 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Coherence Loss for Salient and Camouflaged Object Detection and Beyond
Paper and Code
Feb 28, 2024
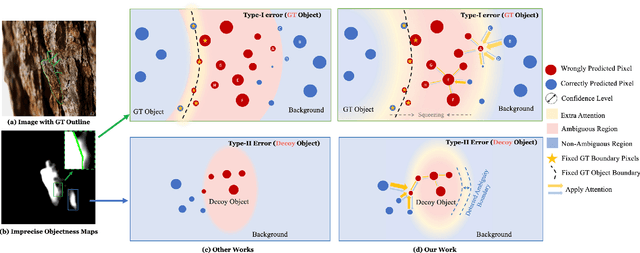


Generic object detection is a category-independent task that relies on accurate modeling of objectness. Most relevant CNN-based models of objectness utilize loss functions (e.g., binary cross entropy) that focus on the single-response, i.e., the loss response of a single pixel. Inspired by the human visual system, which first discerns the boundaries of ambiguous regions (i.e., hard regions) before delving into the semantic meaning, we propose a novel loss function, Spatial Coherence Loss (SCLoss), that uses the mutual response between adjacent pixels to suppress or emphasize the single-response of pixels. We demonstrate that the proposed SCLoss can gradually learn the hard regions by detecting and emphasizing their boundaries. Through comprehensive experiments, we demonstrate that replacing popular loss functions with SCLoss can improve the performance of current state-of-the-art (SOTA) salient or camouflaged object detection (SOD or COD) models. We also demonstrate that combining SCLoss with other loss functions can further improve performance and result in the SOTA outcomes for different applications. Finally, as a demonstrative example of the potential uses for other related tasks, we show an application of SCLoss for semantic segmentation.