 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
May 15, 2024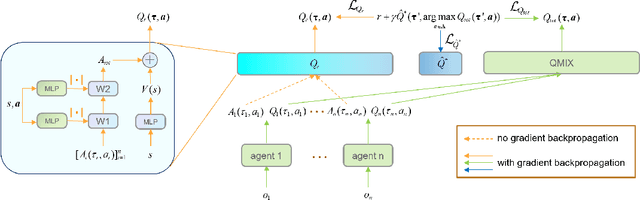
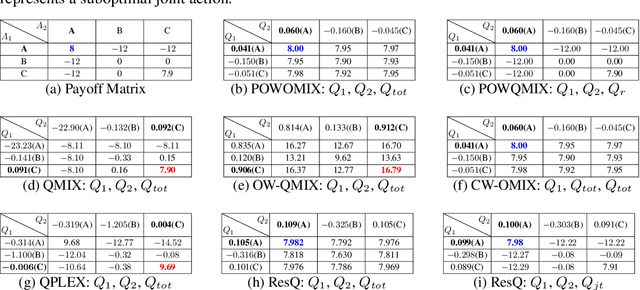
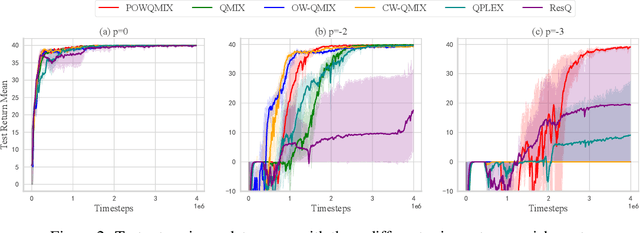
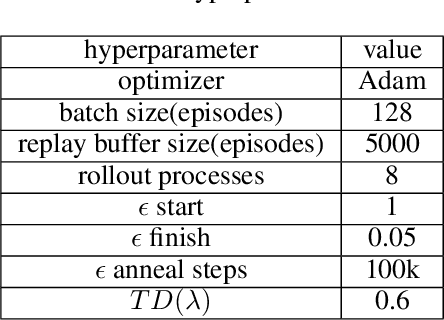
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal joint actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.
How to Fine-tune the Model: Unified Model Shift and Model Bias Policy Optimization
Sep 22, 2023



Designing and deriving effective model-based reinforcement learning (MBRL) algorithms with a performance improvement guarantee is challenging, mainly attributed to the high coupling between model learning and policy optimization. Many prior methods that rely on return discrepancy to guide model learning ignore the impacts of model shift, which can lead to performance deterioration due to excessive model updates. Other methods use performance difference bound to explicitly consider model shift. However, these methods rely on a fixed threshold to constrain model shift, resulting in a heavy dependence on the threshold and a lack of adaptability during the training process. In this paper, we theoretically derive an optimization objective that can unify model shift and model bias and then formulate a fine-tuning process. This process adaptively adjusts the model updates to get a performance improvement guarantee while avoiding model overfitting. Based on these, we develop a straightforward algorithm USB-PO (Unified model Shift and model Bias Policy Optimization). Empirical results show that USB-PO achieves state-of-the-art performance on several challenging benchmark tasks.
Safe Reinforcement Learning with Dead-Ends Avoidance and Recovery
Jun 24, 2023



Safety is one of the main challenges in applying reinforcement learning to realistic environmental tasks. To ensure safety during and after training process, existing methods tend to adopt overly conservative policy to avoid unsafe situations. However, overly conservative policy severely hinders the exploration, and makes the algorithms substantially less rewarding. In this paper, we propose a method to construct a boundary that discriminates safe and unsafe states. The boundary we construct is equivalent to distinguishing dead-end states, indicating the maximum extent to which safe exploration is guaranteed, and thus has minimum limitation on exploration. Similar to Recovery Reinforcement Learning, we utilize a decoupled RL framework to learn two policies, (1) a task policy that only considers improving the task performance, and (2) a recovery policy that maximizes safety. The recovery policy and a corresponding safety critic are pretrained on an offline dataset, in which the safety critic evaluates upper bound of safety in each state as awareness of environmental safety for the agent. During online training, a behavior correction mechanism is adopted, ensuring the agent to interact with the environment using safe actions only. Finally, experiments of continuous control tasks demonstrate that our approach has better task performance with less safety violations than state-of-the-art algorithms.
Real-time Multi-target Path Prediction and Planning for Autonomous Driving aided by FCN
Sep 17, 2019
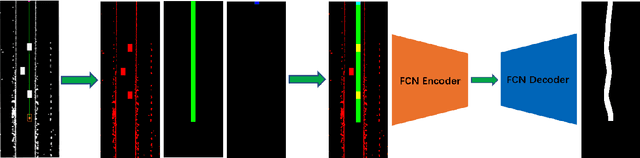
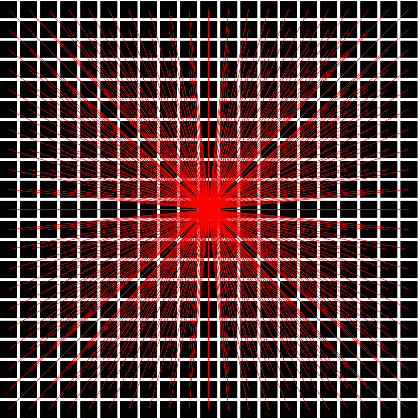
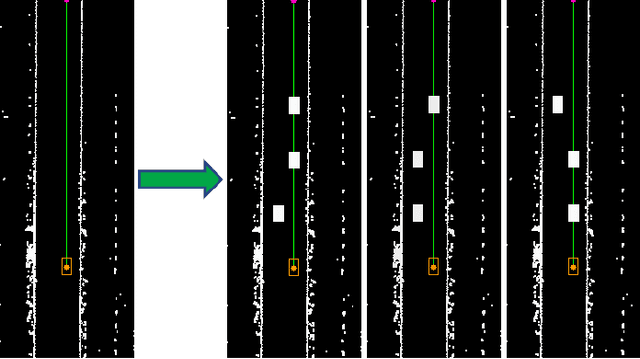
Real-time multi-target path planning is a key issue in the field of autonomous driving. Although multiple paths can be generated in real-time with polynomial curves, the generated paths are not flexible enough to deal with complex road scenes such as S-shaped road and unstructured scenes such as parking lots. Search and sampling-based methods, such as A* and RRT and their derived methods, are flexible in generating paths for these complex road environments. However, the existing algorithms require significant time to plan to multiple targets, which greatly limits their application in autonomous driving. In this paper, a real-time path planning method for multi-targets is proposed. We train a fully convolutional neural network (FCN) to predict a path region for the target at first. By taking the predicted path region as soft constraints, the A* algorithm is then applied to search the exact path to the target. Experiments show that FCN can make multiple predictions in a very short time (50 times in 40ms), and the predicted path region effectively restrict the searching space for the following A* search. Therefore, the A* can search much faster so that the multi-target path planning can be achieved in real-time (3 targets in less than 100ms).