 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSurgSAM2: Referring Segment Anything in Surgical Video via Credible Long-term Tracking
May 13, 2025Surgical scene segmentation is critical in computer-assisted surgery and is vital for enhancing surgical quality and patient outcomes. Recently, referring surgical segmentation is emerging, given its advantage of providing surgeons with an interactive experience to segment the target object. However, existing methods are limited by low efficiency and short-term tracking, hindering their applicability in complex real-world surgical scenarios. In this paper, we introduce ReSurgSAM2, a two-stage surgical referring segmentation framework that leverages Segment Anything Model 2 to perform text-referred target detection, followed by tracking with reliable initial frame identification and diversity-driven long-term memory. For the detection stage, we propose a cross-modal spatial-temporal Mamba to generate precise detection and segmentation results. Based on these results, our credible initial frame selection strategy identifies the reliable frame for the subsequent tracking. Upon selecting the initial frame, our method transitions to the tracking stage, where it incorporates a diversity-driven memory mechanism that maintains a credible and diverse memory bank, ensuring consistent long-term tracking. Extensive experiments demonstrate that ReSurgSAM2 achieves substantial improvements in accuracy and efficiency compared to existing methods, operating in real-time at 61.2 FPS. Our code and datasets will be available at https://github.com/jinlab-imvr/ReSurgSAM2.
Gamma: Toward Generic Image Assessment with Mixture of Assessment Experts
Mar 09, 2025

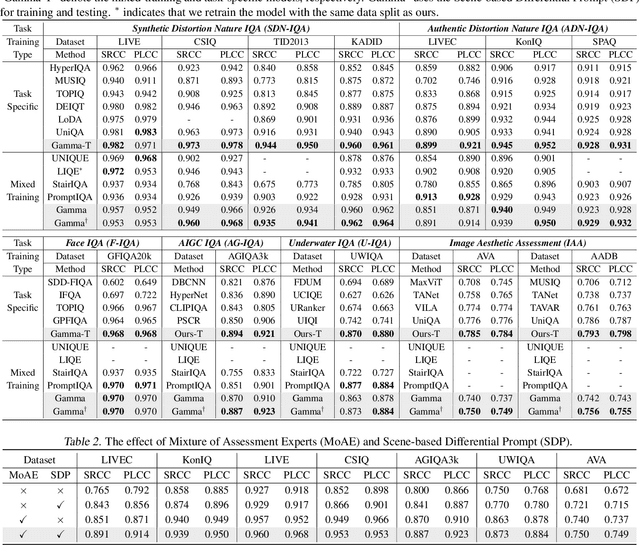

Image assessment aims to evaluate the quality and aesthetics of images and has been applied across various scenarios, such as natural and AIGC scenes. Existing methods mostly address these sub-tasks or scenes individually. While some works attempt to develop unified image assessment models, they have struggled to achieve satisfactory performance or cover a broad spectrum of assessment scenarios. In this paper, we present \textbf{Gamma}, a \textbf{G}eneric im\textbf{A}ge assess\textbf{M}ent model using \textbf{M}ixture of \textbf{A}ssessment Experts, which can effectively assess images from diverse scenes through mixed-dataset training. Achieving unified training in image assessment presents significant challenges due to annotation biases across different datasets. To address this issue, we first propose a Mixture of Assessment Experts (MoAE) module, which employs shared and adaptive experts to dynamically learn common and specific knowledge for different datasets, respectively. In addition, we introduce a Scene-based Differential Prompt (SDP) strategy, which uses scene-specific prompts to provide prior knowledge and guidance during the learning process, further boosting adaptation for various scenes. Our Gamma model is trained and evaluated on 12 datasets spanning 6 image assessment scenarios. Extensive experiments show that our unified Gamma outperforms other state-of-the-art mixed-training methods by significant margins while covering more scenes. Code: https://github.com/zht8506/Gamma.
UniQA: Unified Vision-Language Pre-training for Image Quality and Aesthetic Assessment
Jun 03, 2024

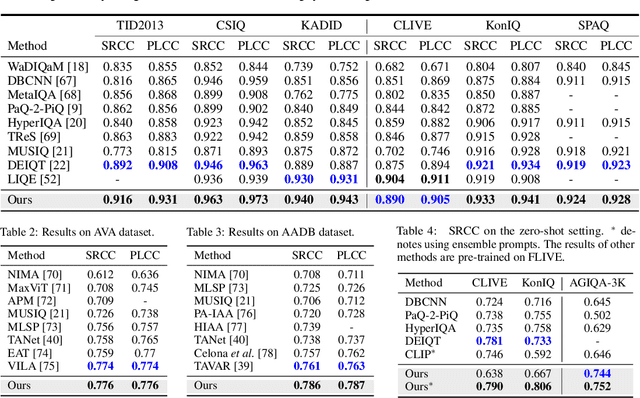

Image Quality Assessment (IQA) and Image Aesthetic Assessment (IAA) aim to simulate human subjective perception of image visual quality and aesthetic appeal. Existing methods typically address these tasks independently due to distinct learning objectives. However, they neglect the underlying interconnectedness of both tasks, which hinders the learning of task-agnostic shared representations for human subjective perception. To confront this challenge, we propose Unified vision-language pre-training of Quality and Aesthetics (UniQA), to learn general perceptions of two tasks, thereby benefiting them simultaneously. Addressing the absence of text in the IQA datasets and the presence of textual noise in the IAA datasets, (1) we utilize multimodal large language models (MLLMs) to generate high-quality text descriptions; (2) the generated text for IAA serves as metadata to purify noisy IAA data. To effectively adapt the pre-trained UniQA to downstream tasks, we further propose a lightweight adapter that utilizes versatile cues to fully exploit the extensive knowledge of the pre-trained model. Extensive experiments demonstrate that our approach attains a new state-of-the-art performance on both IQA and IAA tasks, while concurrently showcasing exceptional zero-shot and few-label image assessment capabilities. The source code will be available at https://github.com/zht8506/UniQA.
Data-Efficient Image Quality Assessment with Attention-Panel Decoder
Apr 11, 2023Blind Image Quality Assessment (BIQA) is a fundamental task in computer vision, which however remains unresolved due to the complex distortion conditions and diversified image contents. To confront this challenge, we in this paper propose a novel BIQA pipeline based on the Transformer architecture, which achieves an efficient quality-aware feature representation with much fewer data. More specifically, we consider the traditional fine-tuning in BIQA as an interpretation of the pre-trained model. In this way, we further introduce a Transformer decoder to refine the perceptual information of the CLS token from different perspectives. This enables our model to establish the quality-aware feature manifold efficiently while attaining a strong generalization capability. Meanwhile, inspired by the subjective evaluation behaviors of human, we introduce a novel attention panel mechanism, which improves the model performance and reduces the prediction uncertainty simultaneously. The proposed BIQA method maintains a lightweight design with only one layer of the decoder, yet extensive experiments on eight standard BIQA datasets (both synthetic and authentic) demonstrate its superior performance to the state-of-the-art BIQA methods, i.e., achieving the SRCC values of 0.875 (vs. 0.859 in LIVEC) and 0.980 (vs. 0.969 in LIVE).