 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
May 15, 2024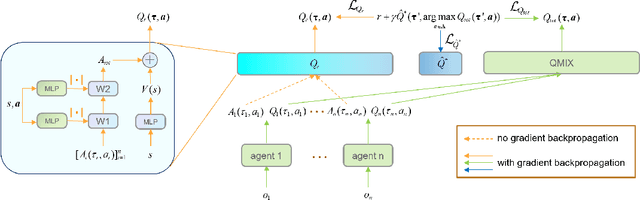
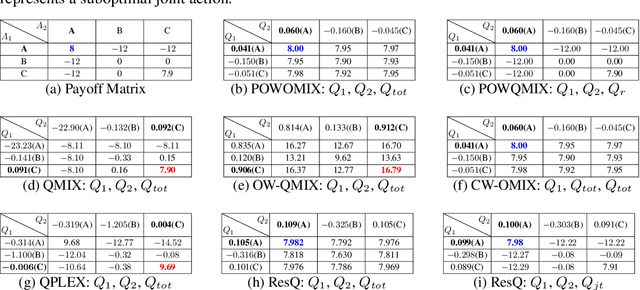
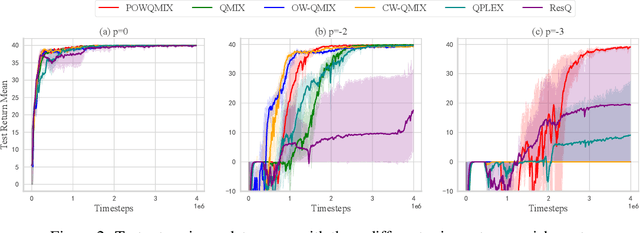
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal joint actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.
Towards an Information Theoretic Framework of Context-Based Offline Meta-Reinforcement Learning
Feb 04, 2024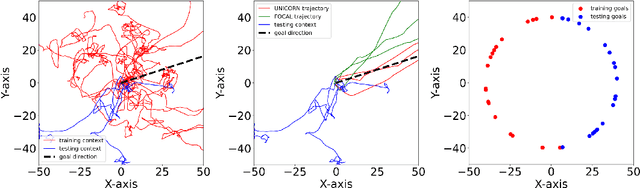

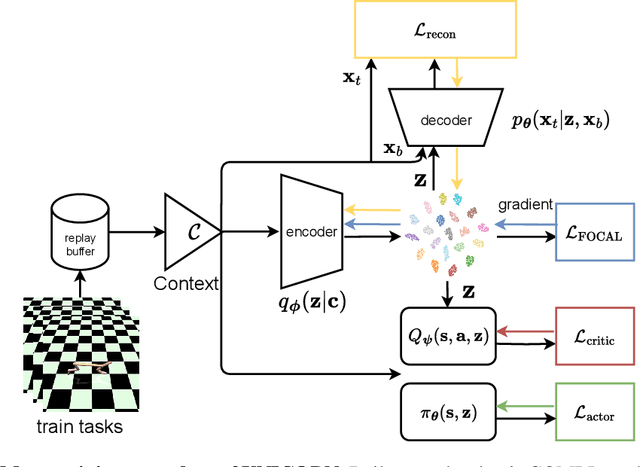
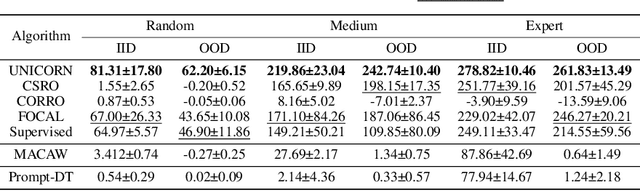
As a marriage between offline RL and meta-RL, the advent of offline meta-reinforcement learning (OMRL) has shown great promise in enabling RL agents to multi-task and quickly adapt while acquiring knowledge safely. Among which, Context-based OMRL (COMRL) as a popular paradigm, aims to learn a universal policy conditioned on effective task representations. In this work, by examining several key milestones in the field of COMRL, we propose to integrate these seemingly independent methodologies into a unified information theoretic framework. Most importantly, we show that the pre-existing COMRL algorithms are essentially optimizing the same mutual information objective between the task variable $\boldsymbol{M}$ and its latent representation $\boldsymbol{Z}$ by implementing various approximate bounds. Based on the theoretical insight and the information bottleneck principle, we arrive at a novel algorithm dubbed UNICORN, which exhibits remarkable generalization across a broad spectrum of RL benchmarks, context shift scenarios, data qualities and deep learning architectures, attaining the new state-of-the-art. We believe that our framework could open up avenues for new optimality bounds and COMRL algorithms.