 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAltFreezing for More General Video Face Forgery Detection
Jul 17, 2023Existing face forgery detection models try to discriminate fake images by detecting only spatial artifacts (e.g., generative artifacts, blending) or mainly temporal artifacts (e.g., flickering, discontinuity). They may experience significant performance degradation when facing out-domain artifacts. In this paper, we propose to capture both spatial and temporal artifacts in one model for face forgery detection. A simple idea is to leverage a spatiotemporal model (3D ConvNet). However, we find that it may easily rely on one type of artifact and ignore the other. To address this issue, we present a novel training strategy called AltFreezing for more general face forgery detection. The AltFreezing aims to encourage the model to detect both spatial and temporal artifacts. It divides the weights of a spatiotemporal network into two groups: spatial-related and temporal-related. Then the two groups of weights are alternately frozen during the training process so that the model can learn spatial and temporal features to distinguish real or fake videos. Furthermore, we introduce various video-level data augmentation methods to improve the generalization capability of the forgery detection model. Extensive experiments show that our framework outperforms existing methods in terms of generalization to unseen manipulations and datasets. Code is available at https: //github.com/ZhendongWang6/AltFreezing.
DIRE for Diffusion-Generated Image Detection
Mar 16, 2023Diffusion models have shown remarkable success in visual synthesis, but have also raised concerns about potential abuse for malicious purposes. In this paper, we seek to build a detector for telling apart real images from diffusion-generated images. We find that existing detectors struggle to detect images generated by diffusion models, even if we include generated images from a specific diffusion model in their training data. To address this issue, we propose a novel image representation called DIffusion Reconstruction Error (DIRE), which measures the error between an input image and its reconstruction counterpart by a pre-trained diffusion model. We observe that diffusion-generated images can be approximately reconstructed by a diffusion model while real images cannot. It provides a hint that DIRE can serve as a bridge to distinguish generated and real images. DIRE provides an effective way to detect images generated by most diffusion models, and it is general for detecting generated images from unseen diffusion models and robust to various perturbations. Furthermore, we establish a comprehensive diffusion-generated benchmark including images generated by eight diffusion models to evaluate the performance of diffusion-generated image detectors. Extensive experiments on our collected benchmark demonstrate that DIRE exhibits superiority over previous generated-image detectors. The code and dataset are available at https://github.com/ZhendongWang6/DIRE.
Hand-Object Interaction Image Generation
Nov 28, 2022In this work, we are dedicated to a new task, i.e., hand-object interaction image generation, which aims to conditionally generate the hand-object image under the given hand, object and their interaction status. This task is challenging and research-worthy in many potential application scenarios, such as AR/VR games and online shopping, etc. To address this problem, we propose a novel HOGAN framework, which utilizes the expressive model-aware hand-object representation and leverages its inherent topology to build the unified surface space. In this space, we explicitly consider the complex self- and mutual occlusion during interaction. During final image synthesis, we consider different characteristics of hand and object and generate the target image in a split-and-combine manner. For evaluation, we build a comprehensive protocol to access both the fidelity and structure preservation of the generated image. Extensive experiments on two large-scale datasets, i.e., HO3Dv3 and DexYCB, demonstrate the effectiveness and superiority of our framework both quantitatively and qualitatively. The project page is available at https://play-with-hoi-generation.github.io/.
CLIP2GAN: Towards Bridging Text with the Latent Space of GANs
Nov 28, 2022



In this work, we are dedicated to text-guided image generation and propose a novel framework, i.e., CLIP2GAN, by leveraging CLIP model and StyleGAN. The key idea of our CLIP2GAN is to bridge the output feature embedding space of CLIP and the input latent space of StyleGAN, which is realized by introducing a mapping network. In the training stage, we encode an image with CLIP and map the output feature to a latent code, which is further used to reconstruct the image. In this way, the mapping network is optimized in a self-supervised learning way. In the inference stage, since CLIP can embed both image and text into a shared feature embedding space, we replace CLIP image encoder in the training architecture with CLIP text encoder, while keeping the following mapping network as well as StyleGAN model. As a result, we can flexibly input a text description to generate an image. Moreover, by simply adding mapped text features of an attribute to a mapped CLIP image feature, we can effectively edit the attribute to the image. Extensive experiments demonstrate the superior performance of our proposed CLIP2GAN compared to previous methods.
SinDiffusion: Learning a Diffusion Model from a Single Natural Image
Nov 22, 2022We present SinDiffusion, leveraging denoising diffusion models to capture internal distribution of patches from a single natural image. SinDiffusion significantly improves the quality and diversity of generated samples compared with existing GAN-based approaches. It is based on two core designs. First, SinDiffusion is trained with a single model at a single scale instead of multiple models with progressive growing of scales which serves as the default setting in prior work. This avoids the accumulation of errors, which cause characteristic artifacts in generated results. Second, we identify that a patch-level receptive field of the diffusion network is crucial and effective for capturing the image's patch statistics, therefore we redesign the network structure of the diffusion model. Coupling these two designs enables us to generate photorealistic and diverse images from a single image. Furthermore, SinDiffusion can be applied to various applications, i.e., text-guided image generation, and image outpainting, due to the inherent capability of diffusion models. Extensive experiments on a wide range of images demonstrate the superiority of our proposed method for modeling the patch distribution.
Semantic Image Synthesis via Diffusion Models
Jun 30, 2022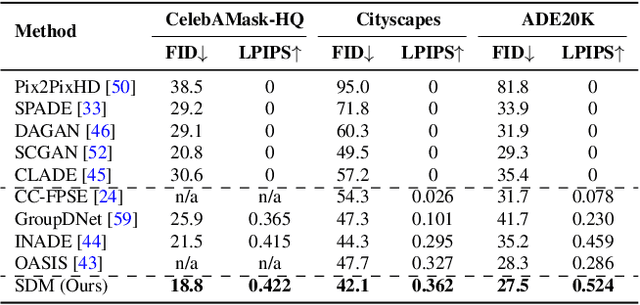
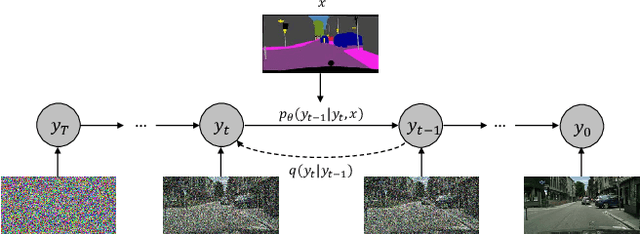
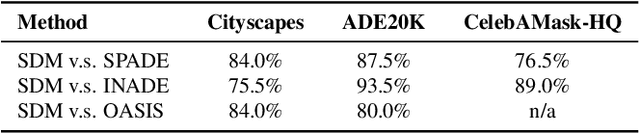
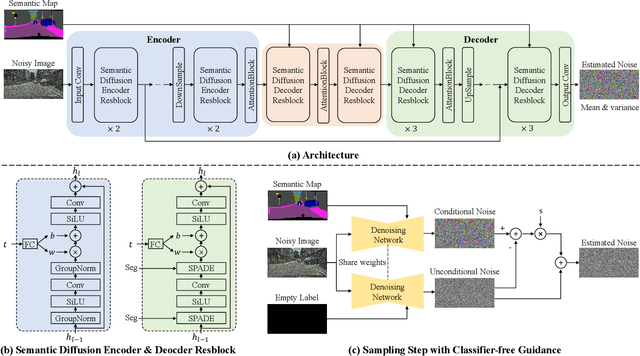
Denoising Diffusion Probabilistic Models (DDPMs) have achieved remarkable success in various image generation tasks compared with Generative Adversarial Nets (GANs). Recent work on semantic image synthesis mainly follows the \emph{de facto} GAN-based approaches, which may lead to unsatisfactory quality or diversity of generated images. In this paper, we propose a novel framework based on DDPM for semantic image synthesis. Unlike previous conditional diffusion model directly feeds the semantic layout and noisy image as input to a U-Net structure, which may not fully leverage the information in the input semantic mask, our framework processes semantic layout and noisy image differently. It feeds noisy image to the encoder of the U-Net structure while the semantic layout to the decoder by multi-layer spatially-adaptive normalization operators. To further improve the generation quality and semantic interpretability in semantic image synthesis, we introduce the classifier-free guidance sampling strategy, which acknowledge the scores of an unconditional model for sampling process. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our proposed method, achieving state-of-the-art performance in terms of fidelity~(FID) and diversity~(LPIPS).
Heredity-aware Child Face Image Generation with Latent Space Disentanglement
Aug 25, 2021



Generative adversarial networks have been widely used in image synthesis in recent years and the quality of the generated image has been greatly improved. However, the flexibility to control and decouple facial attributes (e.g., eyes, nose, mouth) is still limited. In this paper, we propose a novel approach, called ChildGAN, to generate a child's image according to the images of parents with heredity prior. The main idea is to disentangle the latent space of a pre-trained generation model and precisely control the face attributes of child images with clear semantics. We use distances between face landmarks as pseudo labels to figure out the most influential semantic vectors of the corresponding face attributes by calculating the gradient of latent vectors to pseudo labels. Furthermore, we disentangle the semantic vectors by weighting irrelevant features and orthogonalizing them with Schmidt Orthogonalization. Finally, we fuse the latent vector of the parents by leveraging the disentangled semantic vectors under the guidance of biological genetic laws. Extensive experiments demonstrate that our approach outperforms the existing methods with encouraging results.
Instance-wise Hard Negative Example Generation for Contrastive Learning in Unpaired Image-to-Image Translation
Aug 11, 2021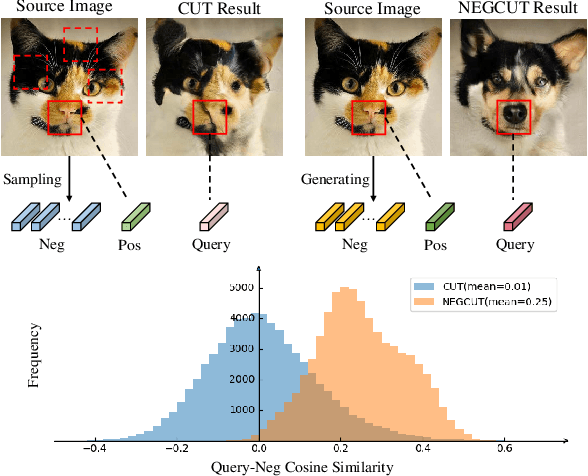
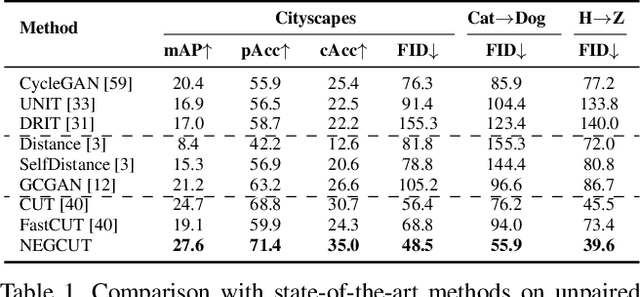
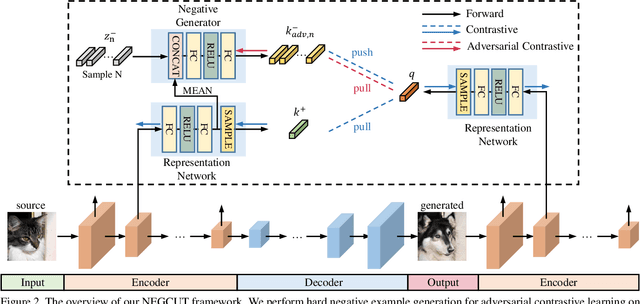
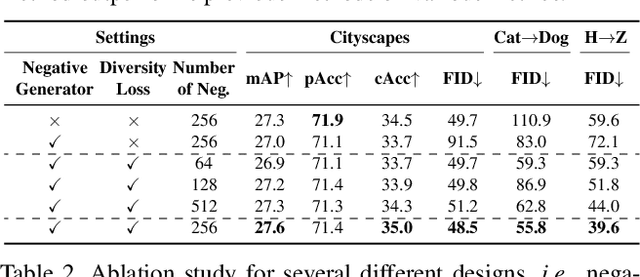
Contrastive learning shows great potential in unpaired image-to-image translation, but sometimes the translated results are in poor quality and the contents are not preserved consistently. In this paper, we uncover that the negative examples play a critical role in the performance of contrastive learning for image translation. The negative examples in previous methods are randomly sampled from the patches of different positions in the source image, which are not effective to push the positive examples close to the query examples. To address this issue, we present instance-wise hard Negative Example Generation for Contrastive learning in Unpaired image-to-image Translation (NEGCUT). Specifically, we train a generator to produce negative examples online. The generator is novel from two perspectives: 1) it is instance-wise which means that the generated examples are based on the input image, and 2) it can generate hard negative examples since it is trained with an adversarial loss. With the generator, the performance of unpaired image-to-image translation is significantly improved. Experiments on three benchmark datasets demonstrate that the proposed NEGCUT framework achieves state-of-the-art performance compared to previous methods.