 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiEV: The Tongji Intelligent Electric Vehicle in the Intelligent Vehicle Future Challenge of China
May 07, 2018
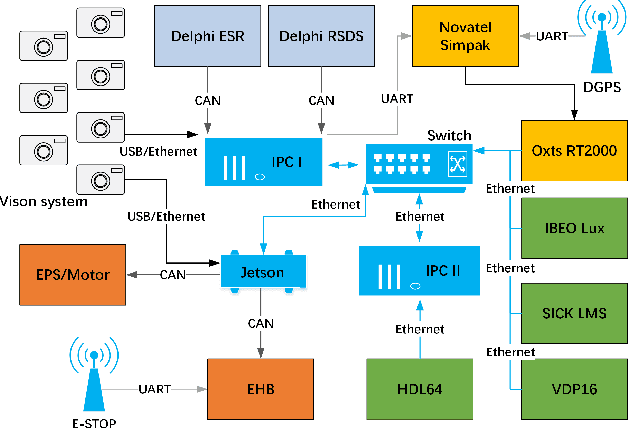
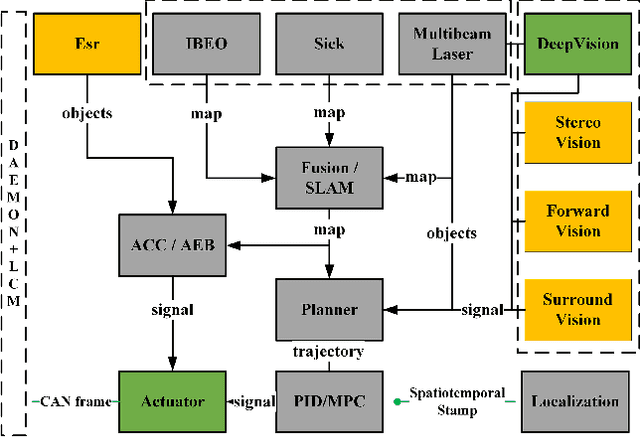
TiEV is an autonomous driving platform implemented by Tongji University of China. The vehicle is drive-by-wire and is fully powered by electricity. We devised the software system of TiEV from scratch, which is capable of driving the vehicle autonomously in urban paths as well as on fast express roads. We describe our whole system, especially novel modules of probabilistic perception fusion, incremental mapping, the 1st and the 2nd planning and the overall safety concern. TiEV finished 2016 and 2017 Intelligent Vehicle Future Challenge of China held at Changshu. We show our experiences on the development of autonomous vehicles and future trends.
VH-HFCN based Parking Slot and Lane Markings Segmentation on Panoramic Surround View
May 07, 2018


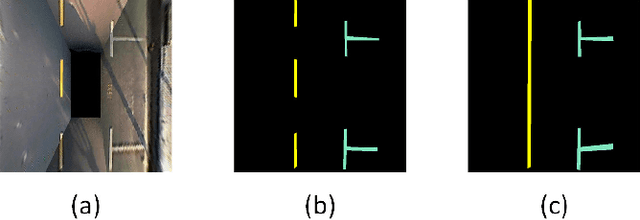
The automatic parking is being massively developed by car manufacturers and providers. Until now, there are two problems with the automatic parking. First, there is no openly-available segmentation labels of parking slot on panoramic surround view (PSV) dataset. Second, how to detect parking slot and road structure robustly. Therefore, in this paper, we build up a public PSV dataset. At the same time, we proposed a highly fused convolutional network (HFCN) based segmentation method for parking slot and lane markings based on the PSV dataset. A surround-view image is made of four calibrated images captured from four fisheye cameras. We collect and label more than 4,200 surround view images for this task, which contain various illuminated scenes of different types of parking slots. A VH-HFCN network is proposed, which adopts an HFCN as the base, with an extra efficient VH-stage for better segmenting various markings. The VH-stage consists of two independent linear convolution paths with vertical and horizontal convolution kernels respectively. This modification enables the network to robustly and precisely extract linear features. We evaluated our model on the PSV dataset and the results showed outstanding performance in ground markings segmentation. Based on the segmented markings, parking slots and lanes are acquired by skeletonization, hough line transform and line arrangement.
Semantic Segmentation via Highly Fused Convolutional Network with Multiple Soft Cost Functions
Jan 04, 2018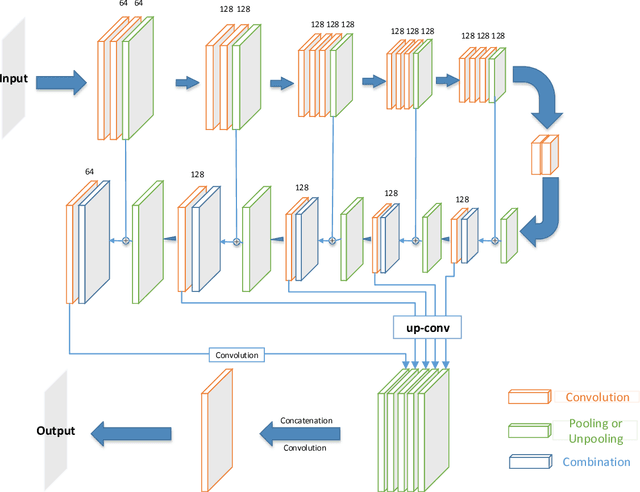
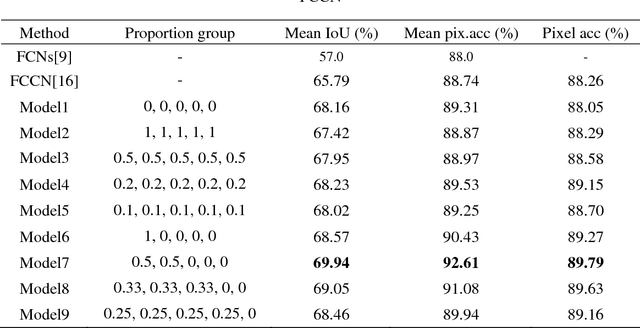
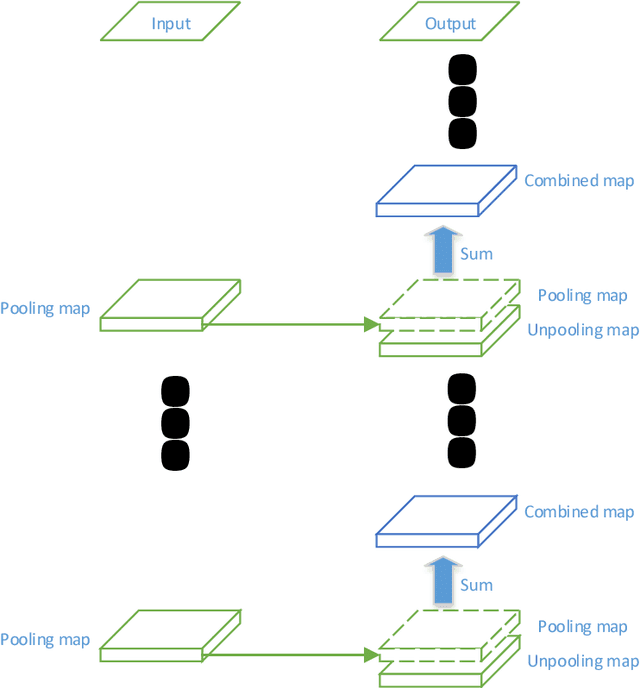
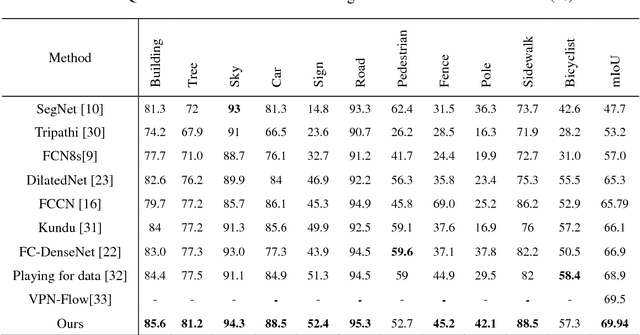
Semantic image segmentation is one of the most challenged tasks in computer vision. In this paper, we propose a highly fused convolutional network, which consists of three parts: feature downsampling, combined feature upsampling and multiple predictions. We adopt a strategy of multiple steps of upsampling and combined feature maps in pooling layers with its corresponding unpooling layers. Then we bring out multiple pre-outputs, each pre-output is generated from an unpooling layer by one-step upsampling. Finally, we concatenate these pre-outputs to get the final output. As a result, our proposed network makes highly use of the feature information by fusing and reusing feature maps. In addition, when training our model, we add multiple soft cost functions on pre-outputs and final outputs. In this way, we can reduce the loss reduction when the loss is back propagated. We evaluate our model on three major segmentation datasets: CamVid, PASCAL VOC and ADE20K. We achieve a state-of-the-art performance on CamVid dataset, as well as considerable improvements on PASCAL VOC dataset and ADE20K dataset