Knowledge Distillation on Language Models
Dec 19, 2024

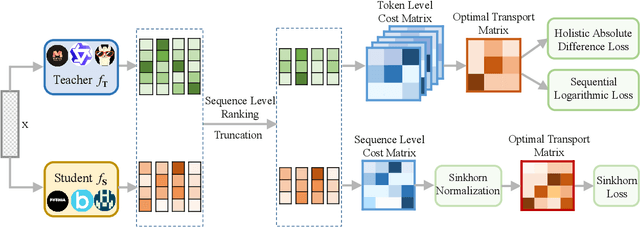

Knowledge distillation (KD) has become a prevalent technique for compressing large language models (LLMs). Existing KD methods are constrained by the need for identical tokenizers (i.e., vocabularies) between teacher and student models, limiting their versatility in handling LLMs of different architecture families. In this paper, we introduce the Multi-Level Optimal Transport (MultiLevelOT), a novel approach that advances the optimal transport for universal cross-tokenizer knowledge distillation. Our method aligns the logit distributions of the teacher and the student at both token and sequence levels using diverse cost matrices, eliminating the need for dimensional or token-by-token correspondence. At the token level, MultiLevelOT integrates both global and local information by jointly optimizing all tokens within a sequence to enhance robustness. At the sequence level, we efficiently capture complex distribution structures of logits via the Sinkhorn distance, which approximates the Wasserstein distance for divergence measures. Extensive experiments on tasks such as extractive QA, generative QA, and summarization demonstrate that the MultiLevelOT outperforms state-of-the-art cross-tokenizer KD methods under various settings. Our approach is robust to different student and teacher models across model families, architectures, and parameter sizes.
Systematic Feature Design for Cycle Life Prediction of Lithium-Ion Batteries During Formation
Oct 09, 2024



Optimization of the formation step in lithium-ion battery manufacturing is challenging due to limited physical understanding of solid electrolyte interphase formation and the long testing time (~100 days) for cells to reach the end of life. We propose a systematic feature design framework that requires minimal domain knowledge for accurate cycle life prediction during formation. Two simple Q(V) features designed from our framework, extracted from formation data without any additional diagnostic cycles, achieved a median of 9.20% error for cycle life prediction, outperforming thousands of autoML models using pre-defined features. We attribute the strong performance of our designed features to their physical origins - the voltage ranges identified by our framework capture the effects of formation temperature and microscopic particle resistance heterogeneity. By designing highly interpretable features, our approach can accelerate formation research, leveraging the interplay between data-driven feature design and mechanistic understanding.
StreetSurfGS: Scalable Urban Street Surface Reconstruction with Planar-based Gaussian Splatting
Oct 06, 2024



Reconstructing urban street scenes is crucial due to its vital role in applications such as autonomous driving and urban planning. These scenes are characterized by long and narrow camera trajectories, occlusion, complex object relationships, and data sparsity across multiple scales. Despite recent advancements, existing surface reconstruction methods, which are primarily designed for object-centric scenarios, struggle to adapt effectively to the unique characteristics of street scenes. To address this challenge, we introduce StreetSurfGS, the first method to employ Gaussian Splatting specifically tailored for scalable urban street scene surface reconstruction. StreetSurfGS utilizes a planar-based octree representation and segmented training to reduce memory costs, accommodate unique camera characteristics, and ensure scalability. Additionally, to mitigate depth inaccuracies caused by object overlap, we propose a guided smoothing strategy within regularization to eliminate inaccurate boundary points and outliers. Furthermore, to address sparse views and multi-scale challenges, we use a dual-step matching strategy that leverages adjacent and long-term information. Extensive experiments validate the efficacy of StreetSurfGS in both novel view synthesis and surface reconstruction.
Sinkhorn Distance Minimization for Knowledge Distillation
Feb 27, 2024



Knowledge distillation (KD) has been widely adopted to compress large language models (LLMs). Existing KD methods investigate various divergence measures including the Kullback-Leibler (KL), reverse Kullback-Leibler (RKL), and Jensen-Shannon (JS) divergences. However, due to limitations inherent in their assumptions and definitions, these measures fail to deliver effective supervision when few distribution overlap exists between the teacher and the student. In this paper, we show that the aforementioned KL, RKL, and JS divergences respectively suffer from issues of mode-averaging, mode-collapsing, and mode-underestimation, which deteriorates logits-based KD for diverse NLP tasks. We propose the Sinkhorn Knowledge Distillation (SinKD) that exploits the Sinkhorn distance to ensure a nuanced and precise assessment of the disparity between teacher and student distributions. Besides, profit by properties of the Sinkhorn metric, we can get rid of sample-wise KD that restricts the perception of divergence in each teacher-student sample pair. Instead, we propose a batch-wise reformulation to capture geometric intricacies of distributions across samples in the high-dimensional space. Comprehensive evaluation on GLUE and SuperGLUE, in terms of comparability, validity, and generalizability, highlights our superiority over state-of-the-art methods on all kinds of LLMs with encoder-only, encoder-decoder, and decoder-only architectures.
Exploiting GPT-4 Vision for Zero-shot Point Cloud Understanding
Jan 15, 2024In this study, we tackle the challenge of classifying the object category in point clouds, which previous works like PointCLIP struggle to address due to the inherent limitations of the CLIP architecture. Our approach leverages GPT-4 Vision (GPT-4V) to overcome these challenges by employing its advanced generative abilities, enabling a more adaptive and robust classification process. We adapt the application of GPT-4V to process complex 3D data, enabling it to achieve zero-shot recognition capabilities without altering the underlying model architecture. Our methodology also includes a systematic strategy for point cloud image visualization, mitigating domain gap and enhancing GPT-4V's efficiency. Experimental validation demonstrates our approach's superiority in diverse scenarios, setting a new benchmark in zero-shot point cloud classification.
Heredity-aware Child Face Image Generation with Latent Space Disentanglement
Aug 25, 2021



Generative adversarial networks have been widely used in image synthesis in recent years and the quality of the generated image has been greatly improved. However, the flexibility to control and decouple facial attributes (e.g., eyes, nose, mouth) is still limited. In this paper, we propose a novel approach, called ChildGAN, to generate a child's image according to the images of parents with heredity prior. The main idea is to disentangle the latent space of a pre-trained generation model and precisely control the face attributes of child images with clear semantics. We use distances between face landmarks as pseudo labels to figure out the most influential semantic vectors of the corresponding face attributes by calculating the gradient of latent vectors to pseudo labels. Furthermore, we disentangle the semantic vectors by weighting irrelevant features and orthogonalizing them with Schmidt Orthogonalization. Finally, we fuse the latent vector of the parents by leveraging the disentangled semantic vectors under the guidance of biological genetic laws. Extensive experiments demonstrate that our approach outperforms the existing methods with encouraging results.
Baidu Apollo Auto-Calibration System - An Industry-Level Data-Driven and Learning based Vehicle Longitude Dynamic Calibrating Algorithm
Aug 30, 2018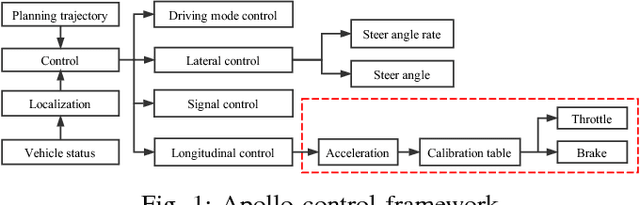
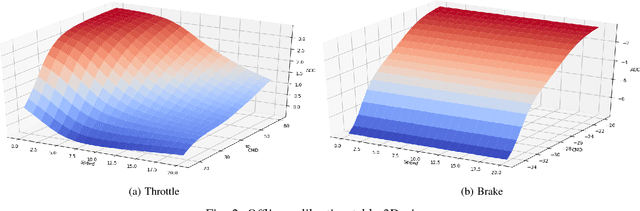
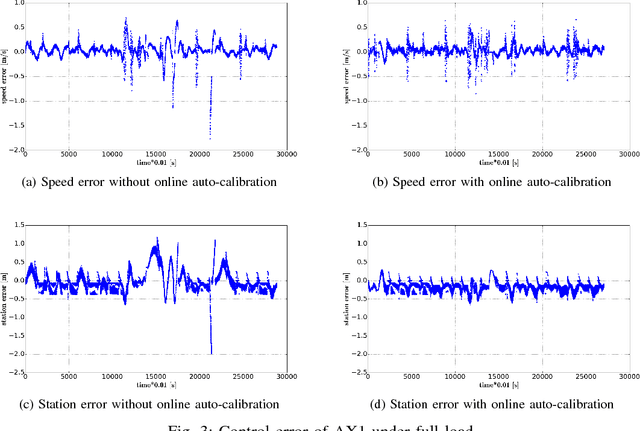
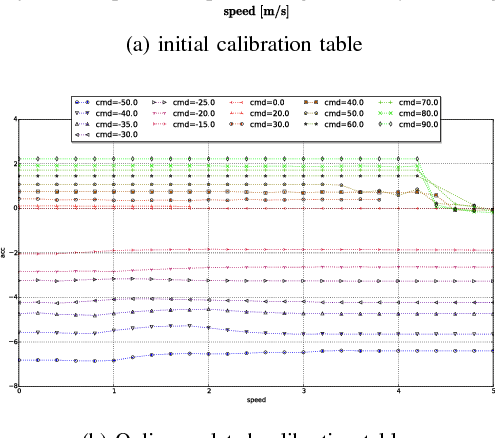
For any autonomous driving vehicle, control module determines its road performance and safety, i.e. its precision and stability should stay within a carefully-designed range. Nonetheless, control algorithms require vehicle dynamics (such as longitudinal dynamics) as inputs, which, unfortunately, are obscure to calibrate in real time. As a result, to achieve reasonable performance, most, if not all, research-oriented autonomous vehicles do manual calibrations in a one-by-one fashion. Since manual calibration is not sustainable once entering into mass production stage for industrial purposes, we here introduce a machine-learning based auto-calibration system for autonomous driving vehicles. In this paper, we will show how we build a data-driven longitudinal calibration procedure using machine learning techniques. We first generated offline calibration tables from human driving data. The offline table serves as an initial guess for later uses and it only needs twenty-minutes data collection and process. We then used an online-learning algorithm to appropriately update the initial table (the offline table) based on real-time performance analysis. This longitudinal auto-calibration system has been deployed to more than one hundred Baidu Apollo self-driving vehicles (including hybrid family vehicles and electronic delivery-only vehicles) since April 2018. By August 27, 2018, it had been tested for more than two thousands hours, ten thousands kilometers (6,213 miles) and yet proven to be effective.