 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Practical Learned Image Compression
May 06, 2026One of the major differentiators unlocked by learned codecs relative to their hard-coded traditional counterparts is their ability to be optimized directly to appeal to the human visual system. Despite this potential, a perceptual yet practical image codec is yet to be proposed. In this work, we aim to close this gap. We conduct a comprehensive study of the key modeling choices that govern the design of a practical learned image codec, jointly optimized for perceptual quality and runtime -- including within the ablations several novel techniques. We then perform performance-aware neural architecture search over millions of backbone configurations to identify models that achieve the target on-device runtime while maximizing compression performance as captured by perceptual metrics. We combine the various optimizations to construct a new codec that achieves a significantly improved tradeoff between speed and perceptual quality. Based on rigorous subjective user studies, it provides 2.3-3x bitrate savings against AV1, AV2, VVC, ECM and JPEG-AI, and 20-40% bitrate savings against the best learned codec alternatives. At the same time, on an iPhone 17 Pro Max, it encodes 12MP images as fast as 230ms, and decodes them in 150ms -- faster than most top ML-based codecs run on a V100 GPU.
Segment Concealed Objects with Incomplete Supervision
Jun 10, 2025Incompletely-Supervised Concealed Object Segmentation (ISCOS) involves segmenting objects that seamlessly blend into their surrounding environments, utilizing incompletely annotated data, such as weak and semi-annotations, for model training. This task remains highly challenging due to (1) the limited supervision provided by the incompletely annotated training data, and (2) the difficulty of distinguishing concealed objects from the background, which arises from the intrinsic similarities in concealed scenarios. In this paper, we introduce the first unified method for ISCOS to address these challenges. To tackle the issue of incomplete supervision, we propose a unified mean-teacher framework, SEE, that leverages the vision foundation model, ``\emph{Segment Anything Model (SAM)}'', to generate pseudo-labels using coarse masks produced by the teacher model as prompts. To mitigate the effect of low-quality segmentation masks, we introduce a series of strategies for pseudo-label generation, storage, and supervision. These strategies aim to produce informative pseudo-labels, store the best pseudo-labels generated, and select the most reliable components to guide the student model, thereby ensuring robust network training. Additionally, to tackle the issue of intrinsic similarity, we design a hybrid-granularity feature grouping module that groups features at different granularities and aggregates these results. By clustering similar features, this module promotes segmentation coherence, facilitating more complete segmentation for both single-object and multiple-object images. We validate the effectiveness of our approach across multiple ISCOS tasks, and experimental results demonstrate that our method achieves state-of-the-art performance. Furthermore, SEE can serve as a plug-and-play solution, enhancing the performance of existing models.
* IEEE TPAMI
A Survey of Camouflaged Object Detection and Beyond
Aug 26, 2024Camouflaged Object Detection (COD) refers to the task of identifying and segmenting objects that blend seamlessly into their surroundings, posing a significant challenge for computer vision systems. In recent years, COD has garnered widespread attention due to its potential applications in surveillance, wildlife conservation, autonomous systems, and more. While several surveys on COD exist, they often have limitations in terms of the number and scope of papers covered, particularly regarding the rapid advancements made in the field since mid-2023. To address this void, we present the most comprehensive review of COD to date, encompassing both theoretical frameworks and practical contributions to the field. This paper explores various COD methods across four domains, including both image-level and video-level solutions, from the perspectives of traditional and deep learning approaches. We thoroughly investigate the correlations between COD and other camouflaged scenario methods, thereby laying the theoretical foundation for subsequent analyses. Beyond object-level detection, we also summarize extended methods for instance-level tasks, including camouflaged instance segmentation, counting, and ranking. Additionally, we provide an overview of commonly used benchmarks and evaluation metrics in COD tasks, conducting a comprehensive evaluation of deep learning-based techniques in both image and video domains, considering both qualitative and quantitative performance. Finally, we discuss the limitations of current COD models and propose 9 promising directions for future research, focusing on addressing inherent challenges and exploring novel, meaningful technologies. For those interested, a curated list of COD-related techniques, datasets, and additional resources can be found at https://github.com/ChunmingHe/awesome-concealed-object-segmentation
Spatial Coherence Loss for Salient and Camouflaged Object Detection and Beyond
Feb 28, 2024
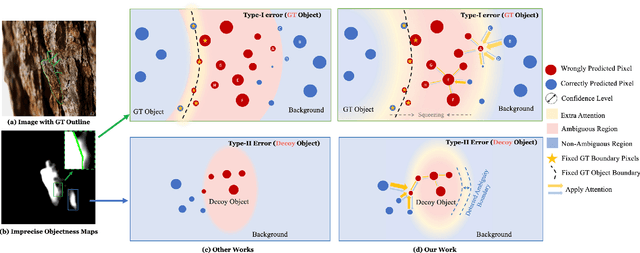


Generic object detection is a category-independent task that relies on accurate modeling of objectness. Most relevant CNN-based models of objectness utilize loss functions (e.g., binary cross entropy) that focus on the single-response, i.e., the loss response of a single pixel. Inspired by the human visual system, which first discerns the boundaries of ambiguous regions (i.e., hard regions) before delving into the semantic meaning, we propose a novel loss function, Spatial Coherence Loss (SCLoss), that uses the mutual response between adjacent pixels to suppress or emphasize the single-response of pixels. We demonstrate that the proposed SCLoss can gradually learn the hard regions by detecting and emphasizing their boundaries. Through comprehensive experiments, we demonstrate that replacing popular loss functions with SCLoss can improve the performance of current state-of-the-art (SOTA) salient or camouflaged object detection (SOD or COD) models. We also demonstrate that combining SCLoss with other loss functions can further improve performance and result in the SOTA outcomes for different applications. Finally, as a demonstrative example of the potential uses for other related tasks, we show an application of SCLoss for semantic segmentation.
Directional Connectivity-based Segmentation of Medical Images
Mar 31, 2023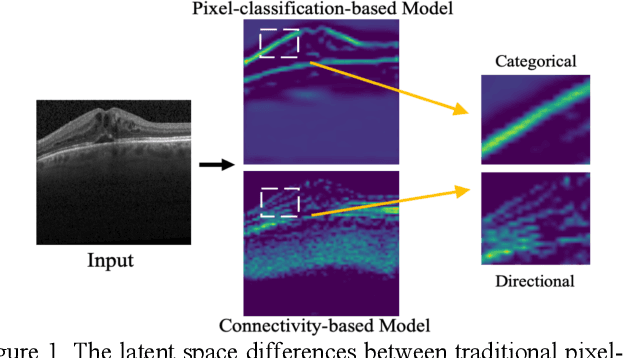



Anatomical consistency in biomarker segmentation is crucial for many medical image analysis tasks. A promising paradigm for achieving anatomically consistent segmentation via deep networks is incorporating pixel connectivity, a basic concept in digital topology, to model inter-pixel relationships. However, previous works on connectivity modeling have ignored the rich channel-wise directional information in the latent space. In this work, we demonstrate that effective disentanglement of directional sub-space from the shared latent space can significantly enhance the feature representation in the connectivity-based network. To this end, we propose a directional connectivity modeling scheme for segmentation that decouples, tracks, and utilizes the directional information across the network. Experiments on various public medical image segmentation benchmarks show the effectiveness of our model as compared to the state-of-the-art methods. Code is available at https://github.com/Zyun-Y/DconnNet.
RetiFluidNet: A Self-Adaptive and Multi-Attention Deep Convolutional Network for Retinal OCT Fluid Segmentation
Sep 26, 2022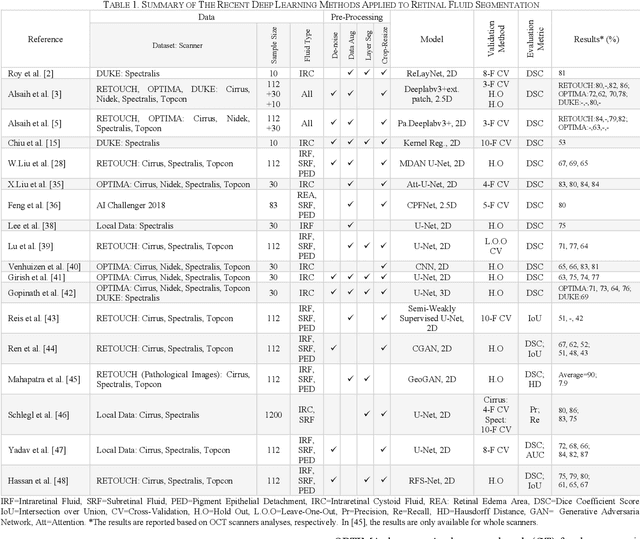
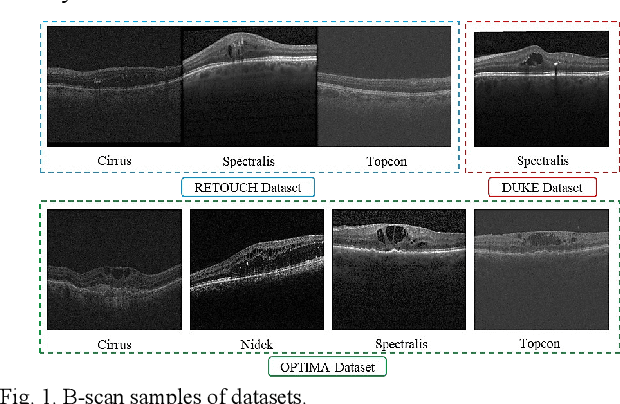
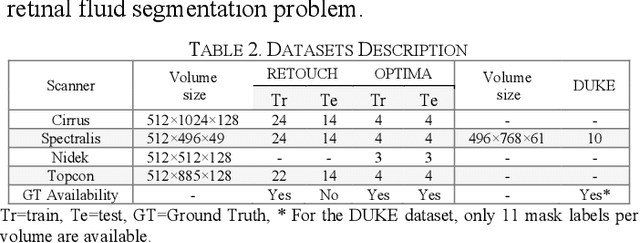

Optical coherence tomography (OCT) helps ophthalmologists assess macular edema, accumulation of fluids, and lesions at microscopic resolution. Quantification of retinal fluids is necessary for OCT-guided treatment management, which relies on a precise image segmentation step. As manual analysis of retinal fluids is a time-consuming, subjective, and error-prone task, there is increasing demand for fast and robust automatic solutions. In this study, a new convolutional neural architecture named RetiFluidNet is proposed for multi-class retinal fluid segmentation. The model benefits from hierarchical representation learning of textural, contextual, and edge features using a new self-adaptive dual-attention (SDA) module, multiple self-adaptive attention-based skip connections (SASC), and a novel multi-scale deep self supervision learning (DSL) scheme. The attention mechanism in the proposed SDA module enables the model to automatically extract deformation-aware representations at different levels, and the introduced SASC paths further consider spatial-channel interdependencies for concatenation of counterpart encoder and decoder units, which improve representational capability. RetiFluidNet is also optimized using a joint loss function comprising a weighted version of dice overlap and edge-preserved connectivity-based losses, where several hierarchical stages of multi-scale local losses are integrated into the optimization process. The model is validated based on three publicly available datasets: RETOUCH, OPTIMA, and DUKE, with comparisons against several baselines. Experimental results on the datasets prove the effectiveness of the proposed model in retinal OCT fluid segmentation and reveal that the suggested method is more effective than existing state-of-the-art fluid segmentation algorithms in adapting to retinal OCT scans recorded by various image scanning instruments.
BiconNet: An Edge-preserved Connectivity-based Approach for Salient Object Detection
Feb 27, 2021
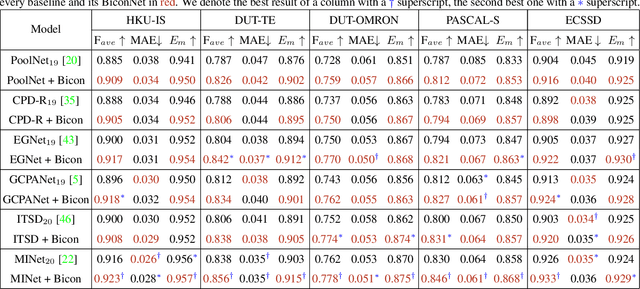
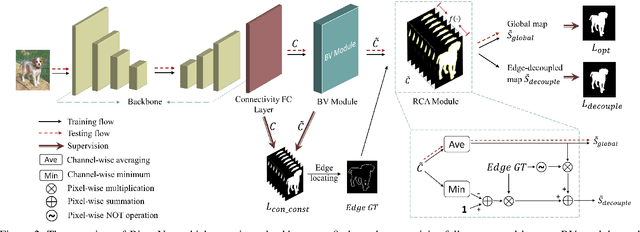
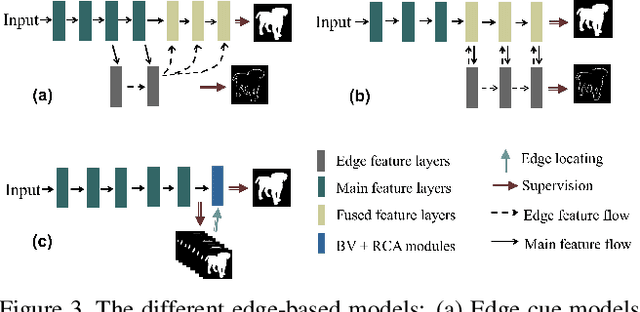
Salient object detection (SOD) is viewed as a pixel-wise saliency modeling task by traditional deep learning-based methods. Although great progress has been made, a challenge of modern SOD models is the insufficient utilization of inter-pixel information, which usually results in imperfect segmentations near the edge regions. As we demonstrate, using a saliency map as the network output is a sub-optimal choice. To address this problem, we propose a connectivity-based approach named bilateral connectivity network (BiconNet), which uses a connectivity map instead of a saliency map as the network output for effective modeling of inter-pixel relationships and object saliency. Moreover, we propose a bilateral voting module to enhance the output connectivity map and a novel edge feature enhancement method that efficiently utilizes edge-specific features with negligible parameter increase. We show that our model can use any existing saliency-based SOD framework as its backbone. Through comprehensive experiments on five benchmark datasets, we demonstrate that our proposed method outperforms state-of-the-art SOD approaches.
Multimodal Densenet
Nov 18, 2018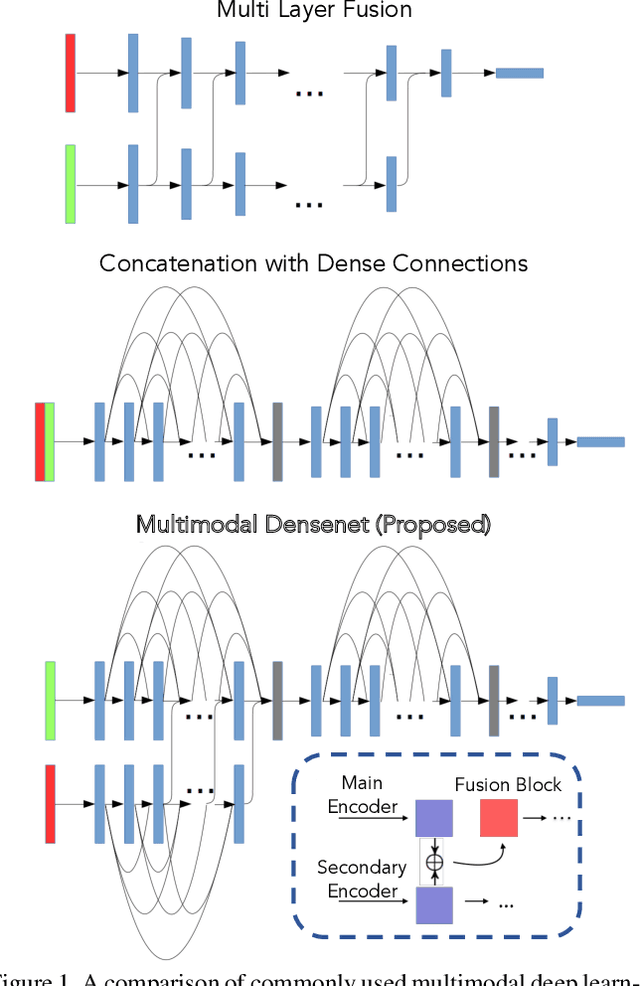


Humans make accurate decisions by interpreting complex data from multiple sources. Medical diagnostics, in particular, often hinge on human interpretation of multi-modal information. In order for artificial intelligence to make progress in automated, objective, and accurate diagnosis and prognosis, methods to fuse information from multiple medical imaging modalities are required. However, combining information from multiple data sources has several challenges, as current deep learning architectures lack the ability to extract useful representations from multimodal information, and often simple concatenation is used to fuse such information. In this work, we propose Multimodal DenseNet, a novel architecture for fusing multimodal data. Instead of focusing on concatenation or early and late fusion, our proposed architectures fuses information over several layers and gives the model flexibility in how it combines information from multiple sources. We apply this architecture to the challenge of polyp characterization and landmark identification in endoscopy. Features from white light images are fused with features from narrow band imaging or depth maps. This study demonstrates that Multimodal DenseNet outperforms monomodal classification as well as other multimodal fusion techniques by a significant margin on two different datasets.